 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Model-based Actor-Critic for an Interactive Dialogue Task
Apr 28, 2020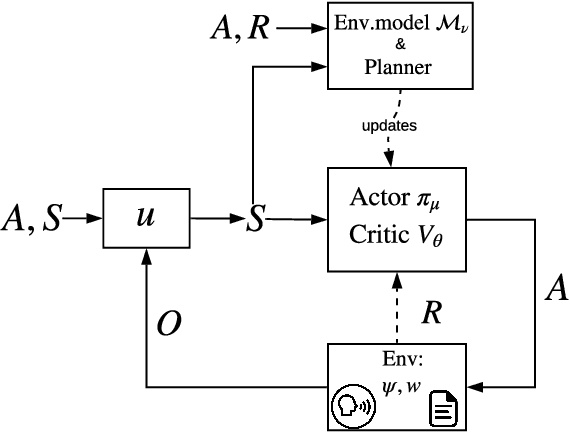
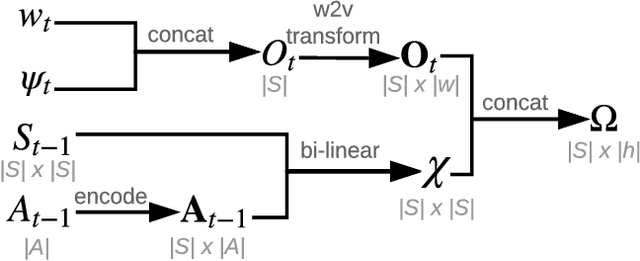
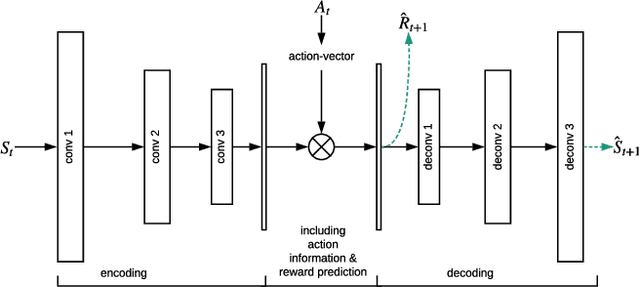

Human-computer interactive systems that rely on machine learning are becoming paramount to the lives of millions of people who use digital assistants on a daily basis. Yet, further advances are limited by the availability of data and the cost of acquiring new samples. One way to address this problem is by improving the sample efficiency of current approaches. As a solution path, we present a model-based reinforcement learning algorithm for an interactive dialogue task. We build on commonly used actor-critic methods, adding an environment model and planner that augments a learning agent to learn the model of the environment dynamics. Our results show that, on a simulation that mimics the interactive task, our algorithm requires 70 times fewer samples, compared to the baseline of commonly used model-free algorithm, and demonstrates 2~times better performance asymptotically. Moreover, we introduce a novel contribution of computing a soft planner policy and further updating a model-free policy yielding a less computationally expensive model-free agent as good as the model-based one. This model-based architecture serves as a foundation that can be extended to other human-computer interactive tasks allowing further advances in this direction.
Neural Heterogeneous Scheduler
Jun 09, 2019



Access to parallel and distributed computation has enabled researchers and developers to improve algorithms and performance in many applications. Recent research has focused on next generation special purpose systems with multiple kinds of coprocessors, known as heterogeneous system-on-chips (SoC). In this paper, we introduce a method to intelligently schedule--and learn to schedule--a stream of tasks to available processing elements in such a system. We use deep reinforcement learning enabling complex sequential decision making and empirically show that our reinforcement learning system provides for a viable, better alternative to conventional scheduling heuristics with respect to minimizing execution time.
Control of Memory, Active Perception, and Action in Minecraft
May 30, 2016



In this paper, we introduce a new set of reinforcement learning (RL) tasks in Minecraft (a flexible 3D world). We then use these tasks to systematically compare and contrast existing deep reinforcement learning (DRL) architectures with our new memory-based DRL architectures. These tasks are designed to emphasize, in a controllable manner, issues that pose challenges for RL methods including partial observability (due to first-person visual observations), delayed rewards, high-dimensional visual observations, and the need to use active perception in a correct manner so as to perform well in the tasks. While these tasks are conceptually simple to describe, by virtue of having all of these challenges simultaneously they are difficult for current DRL architectures. Additionally, we evaluate the generalization performance of the architectures on environments not used during training. The experimental results show that our new architectures generalize to unseen environments better than existing DRL architectures.