 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022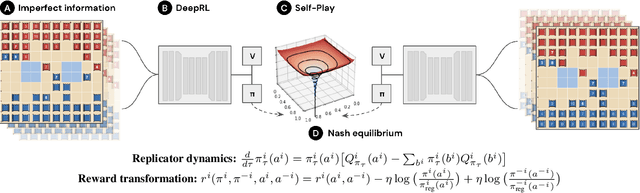
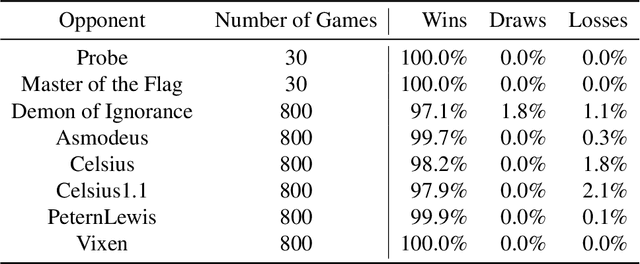
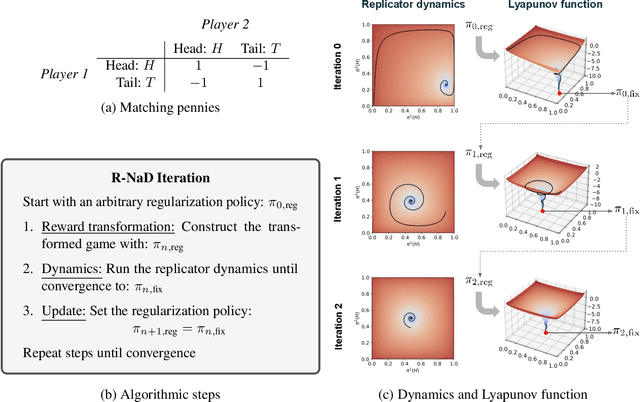

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
End-to-end Deep Object Tracking with Circular Loss Function for Rotated Bounding Box
Dec 17, 2020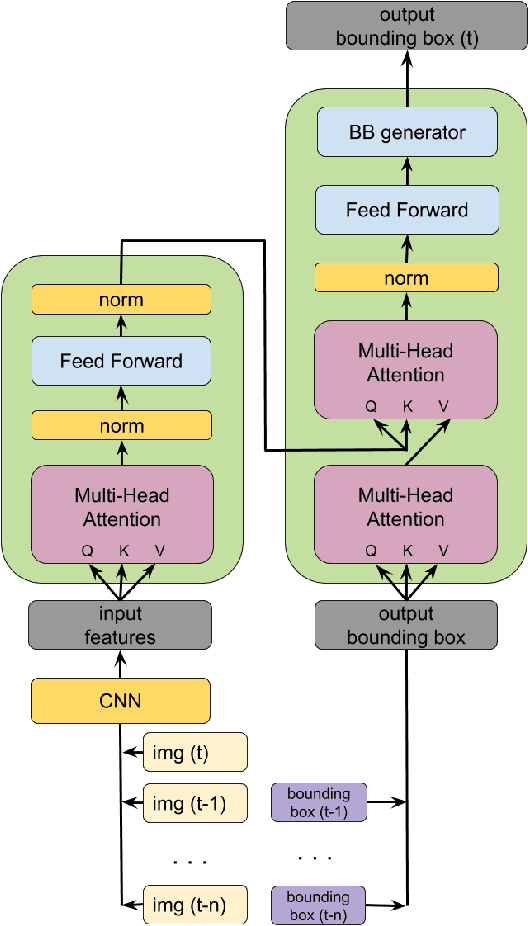
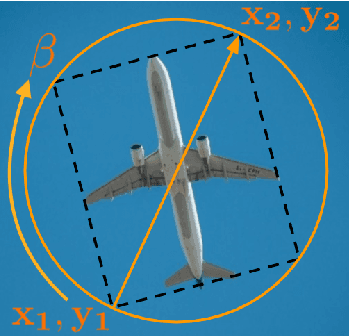
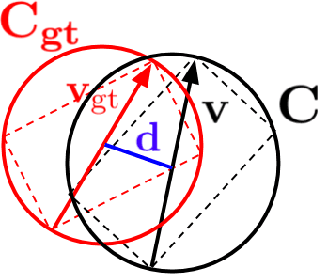

The task object tracking is vital in numerous applications such as autonomous driving, intelligent surveillance, robotics, etc. This task entails the assigning of a bounding box to an object in a video stream, given only the bounding box for that object on the first frame. In 2015, a new type of video object tracking (VOT) dataset was created that introduced rotated bounding boxes as an extension of axis-aligned ones. In this work, we introduce a novel end-to-end deep learning method based on the Transformer Multi-Head Attention architecture. We also present a new type of loss function, which takes into account the bounding box overlap and orientation. Our Deep Object Tracking model with Circular Loss Function (DOTCL) shows an considerable improvement in terms of robustness over current state-of-the-art end-to-end deep learning models. It also outperforms state-of-the-art object tracking methods on VOT2018 dataset in terms of expected average overlap (EAO) metric.
MAGNet: Multi-agent Graph Network for Deep Multi-agent Reinforcement Learning
Dec 17, 2020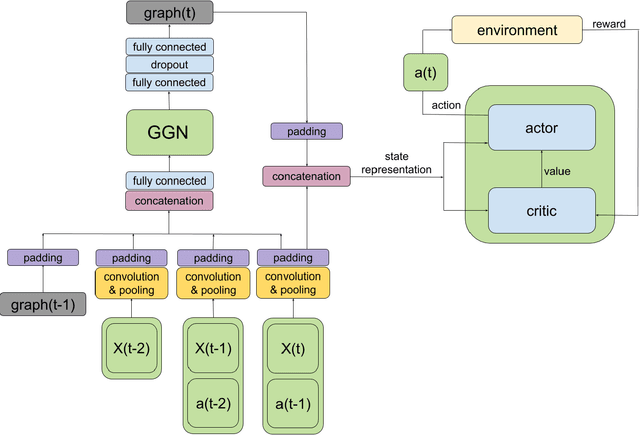
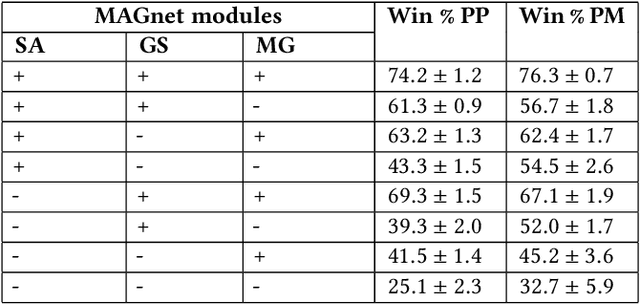

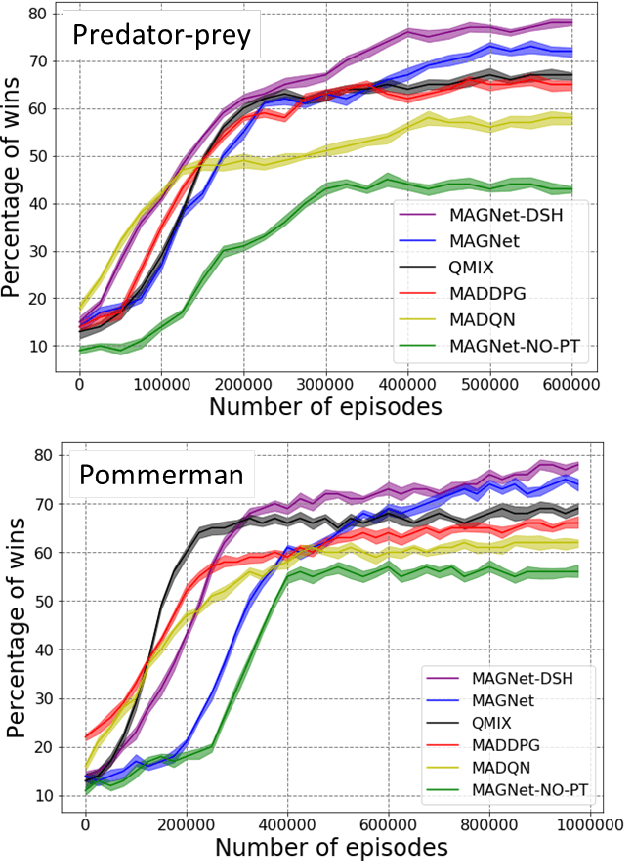
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGNet, to multi-agent reinforcement learning that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique. We applied our MAGnet approach to the synthetic predator-prey multi-agent environment and the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including Multi-agent Deep Q-Networks (MADQN), Multi-agent Deep Deterministic Policy Gradient (MADDPG), and QMIX
Learning to Run with Potential-Based Reward Shaping and Demonstrations from Video Data
Dec 16, 2020

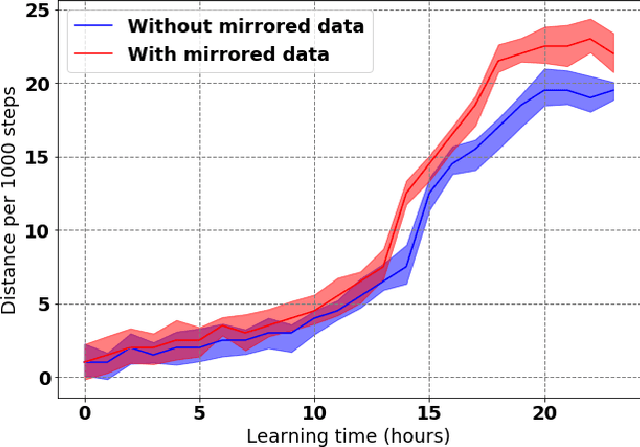
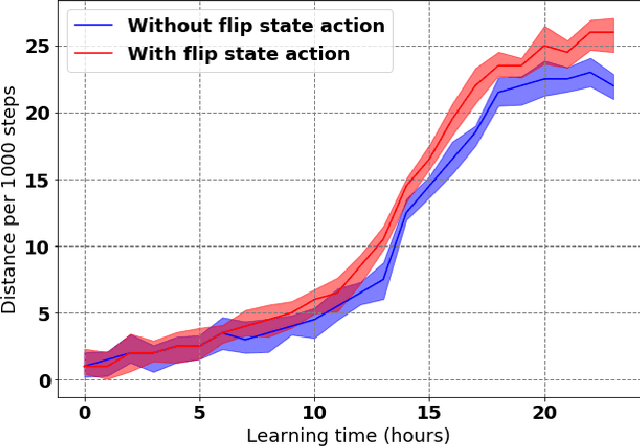
Learning to produce efficient movement behaviour for humanoid robots from scratch is a hard problem, as has been illustrated by the "Learning to run" competition at NIPS 2017. The goal of this competition was to train a two-legged model of a humanoid body to run in a simulated race course with maximum speed. All submissions took a tabula rasa approach to reinforcement learning (RL) and were able to produce relatively fast, but not optimal running behaviour. In this paper, we demonstrate how data from videos of human running (e.g. taken from YouTube) can be used to shape the reward of the humanoid learning agent to speed up the learning and produce a better result. Specifically, we are using the positions of key body parts at regular time intervals to define a potential function for potential-based reward shaping (PBRS). Since PBRS does not change the optimal policy, this approach allows the RL agent to overcome sub-optimalities in the human movements that are shown in the videos. We present experiments in which we combine selected techniques from the top ten approaches from the NIPS competition with further optimizations to create an high-performing agent as a baseline. We then demonstrate how video-based reward shaping improves the performance further, resulting in an RL agent that runs twice as fast as the baseline in 12 hours of training. We furthermore show that our approach can overcome sub-optimal running behaviour in videos, with the learned policy significantly outperforming that of the running agent from the video.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
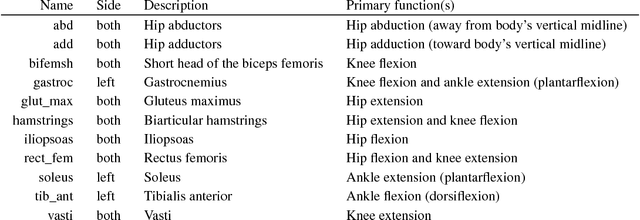
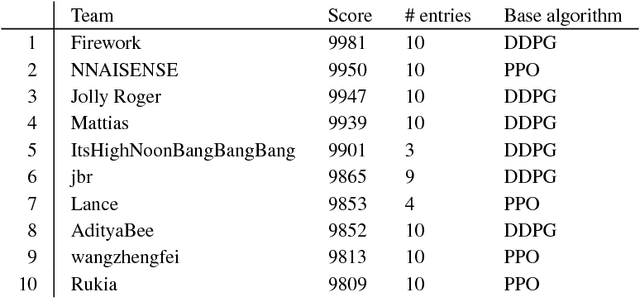

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Deep Multi-Agent Reinforcement Learning with Relevance Graphs
Nov 30, 2018

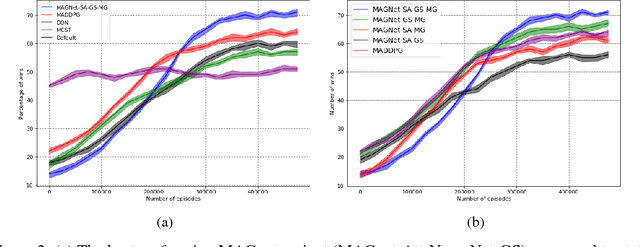
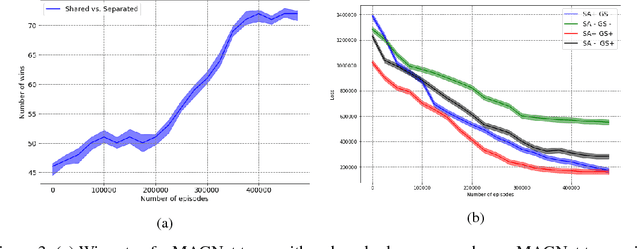
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGnet, to multi-agent reinforcement learning (MARL) that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique inspired by the NerveNet architecture. We applied our MAGnet approach to the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including DQN, MADDPG, and MCTS.