 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Pretraining of Large Mixture of Experts Language Models on Aurora Super Computer
Apr 01, 2026Pretraining Large Language Models (LLMs) from scratch requires massive amount of compute. Aurora super computer is an ExaScale machine with 127,488 Intel PVC (Ponte Vechio) GPU tiles. In this work, we showcase LLM pretraining on Aurora at the scale of 1000s of GPU tiles. Towards this effort, we developed Optimus, an inhouse training library with support for standard large model training techniques. Using Optimus, we first pretrained Mula-1B, a 1 Billion dense model and Mula-7B-A1B, a 7 Billion Mixture of Experts (MoE) model from scratch on 3072 GPU tiles for the full 4 trillion tokens of the OLMoE-mix-0924 dataset. We then demonstrated model scaling by pretraining three large MoE models Mula-20B-A2B, Mula-100B-A7B, and Mula-220B-A10B till 100 Billion tokens on the same dataset. On our largest model Mula-220B-A10B, we pushed the compute scaling from 384 to 12288 GPU tiles and observed scaling efficiency of around 90% at 12288 GPU tiles. We significantly improved the runtime performance of MoE models using custom GPU kernels for expert computation, and a novel EP-Aware sharded optimizer resulting in training speedups up to 1.71x. As part of the Optimus library, we also developed a robust set of reliability and fault tolerant features to improve training stability and continuity at scale.
Generative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
AUTOSPARSE: Towards Automated Sparse Training of Deep Neural Networks
Apr 14, 2023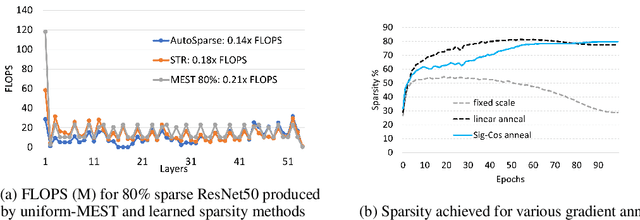
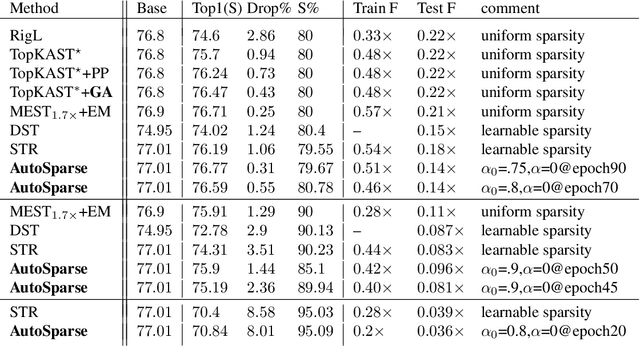

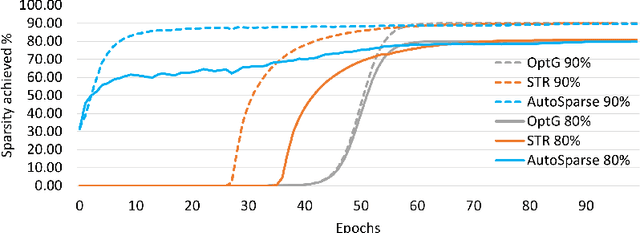
Sparse training is emerging as a promising avenue for reducing the computational cost of training neural networks. Several recent studies have proposed pruning methods using learnable thresholds to efficiently explore the non-uniform distribution of sparsity inherent within the models. In this paper, we propose Gradient Annealing (GA), where gradients of masked weights are scaled down in a non-linear manner. GA provides an elegant trade-off between sparsity and accuracy without the need for additional sparsity-inducing regularization. We integrated GA with the latest learnable pruning methods to create an automated sparse training algorithm called AutoSparse, which achieves better accuracy and/or training/inference FLOPS reduction than existing learnable pruning methods for sparse ResNet50 and MobileNetV1 on ImageNet-1K: AutoSparse achieves (2x, 7x) reduction in (training,inference) FLOPS for ResNet50 on ImageNet at 80% sparsity. Finally, AutoSparse outperforms sparse-to-sparse SotA method MEST (uniform sparsity) for 80% sparse ResNet50 with similar accuracy, where MEST uses 12% more training FLOPS and 50% more inference FLOPS.
Efficient and Generic 1D Dilated Convolution Layer for Deep Learning
Apr 16, 2021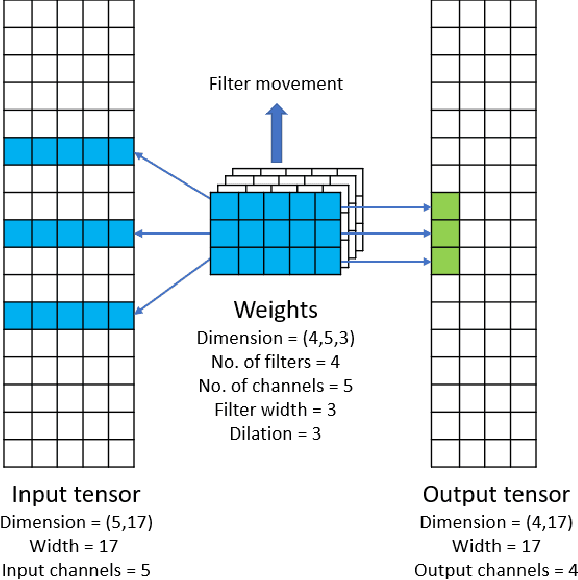
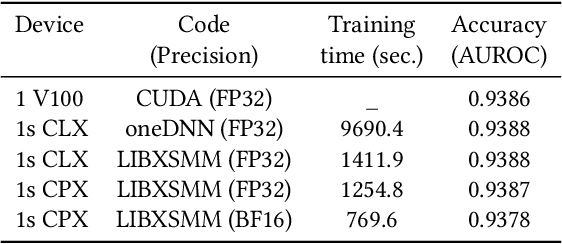
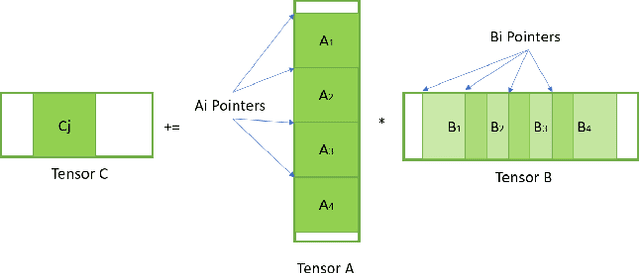
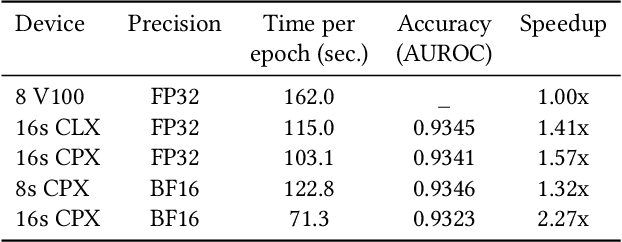
Convolutional neural networks (CNNs) have found many applications in tasks involving two-dimensional (2D) data, such as image classification and image processing. Therefore, 2D convolution layers have been heavily optimized on CPUs and GPUs. However, in many applications - for example genomics and speech recognition, the data can be one-dimensional (1D). Such applications can benefit from optimized 1D convolution layers. In this work, we introduce our efficient implementation of a generic 1D convolution layer covering a wide range of parameters. It is optimized for x86 CPU architectures, in particular, for architectures containing Intel AVX-512 and AVX-512 BFloat16 instructions. We use the LIBXSMM library's batch-reduce General Matrix Multiplication (BRGEMM) kernel for FP32 and BFloat16 precision. We demonstrate that our implementation can achieve up to 80% efficiency on Intel Xeon Cascade Lake and Cooper Lake CPUs. Additionally, we show the generalization capability of our BRGEMM based approach by achieving high efficiency across a range of parameters. We consistently achieve higher efficiency than the 1D convolution layer with Intel oneDNN library backend for varying input tensor widths, filter widths, number of channels, filters, and dilation parameters. Finally, we demonstrate the performance of our optimized 1D convolution layer by utilizing it in the end-to-end neural network training with real genomics datasets and achieve up to 6.86x speedup over the oneDNN library-based implementation on Cascade Lake CPUs. We also demonstrate the scaling with 16 sockets of Cascade/Cooper Lake CPUs and achieve significant speedup over eight V100 GPUs using a similar power envelop. In the end-to-end training, we get a speedup of 1.41x on Cascade Lake with FP32, 1.57x on Cooper Lake with FP32, and 2.27x on Cooper Lake with BFloat16 over eight V100 GPUs with FP32.
MADRaS : Multi Agent Driving Simulator
Oct 02, 2020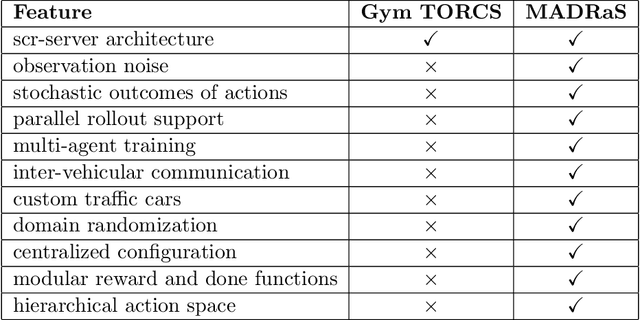
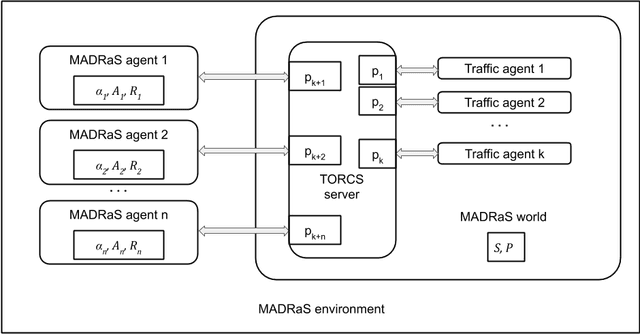

In this work, we present MADRaS, an open-source multi-agent driving simulator for use in the design and evaluation of motion planning algorithms for autonomous driving. MADRaS provides a platform for constructing a wide variety of highway and track driving scenarios where multiple driving agents can train for motion planning tasks using reinforcement learning and other machine learning algorithms. MADRaS is built on TORCS, an open-source car-racing simulator. TORCS offers a variety of cars with different dynamic properties and driving tracks with different geometries and surface properties. MADRaS inherits these functionalities from TORCS and introduces support for multi-agent training, inter-vehicular communication, noisy observations, stochastic actions, and custom traffic cars whose behaviours can be programmed to simulate challenging traffic conditions encountered in the real world. MADRaS can be used to create driving tasks whose complexities can be tuned along eight axes in well-defined steps. This makes it particularly suited for curriculum and continual learning. MADRaS is lightweight and it provides a convenient OpenAI Gym interface for independent control of each car. Apart from the primitive steering-acceleration-brake control mode of TORCS, MADRaS offers a hierarchical track-position -- speed control that can potentially be used to achieve better generalization. MADRaS uses multiprocessing to run each agent as a parallel process for efficiency and integrates well with popular reinforcement learning libraries like RLLib.
PolyDL: Polyhedral Optimizations for Creation of High Performance DL primitives
Jun 02, 2020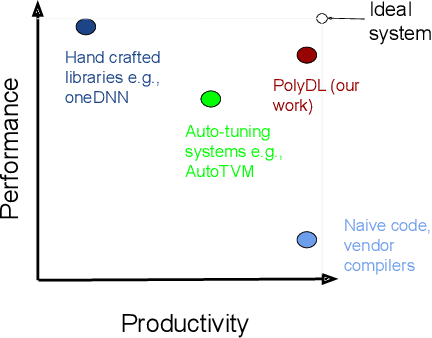
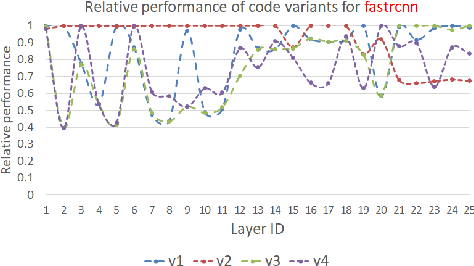
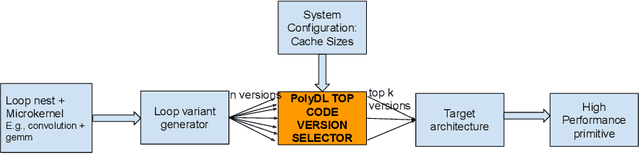

Deep Neural Networks (DNNs) have revolutionized many aspects of our lives. The use of DNNs is becoming ubiquitous including in softwares for image recognition, speech recognition, speech synthesis, language translation, to name a few. he training of DNN architectures however is computationally expensive. Once the model is created, its use in the intended application - the inference task, is computationally heavy too and the inference needs to be fast for real time use. For obtaining high performance today, the code of Deep Learning (DL) primitives optimized for specific architectures by expert programmers exposed via libraries is the norm. However, given the constant emergence of new DNN architectures, creating hand optimized code is expensive, slow and is not scalable. To address this performance-productivity challenge, in this paper we present compiler algorithms to automatically generate high performance implementations of DL primitives that closely match the performance of hand optimized libraries. We develop novel data reuse analysis algorithms using the polyhedral model to derive efficient execution schedules automatically. In addition, because most DL primitives use some variant of matrix multiplication at their core, we develop a flexible framework where it is possible to plug in library implementations of the same in lieu of a subset of the loops. We show that such a hybrid compiler plus a minimal library-use approach results in state-of-the-art performance. We develop compiler algorithms to also perform operator fusions that reduce data movement through the memory hierarchy of the computer system.
PolyScientist: Automatic Loop Transformations Combined with Microkernels for Optimization of Deep Learning Primitives
Feb 06, 2020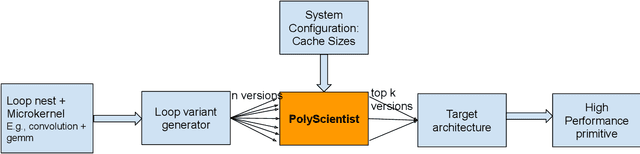
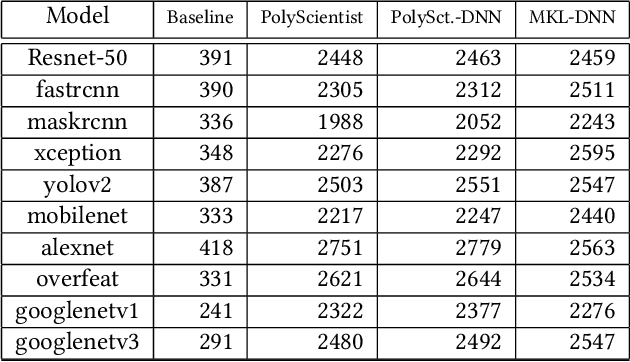
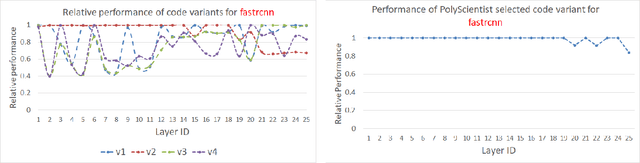

At the heart of deep learning training and inferencing are computationally intensive primitives such as convolutions which form the building blocks of deep neural networks. Researchers have taken two distinct approaches to creating high performance implementations of deep learning kernels, namely, 1) library development exemplified by Intel MKL-DNN for CPUs, 2) automatic compilation represented by the TensorFlow XLA compiler. The two approaches have their drawbacks: even though a custom built library can deliver very good performance, the cost and time of development of the library can be high. Automatic compilation of kernels is attractive but in practice, till date, automatically generated implementations lag expert coded kernels in performance by orders of magnitude. In this paper, we develop a hybrid solution to the development of deep learning kernels that achieves the best of both worlds: the expert coded microkernels are utilized for the innermost loops of kernels and we use the advanced polyhedral technology to automatically tune the outer loops for performance. We design a novel polyhedral model based data reuse algorithm to optimize the outer loops of the kernel. Through experimental evaluation on an important class of deep learning primitives namely convolutions, we demonstrate that the approach we develop attains the same levels of performance as Intel MKL-DNN, a hand coded deep learning library.
SEERL: Sample Efficient Ensemble Reinforcement Learning
Jan 15, 2020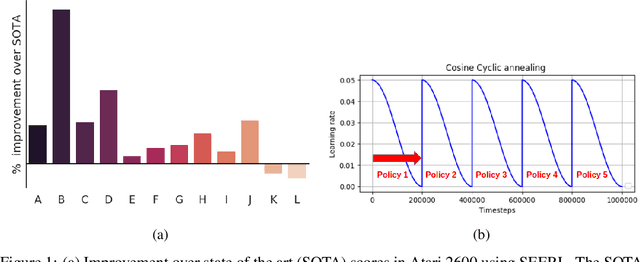
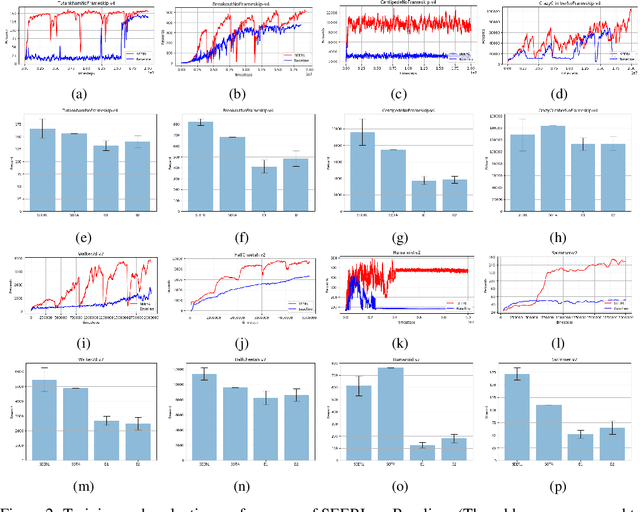
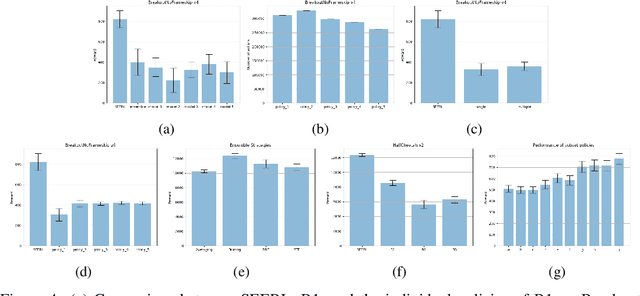
Ensemble learning is a very prevalent method employed in machine learning. The relative success of ensemble methods is attributed to its ability to tackle a wide range of instances and complex problems that require different low-level approaches. However, ensemble methods are relatively less popular in reinforcement learning owing to the high sample complexity and computational expense involved. We present a new training and evaluation framework for model-free algorithms that use ensembles of policies obtained from a single training instance. These policies are diverse in nature and are learned through directed perturbation of the model parameters at regular intervals. We show that learning an adequately diverse set of policies is required for a good ensemble while extreme diversity can prove detrimental to overall performance. We evaluate our approach to challenging discrete and continuous control tasks and also discuss various ensembling strategies. Our framework is substantially sample efficient, computationally inexpensive and is seen to outperform state of the art(SOTA) scores in Atari 2600 and Mujoco. Video results can be found at https://www.youtube.com/channel/UC95Kctu9Mp8BlFmtGD2TGTA
K-TanH: Hardware Efficient Activations For Deep Learning
Oct 21, 2019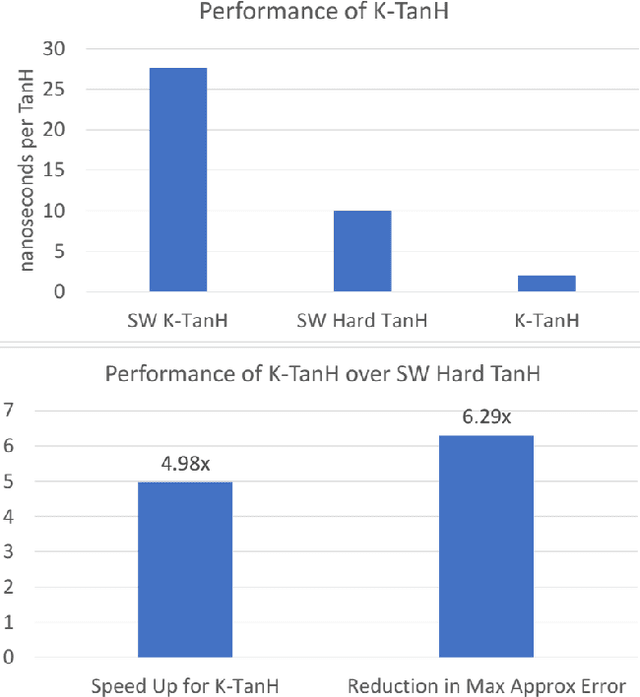
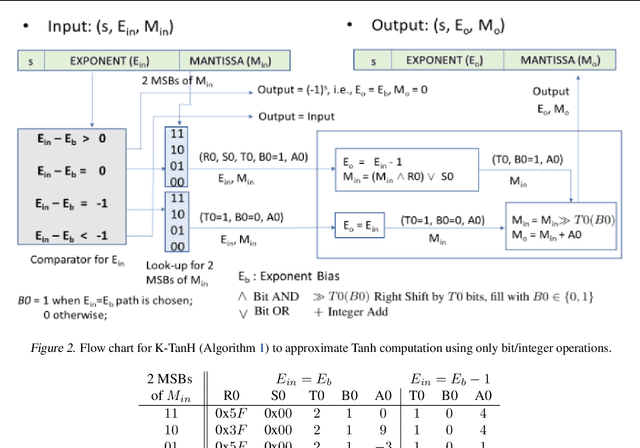

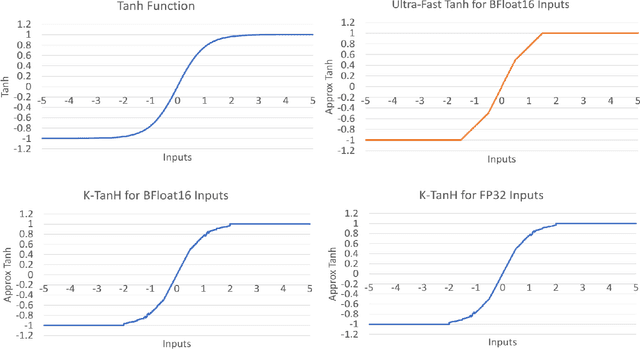
We propose K-TanH, a novel, highly accurate, hardware efficient approximation of popular activation function Tanh for Deep Learning. K-TanH consists of a sequence of parameterized bit/integer operations, such as, masking, shift and add/subtract (no floating point operation needed) where parameters are stored in a very small look-up table (bit-masking step can be eliminated). The design of K-TanH is flexible enough to deal with multiple numerical formats, such as, FP32 and BFloat16. High quality approximations to other activation functions, e.g., Swish and GELU, can be derived from K-TanH. We provide RTL design for K-TanH to demonstrate its area/power/performance efficacy. It is more accurate than existing piecewise approximations for Tanh. For example, K-TanH achieves $\sim 5\times$ speed up and $> 6\times$ reduction in maximum approximation error over software implementation of Hard TanH. Experimental results for low-precision BFloat16 training of language translation model GNMT on WMT16 data sets with approximate Tanh and Sigmoid obtained via K-TanH achieve similar accuracy and convergence as training with exact Tanh and Sigmoid.
High Performance Scalable FPGA Accelerator for Deep Neural Networks
Aug 29, 2019
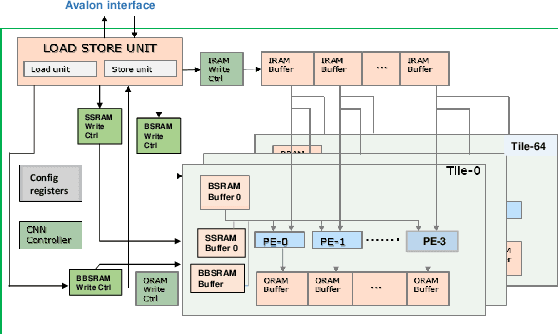
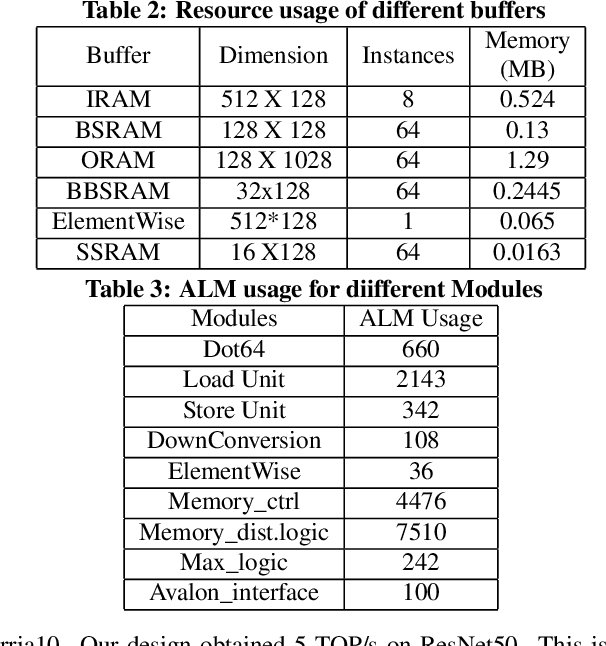
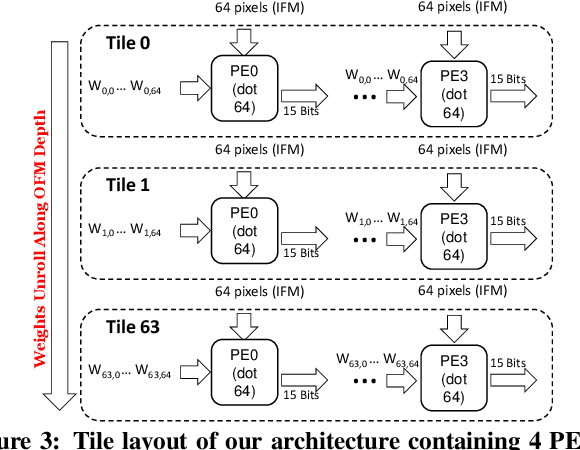
Low-precision is the first order knob for achieving higher Artificial Intelligence Operations (AI-TOPS). However the algorithmic space for sub-8-bit precision compute is diverse, with disruptive changes happening frequently, making FPGAs a natural choice for Deep Neural Network inference, In this work we present an FPGA-based accelerator for CNN inference acceleration. We use {\it INT-8-2} compute (with {\it 8 bit} activation and {2 bit} weights) which is recently showing promise in the literature, and which no known ASIC, CPU or GPU natively supports today. Using a novel Adaptive Logic Module (ALM) based design, as a departure from traditional DSP based designs, we are able to achieve high performance measurement of 5 AI-TOPS for {\it Arria10} and project a performance of 76 AI-TOPS at 0.7 TOPS/W for {\it Stratix10}. This exceeds known CPU, GPU performance and comes close to best known ASIC (TPU) numbers, while retaining the versatility of the FPGA platform for other applications.