 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Expectation Models for Control
Paper and Code
Apr 17, 2021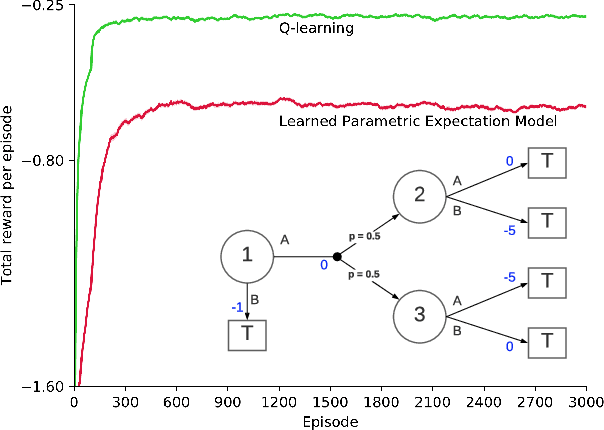

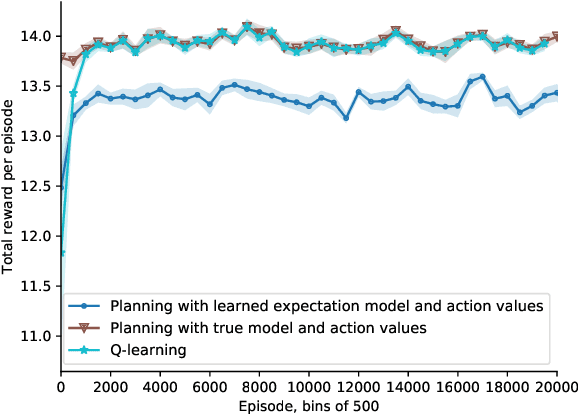
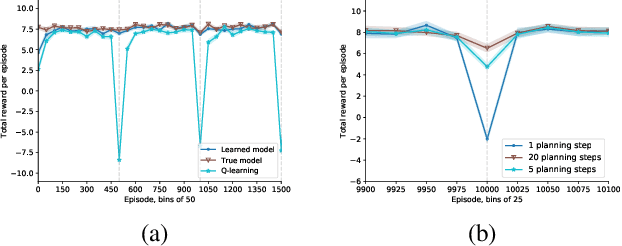
In model-based reinforcement learning (MBRL), Wan et al. (2019) showed conditions under which the environment model could produce the expectation of the next feature vector rather than the full distribution, or a sample thereof, with no loss in planning performance. Such expectation models are of interest when the environment is stochastic and non-stationary, and the model is approximate, such as when it is learned using function approximation. In these cases a full distribution model may be impractical and a sample model may be either more expensive computationally or of high variance. Wan et al. considered only planning for prediction to evaluate a fixed policy. In this paper, we treat the control case - planning to improve and find a good approximate policy. We prove that planning with an expectation model must update a state-value function, not an action-value function as previously suggested (e.g., Sorg & Singh, 2010). This opens the question of how planning influences action selections. We consider three strategies for this and present general MBRL algorithms for each. We identify the strengths and weaknesses of these algorithms in computational experiments. Our algorithms and experiments are the first to treat MBRL with expectation models in a general setting.