 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Centering
May 16, 2024We show that discounted methods for solving continuing reinforcement learning problems can perform significantly better if they center their rewards by subtracting out the rewards' empirical average. The improvement is substantial at commonly used discount factors and increases further as the discount factor approaches one. In addition, we show that if a problem's rewards are shifted by a constant, then standard methods perform much worse, whereas methods with reward centering are unaffected. Estimating the average reward is straightforward in the on-policy setting; we propose a slightly more sophisticated method for the off-policy setting. Reward centering is a general idea, so we expect almost every reinforcement-learning algorithm to benefit by the addition of reward centering.
Average-Reward Learning and Planning with Options
Oct 26, 2021
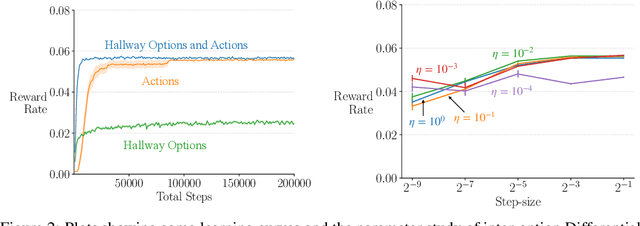
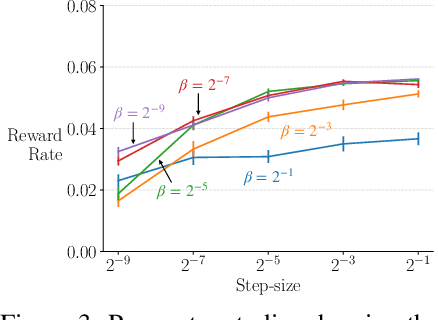
We extend the options framework for temporal abstraction in reinforcement learning from discounted Markov decision processes (MDPs) to average-reward MDPs. Our contributions include general convergent off-policy inter-option learning algorithms, intra-option algorithms for learning values and models, as well as sample-based planning variants of our learning algorithms. Our algorithms and convergence proofs extend those recently developed by Wan, Naik, and Sutton. We also extend the notion of option-interrupting behavior from the discounted to the average-reward formulation. We show the efficacy of the proposed algorithms with experiments on a continuing version of the Four-Room domain.
Planning with Expectation Models for Control
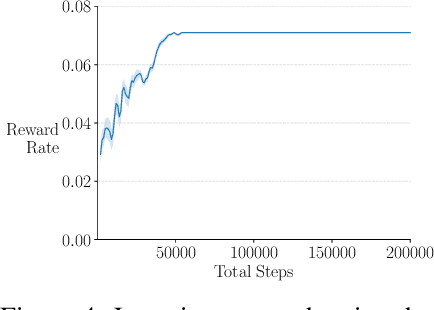
Apr 17, 2021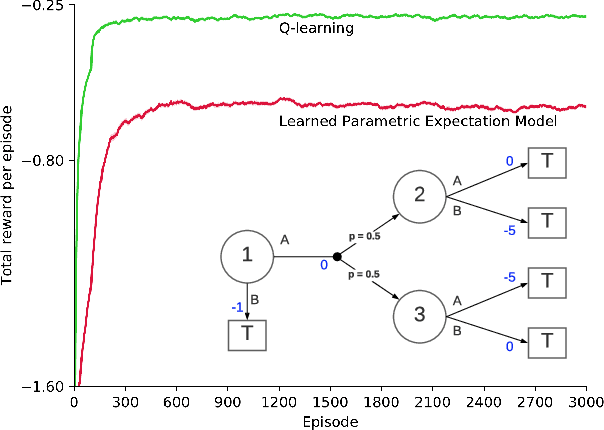

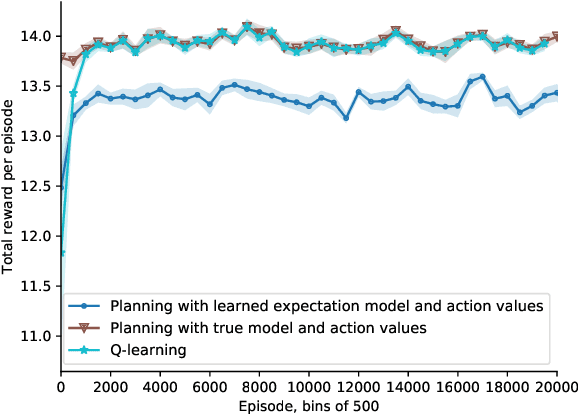
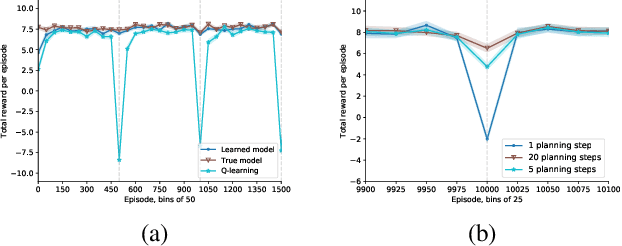
In model-based reinforcement learning (MBRL), Wan et al. (2019) showed conditions under which the environment model could produce the expectation of the next feature vector rather than the full distribution, or a sample thereof, with no loss in planning performance. Such expectation models are of interest when the environment is stochastic and non-stationary, and the model is approximate, such as when it is learned using function approximation. In these cases a full distribution model may be impractical and a sample model may be either more expensive computationally or of high variance. Wan et al. considered only planning for prediction to evaluate a fixed policy. In this paper, we treat the control case - planning to improve and find a good approximate policy. We prove that planning with an expectation model must update a state-value function, not an action-value function as previously suggested (e.g., Sorg & Singh, 2010). This opens the question of how planning influences action selections. We consider three strategies for this and present general MBRL algorithms for each. We identify the strengths and weaknesses of these algorithms in computational experiments. Our algorithms and experiments are the first to treat MBRL with expectation models in a general setting.
MADRaS : Multi Agent Driving Simulator
Oct 02, 2020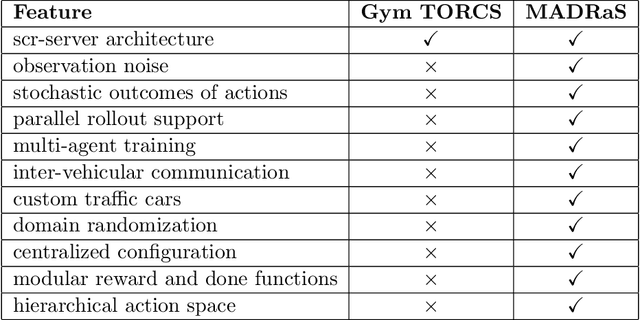
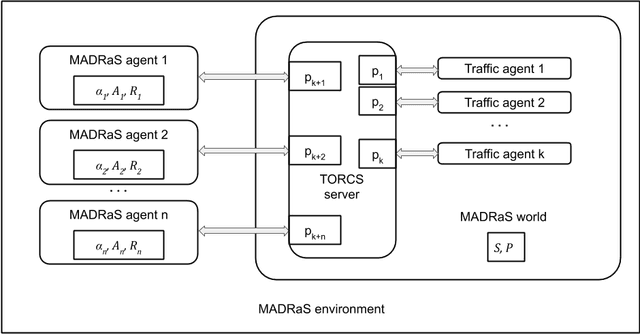

In this work, we present MADRaS, an open-source multi-agent driving simulator for use in the design and evaluation of motion planning algorithms for autonomous driving. MADRaS provides a platform for constructing a wide variety of highway and track driving scenarios where multiple driving agents can train for motion planning tasks using reinforcement learning and other machine learning algorithms. MADRaS is built on TORCS, an open-source car-racing simulator. TORCS offers a variety of cars with different dynamic properties and driving tracks with different geometries and surface properties. MADRaS inherits these functionalities from TORCS and introduces support for multi-agent training, inter-vehicular communication, noisy observations, stochastic actions, and custom traffic cars whose behaviours can be programmed to simulate challenging traffic conditions encountered in the real world. MADRaS can be used to create driving tasks whose complexities can be tuned along eight axes in well-defined steps. This makes it particularly suited for curriculum and continual learning. MADRaS is lightweight and it provides a convenient OpenAI Gym interface for independent control of each car. Apart from the primitive steering-acceleration-brake control mode of TORCS, MADRaS offers a hierarchical track-position -- speed control that can potentially be used to achieve better generalization. MADRaS uses multiprocessing to run each agent as a parallel process for efficiency and integrates well with popular reinforcement learning libraries like RLLib.
Learning and Planning in Average-Reward Markov Decision Processes
Jun 29, 2020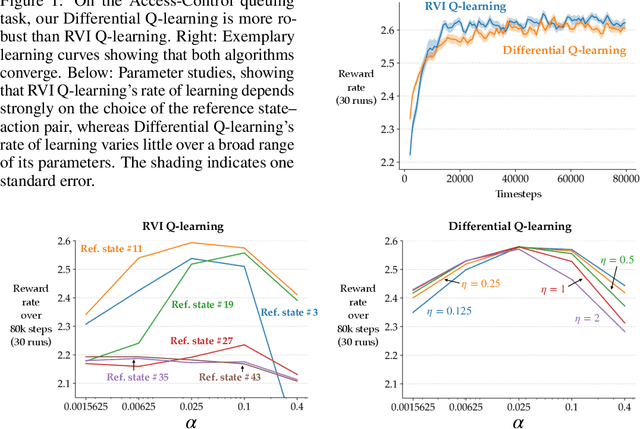
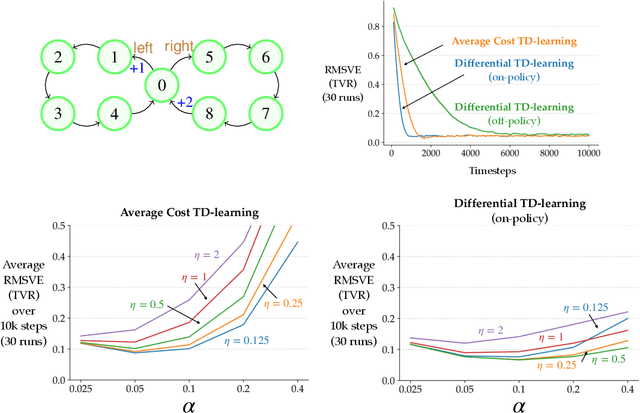
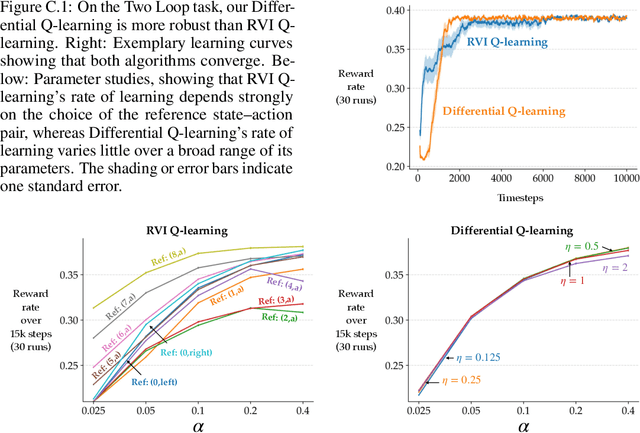

We introduce improved learning and planning algorithms for average-reward MDPs, including 1) the first general proven-convergent off-policy model-free control algorithm without reference states, 2) the first proven-convergent off-policy model-free prediction algorithm, and 3) the first learning algorithms that converge to the actual value function rather than to the value function plus an offset. All of our algorithms are based on using the temporal-difference error rather than the conventional error when updating the estimate of the average reward. Our proof techniques are based on those of Abounadi, Bertsekas, and Borkar (2001). Empirically, we show that the use of the temporal-difference error generally results in faster learning, and that reliance on a reference state generally results in slower learning and risks divergence. All of our learning algorithms are fully online, and all of our planning algorithms are fully incremental.
Discounted Reinforcement Learning is Not an Optimization Problem
Nov 16, 2019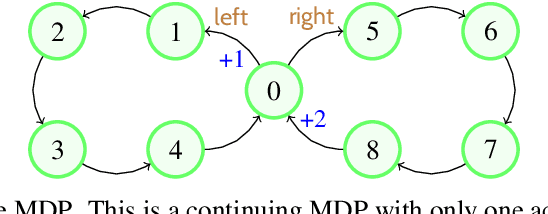
Discounted reinforcement learning is fundamentally incompatible with function approximation for control in continuing tasks. It is not an optimization problem in its usual formulation, so when using function approximation there is no optimal policy. We substantiate these claims, then go on to address some misconceptions about discounting and its connection to the average reward formulation. We encourage researchers to adopt rigorous optimization approaches, such as maximizing average reward, for reinforcement learning in continuing tasks.
RAIL: Risk-Averse Imitation Learning
Nov 29, 2017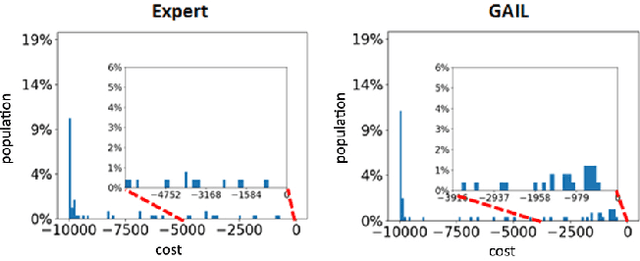
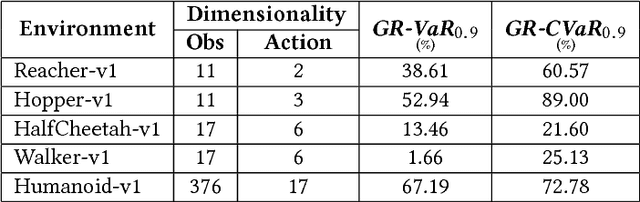
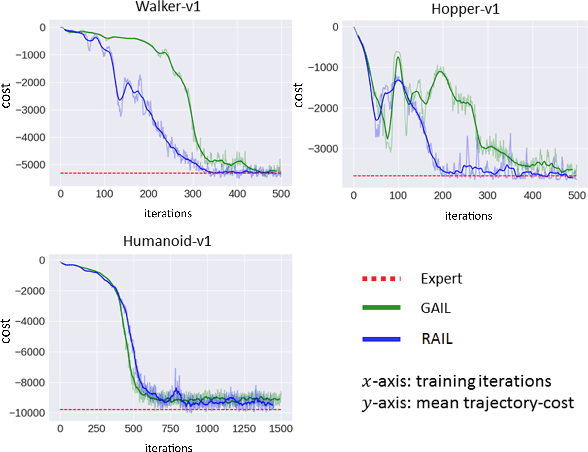
Imitation learning algorithms learn viable policies by imitating an expert's behavior when reward signals are not available. Generative Adversarial Imitation Learning (GAIL) is a state-of-the-art algorithm for learning policies when the expert's behavior is available as a fixed set of trajectories. We evaluate in terms of the expert's cost function and observe that the distribution of trajectory-costs is often more heavy-tailed for GAIL-agents than the expert at a number of benchmark continuous-control tasks. Thus, high-cost trajectories, corresponding to tail-end events of catastrophic failure, are more likely to be encountered by the GAIL-agents than the expert. This makes the reliability of GAIL-agents questionable when it comes to deployment in risk-sensitive applications like robotic surgery and autonomous driving. In this work, we aim to minimize the occurrence of tail-end events by minimizing tail risk within the GAIL framework. We quantify tail risk by the Conditional-Value-at-Risk (CVaR) of trajectories and develop the Risk-Averse Imitation Learning (RAIL) algorithm. We observe that the policies learned with RAIL show lower tail-end risk than those of vanilla GAIL. Thus the proposed RAIL algorithm appears as a potent alternative to GAIL for improved reliability in risk-sensitive applications.