 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for System-on-Chip: Myths and Realities
Jul 29, 2022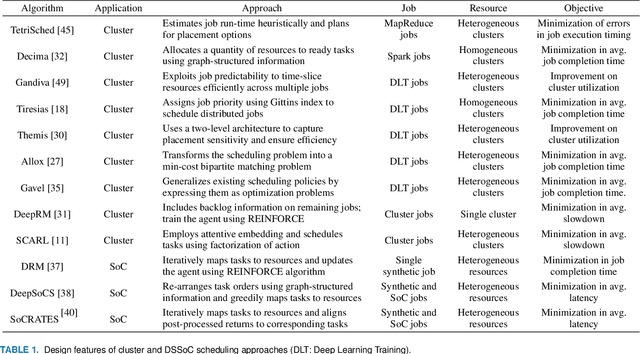


Neural schedulers based on deep reinforcement learning (DRL) have shown considerable potential for solving real-world resource allocation problems, as they have demonstrated significant performance gain in the domain of cluster computing. In this paper, we investigate the feasibility of neural schedulers for the domain of System-on-Chip (SoC) resource allocation through extensive experiments and comparison with non-neural, heuristic schedulers. The key finding is three-fold. First, neural schedulers designed for cluster computing domain do not work well for SoC due to i) heterogeneity of SoC computing resources and ii) variable action set caused by randomness in incoming jobs. Second, our novel neural scheduler technique, Eclectic Interaction Matching (EIM), overcomes the above challenges, thus significantly improving the existing neural schedulers. Specifically, we rationalize the underlying reasons behind the performance gain by the EIM-based neural scheduler. Third, we discover that the ratio of the average processing elements (PE) switching delay and the average PE computation time significantly impacts the performance of neural SoC schedulers even with EIM. Consequently, future neural SoC scheduler design must consider this metric as well as its implementation overhead for practical utility.
A Scalable and Reproducible System-on-Chip Simulation for Reinforcement Learning
Apr 27, 2021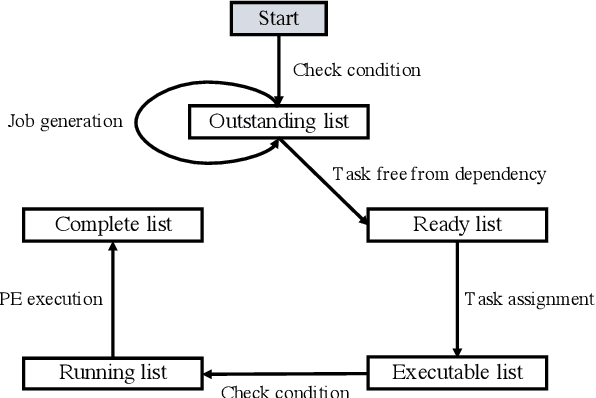
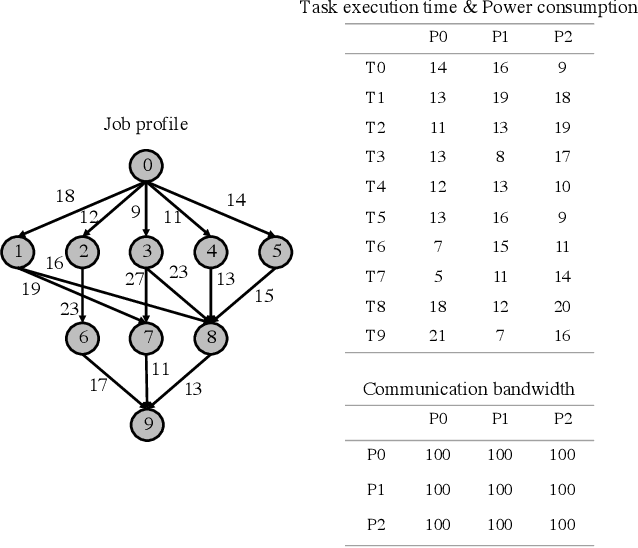
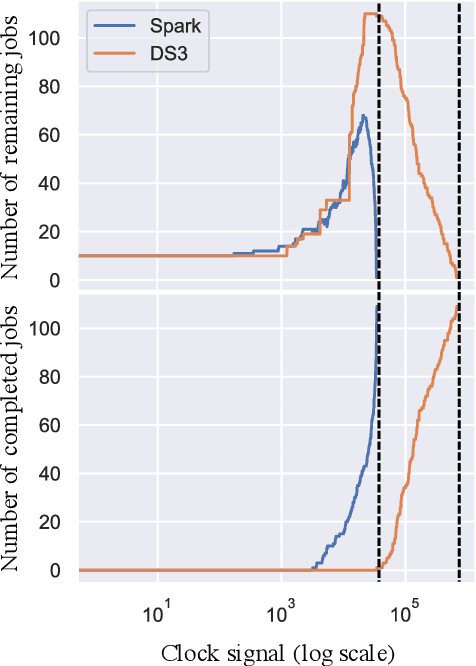
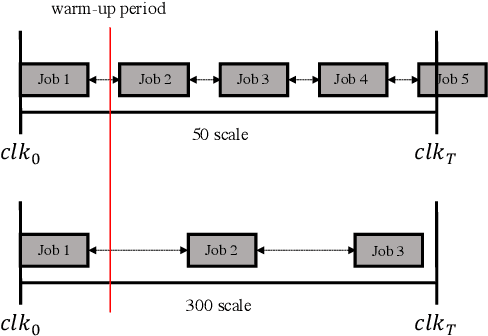
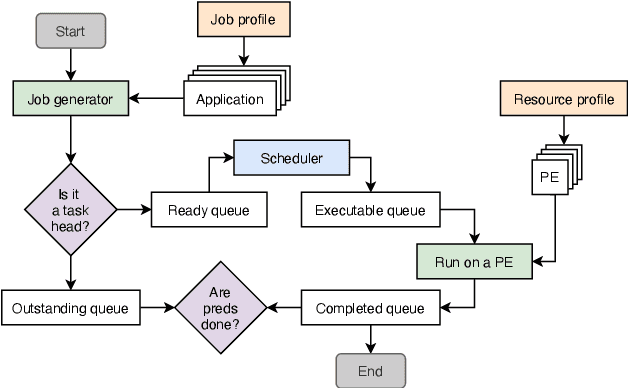
Deep Reinforcement Learning (DRL) underlies in a simulated environment and optimizes objective goals. By extending the conventional interaction scheme, this paper proffers gym-ds3, a scalable and reproducible open environment tailored for a high-fidelity Domain-Specific System-on-Chip (DSSoC) application. The simulation corroborates to schedule hierarchical jobs onto heterogeneous System-on-Chip (SoC) processors and bridges the system to reinforcement learning research. We systematically analyze the representative SoC simulator and discuss the primary challenging aspects that the system (1) continuously generates indefinite jobs at a rapid injection rate, (2) optimizes complex objectives, and (3) operates in steady-state scheduling. We provide exemplary snippets and experimentally demonstrate the run-time performances on different schedulers that successfully mimic results achieved from the standard DS3 framework and real-world embedded systems.
DeepSoCS: A Neural Scheduler for Heterogeneous System-on-Chip (SoC) Resource Scheduling
Jun 05, 2020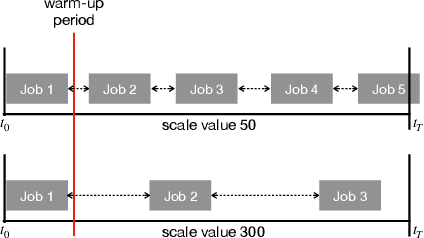
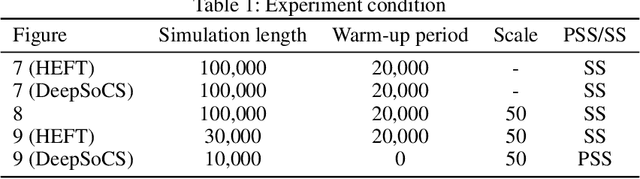
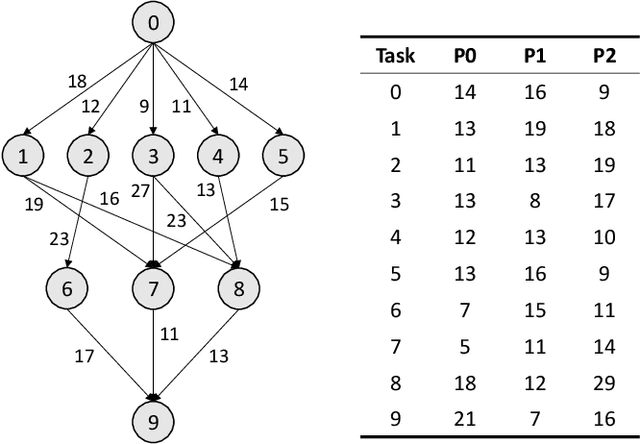
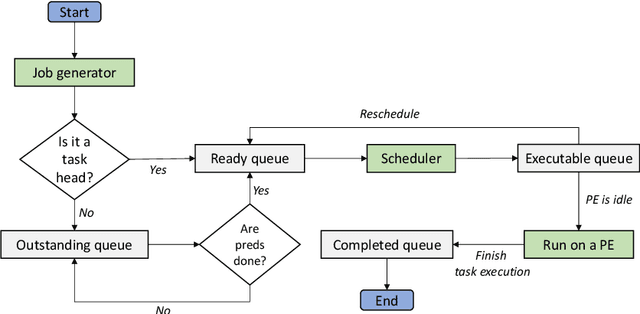
In this paper, we~present a novel scheduling solution for a class of System-on-Chip (SoC) systems where heterogeneous chip resources (DSP, FPGA, GPU, etc.) must be efficiently scheduled for continuously arriving hierarchical jobs with their tasks represented by a directed acyclic graph. Traditionally, heuristic algorithms have been widely used for many resource scheduling domains, and Heterogeneous Earliest Finish Time (HEFT) has been a dominating state-of-the-art technique across a broad range of heterogeneous resource scheduling domains over many years. Despite their long-standing popularity, HEFT-like algorithms are known to be vulnerable to a small amount of noise added to the environment. Our Deep Reinforcement Learning (DRL)-based SoC Scheduler (DeepSoCS), capable of learning the "best" task ordering under dynamic environment changes, overcomes the brittleness of rule-based schedulers such as HEFT with significantly higher performance across different types of jobs. We~describe a DeepSoCS design process using a real-time heterogeneous SoC scheduling emulator, discuss major challenges, and present two novel neural network design features that lead to outperforming HEFT: (i) hierarchical job- and task-graph embedding; and (ii) efficient use of real-time task information in the state space. Furthermore, we~introduce effective techniques to address two fundamental challenges present in our environment: delayed consequences and joint actions. Through an extensive simulation study, we~show that our DeepSoCS exhibits the significantly higher performance of job execution time than that of HEFT with a higher level of robustness under realistic noise conditions. We~conclude with a discussion of the potential improvements for our DeepSoCS neural scheduler.
Neural Heterogeneous Scheduler
Jun 09, 2019



Access to parallel and distributed computation has enabled researchers and developers to improve algorithms and performance in many applications. Recent research has focused on next generation special purpose systems with multiple kinds of coprocessors, known as heterogeneous system-on-chips (SoC). In this paper, we introduce a method to intelligently schedule--and learn to schedule--a stream of tasks to available processing elements in such a system. We use deep reinforcement learning enabling complex sequential decision making and empirically show that our reinforcement learning system provides for a viable, better alternative to conventional scheduling heuristics with respect to minimizing execution time.
Deep Multi-Agent Reinforcement Learning with Relevance Graphs
Nov 30, 2018

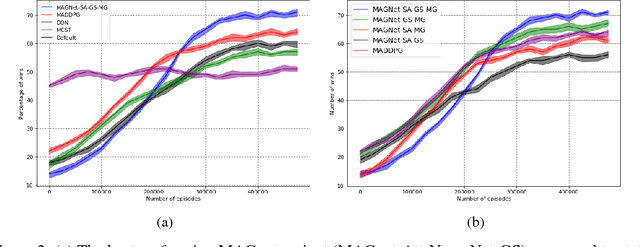
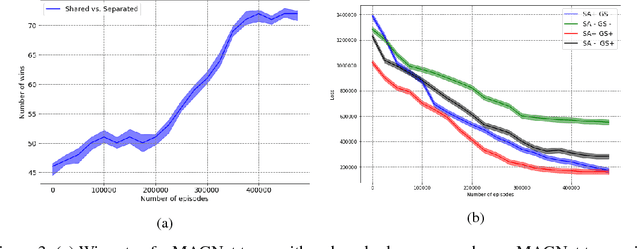
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGnet, to multi-agent reinforcement learning (MARL) that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique inspired by the NerveNet architecture. We applied our MAGnet approach to the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including DQN, MADDPG, and MCTS.