 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCQ+: Robust and Scalable Routing with Multi-Agent Deep Reinforcement Learning for Highly Dynamic Networks
Nov 29, 2021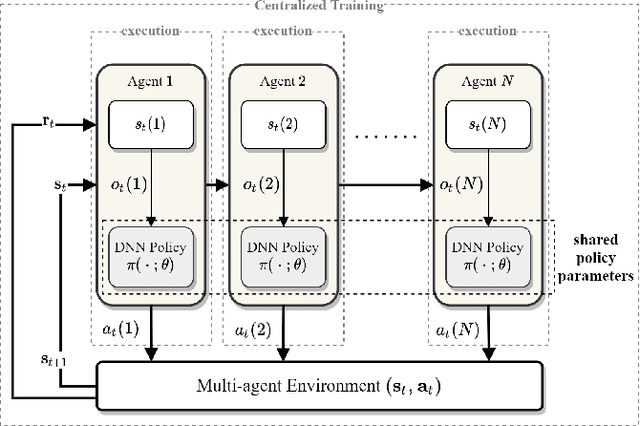
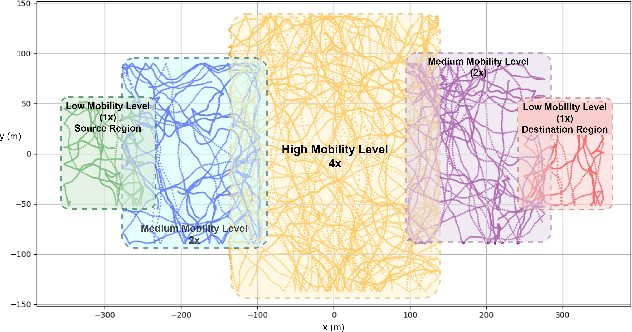
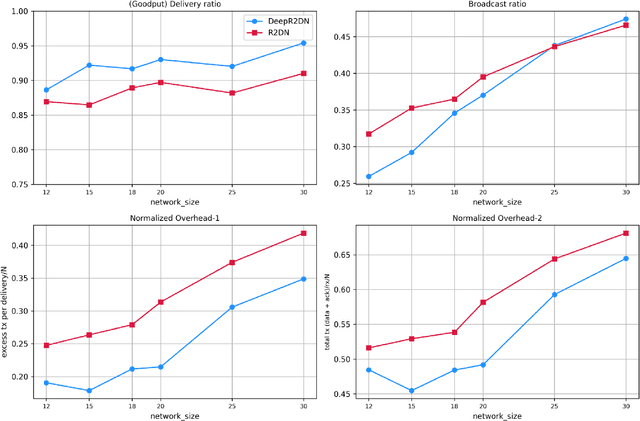
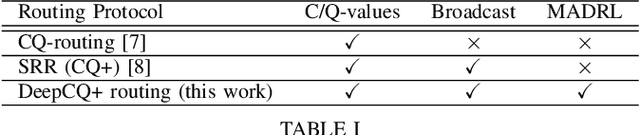
Highly dynamic mobile ad-hoc networks (MANETs) remain as one of the most challenging environments to develop and deploy robust, efficient, and scalable routing protocols. In this paper, we present DeepCQ+ routing protocol which, in a novel manner integrates emerging multi-agent deep reinforcement learning (MADRL) techniques into existing Q-learning-based routing protocols and their variants and achieves persistently higher performance across a wide range of topology and mobility configurations. While keeping the overall protocol structure of the Q-learning-based routing protocols, DeepCQ+ replaces statically configured parameterized thresholds and hand-written rules with carefully designed MADRL agents such that no configuration of such parameters is required a priori. Extensive simulation shows that DeepCQ+ yields significantly increased end-to-end throughput with lower overhead and no apparent degradation of end-to-end delays (hop counts) compared to its Q-learning based counterparts. Qualitatively, and perhaps more significantly, DeepCQ+ maintains remarkably similar performance gains under many scenarios that it was not trained for in terms of network sizes, mobility conditions, and traffic dynamics. To the best of our knowledge, this is the first successful application of the MADRL framework for the MANET routing problem that demonstrates a high degree of scalability and robustness even under environments that are outside the trained range of scenarios. This implies that our MARL-based DeepCQ+ design solution significantly improves the performance of Q-learning based CQ+ baseline approach for comparison and increases its practicality and explainability because the real-world MANET environment will likely vary outside the trained range of MANET scenarios. Additional techniques to further increase the gains in performance and scalability are discussed.
Robust and Scalable Routing with Multi-Agent Deep Reinforcement Learning for MANETs
Jan 09, 2021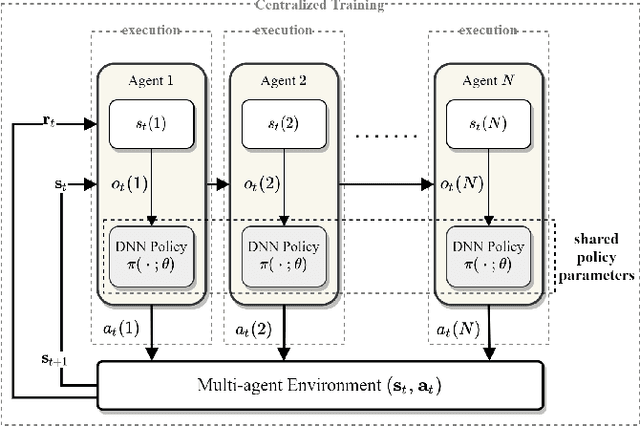
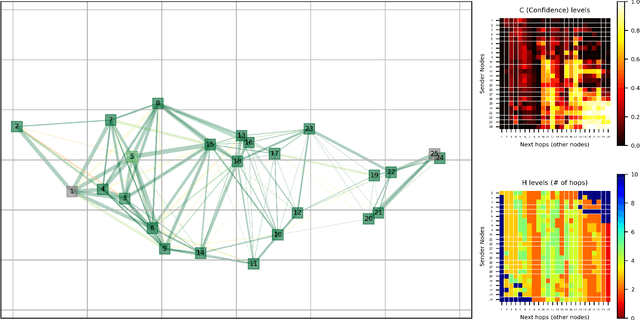
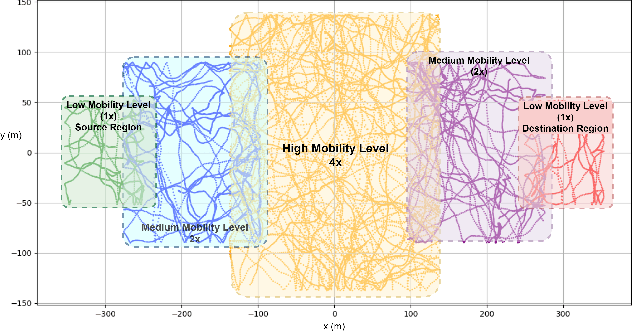
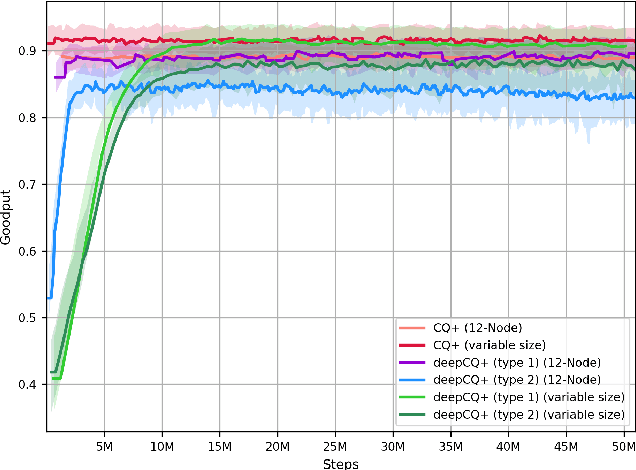
We address the packet routing problem in highly dynamic mobile ad-hoc networks (MANETs). In the network routing problem each router chooses the next-hop(s) of each packet to deliver the packet to a destination with lower delay, higher reliability, and less overhead in the network. In this paper, we present a novel framework and routing policies, DeepCQ+ routing, using multi-agent deep reinforcement learning (MADRL) which is designed to be robust and scalable for MANETs. Unlike other deep reinforcement learning (DRL)-based routing solutions in the literature, our approach has enabled us to train over a limited range of network parameters and conditions, but achieve realistic routing policies for a much wider range of conditions including a variable number of nodes, different data flows with varying data rates and source/destination pairs, diverse mobility levels, and other dynamic topology of networks. We demonstrate the scalability, robustness, and performance enhancements obtained by DeepCQ+ routing over a recently proposed model-free and non-neural robust and reliable routing technique (i.e. CQ+ routing). DeepCQ+ routing outperforms non-DRL-based CQ+ routing in terms of overhead while maintains same goodput rate. Under a wide range of network sizes and mobility conditions, we have observed the reduction in normalized overhead of 10-15%, indicating that the DeepCQ+ routing policy delivers more packets end-to-end with less overhead used. To the best of our knowledge, this is the first successful application of MADRL for the MANET routing problem that simultaneously achieves scalability and robustness under dynamic conditions while outperforming its non-neural counterpart. More importantly, we provide a framework to design scalable and robust routing policy with any desired network performance metric of interest.
DeepSoCS: A Neural Scheduler for Heterogeneous System-on-Chip (SoC) Resource Scheduling
Jun 05, 2020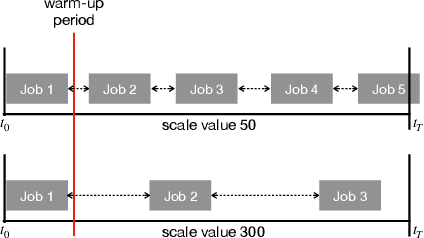
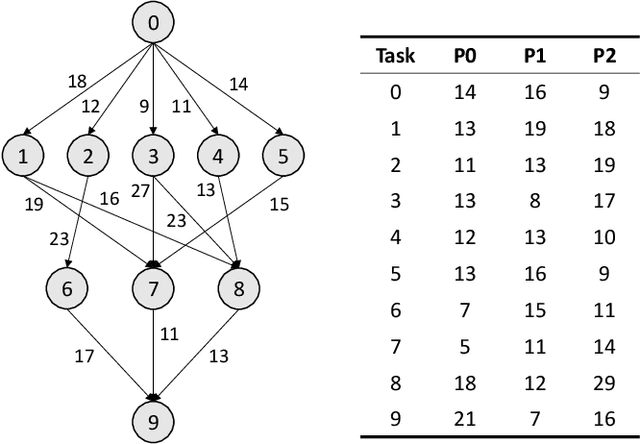
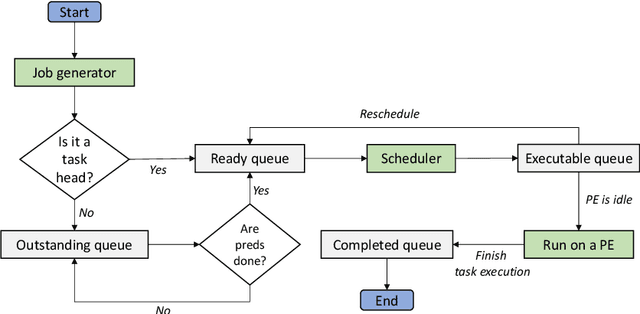
In this paper, we~present a novel scheduling solution for a class of System-on-Chip (SoC) systems where heterogeneous chip resources (DSP, FPGA, GPU, etc.) must be efficiently scheduled for continuously arriving hierarchical jobs with their tasks represented by a directed acyclic graph. Traditionally, heuristic algorithms have been widely used for many resource scheduling domains, and Heterogeneous Earliest Finish Time (HEFT) has been a dominating state-of-the-art technique across a broad range of heterogeneous resource scheduling domains over many years. Despite their long-standing popularity, HEFT-like algorithms are known to be vulnerable to a small amount of noise added to the environment. Our Deep Reinforcement Learning (DRL)-based SoC Scheduler (DeepSoCS), capable of learning the "best" task ordering under dynamic environment changes, overcomes the brittleness of rule-based schedulers such as HEFT with significantly higher performance across different types of jobs. We~describe a DeepSoCS design process using a real-time heterogeneous SoC scheduling emulator, discuss major challenges, and present two novel neural network design features that lead to outperforming HEFT: (i) hierarchical job- and task-graph embedding; and (ii) efficient use of real-time task information in the state space. Furthermore, we~introduce effective techniques to address two fundamental challenges present in our environment: delayed consequences and joint actions. Through an extensive simulation study, we~show that our DeepSoCS exhibits the significantly higher performance of job execution time than that of HEFT with a higher level of robustness under realistic noise conditions. We~conclude with a discussion of the potential improvements for our DeepSoCS neural scheduler.
Neural Heterogeneous Scheduler
Jun 09, 2019



Access to parallel and distributed computation has enabled researchers and developers to improve algorithms and performance in many applications. Recent research has focused on next generation special purpose systems with multiple kinds of coprocessors, known as heterogeneous system-on-chips (SoC). In this paper, we introduce a method to intelligently schedule--and learn to schedule--a stream of tasks to available processing elements in such a system. We use deep reinforcement learning enabling complex sequential decision making and empirically show that our reinforcement learning system provides for a viable, better alternative to conventional scheduling heuristics with respect to minimizing execution time.