 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Expectation Models for Control
Apr 17, 2021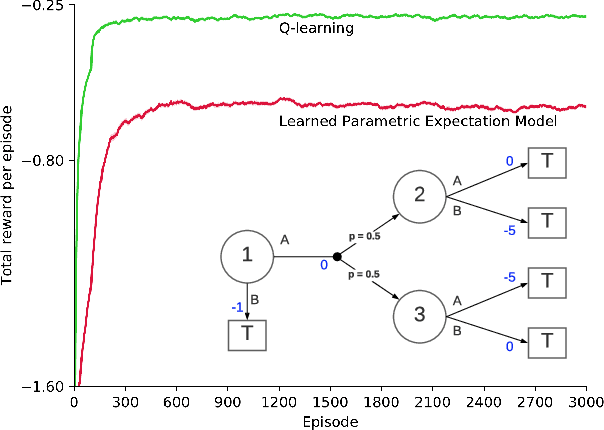

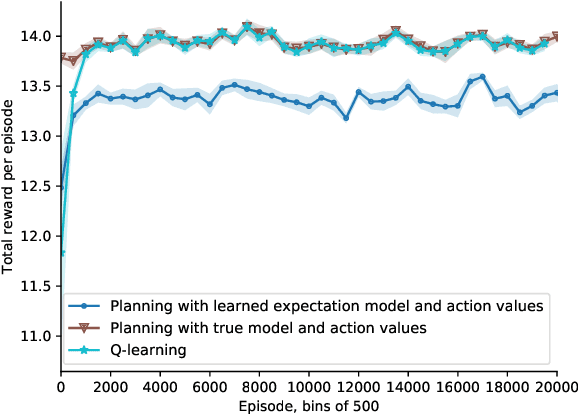
In model-based reinforcement learning (MBRL), Wan et al. (2019) showed conditions under which the environment model could produce the expectation of the next feature vector rather than the full distribution, or a sample thereof, with no loss in planning performance. Such expectation models are of interest when the environment is stochastic and non-stationary, and the model is approximate, such as when it is learned using function approximation. In these cases a full distribution model may be impractical and a sample model may be either more expensive computationally or of high variance. Wan et al. considered only planning for prediction to evaluate a fixed policy. In this paper, we treat the control case - planning to improve and find a good approximate policy. We prove that planning with an expectation model must update a state-value function, not an action-value function as previously suggested (e.g., Sorg & Singh, 2010). This opens the question of how planning influences action selections. We consider three strategies for this and present general MBRL algorithms for each. We identify the strengths and weaknesses of these algorithms in computational experiments. Our algorithms and experiments are the first to treat MBRL with expectation models in a general setting.
Document-editing Assistants and Model-based Reinforcement Learning as a Path to Conversational AI
Aug 27, 2020
Intelligent assistants that follow commands or answer simple questions, such as Siri and Google search, are among the most economically important applications of AI. Future conversational AI assistants promise even greater capabilities and a better user experience through a deeper understanding of the domain, the user, or the user's purposes. But what domain and what methods are best suited to researching and realizing this promise? In this article we argue for the domain of voice document editing and for the methods of model-based reinforcement learning. The primary advantages of voice document editing are that the domain is tightly scoped and that it provides something for the conversation to be about (the document) that is delimited and fully accessible to the intelligent assistant. The advantages of reinforcement learning in general are that its methods are designed to learn from interaction without explicit instruction and that it formalizes the purposes of the assistant. Model-based reinforcement learning is needed in order to genuinely understand the domain of discourse and thereby work efficiently with the user to achieve their goals. Together, voice document editing and model-based reinforcement learning comprise a promising research direction for achieving conversational AI.
Sample-Efficient Model-based Actor-Critic for an Interactive Dialogue Task
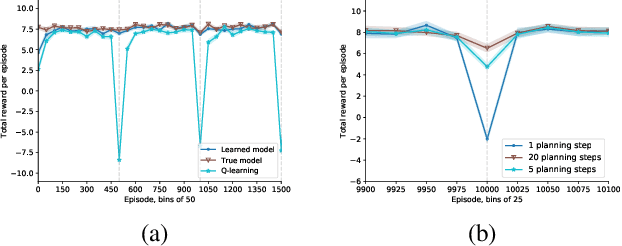
Apr 28, 2020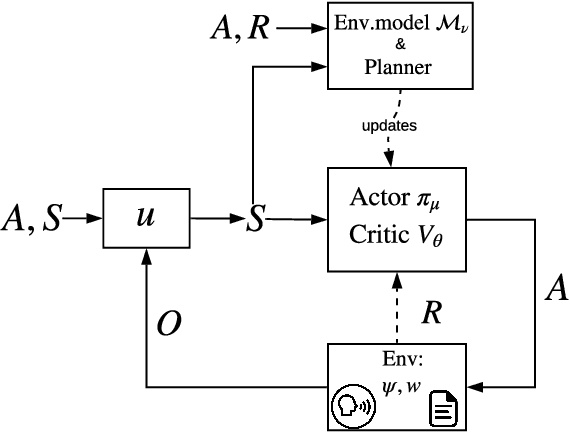
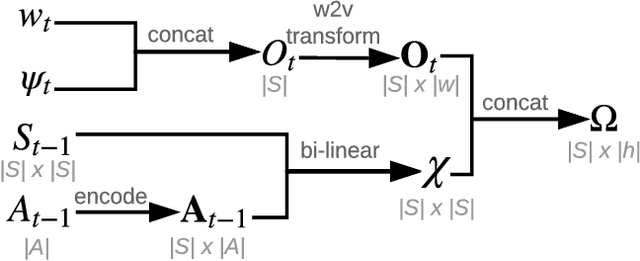
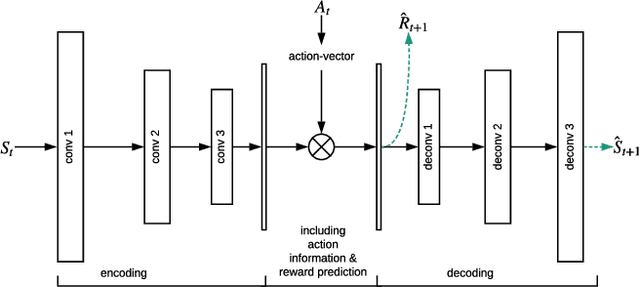

Human-computer interactive systems that rely on machine learning are becoming paramount to the lives of millions of people who use digital assistants on a daily basis. Yet, further advances are limited by the availability of data and the cost of acquiring new samples. One way to address this problem is by improving the sample efficiency of current approaches. As a solution path, we present a model-based reinforcement learning algorithm for an interactive dialogue task. We build on commonly used actor-critic methods, adding an environment model and planner that augments a learning agent to learn the model of the environment dynamics. Our results show that, on a simulation that mimics the interactive task, our algorithm requires 70 times fewer samples, compared to the baseline of commonly used model-free algorithm, and demonstrates 2~times better performance asymptotically. Moreover, we introduce a novel contribution of computing a soft planner policy and further updating a model-free policy yielding a less computationally expensive model-free agent as good as the model-based one. This model-based architecture serves as a foundation that can be extended to other human-computer interactive tasks allowing further advances in this direction.