 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Evolutionary Trajectory Generator: A General Approach for Quadrupedal Locomotion
Sep 16, 2021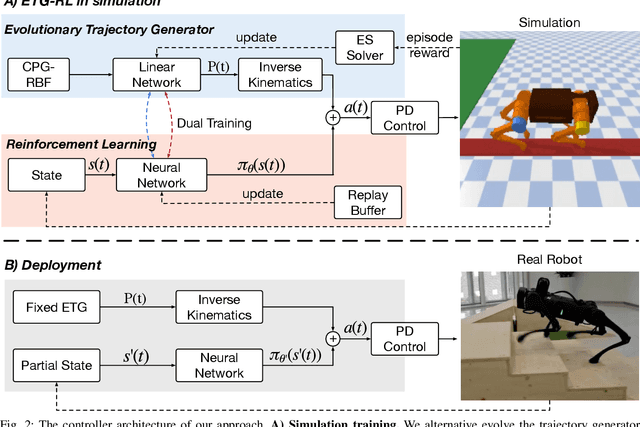
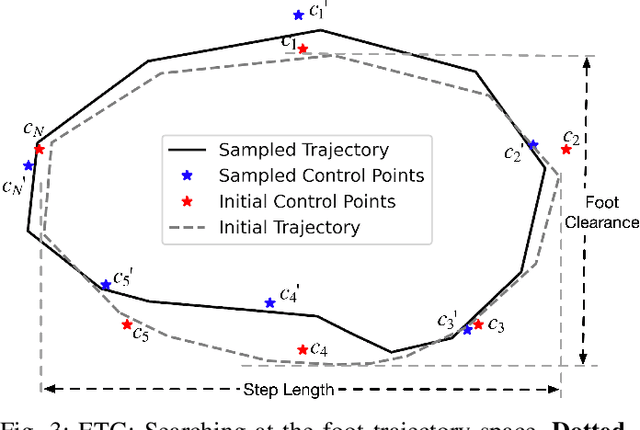
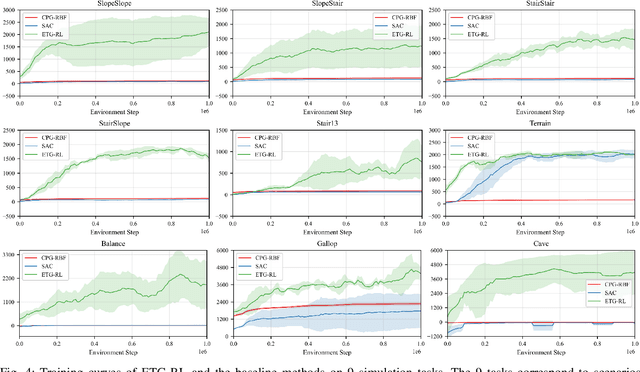
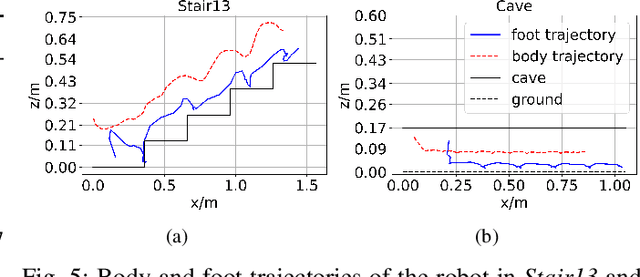
Recently reinforcement learning (RL) has emerged as a promising approach for quadrupedal locomotion, which can save the manual effort in conventional approaches such as designing skill-specific controllers. However, due to the complex nonlinear dynamics in quadrupedal robots and reward sparsity, it is still difficult for RL to learn effective gaits from scratch, especially in challenging tasks such as walking over the balance beam. To alleviate such difficulty, we propose a novel RL-based approach that contains an evolutionary foot trajectory generator. Unlike prior methods that use a fixed trajectory generator, the generator continually optimizes the shape of the output trajectory for the given task, providing diversified motion priors to guide the policy learning. The policy is trained with reinforcement learning to output residual control signals that fit different gaits. We then optimize the trajectory generator and policy network alternatively to stabilize the training and share the exploratory data to improve sample efficiency. As a result, our approach can solve a range of challenging tasks in simulation by learning from scratch, including walking on a balance beam and crawling through the cave. To further verify the effectiveness of our approach, we deploy the controller learned in the simulation on a 12-DoF quadrupedal robot, and it can successfully traverse challenging scenarios with efficient gaits.
ADER:Adapting between Exploration and Robustness for Actor-Critic Methods
Sep 08, 2021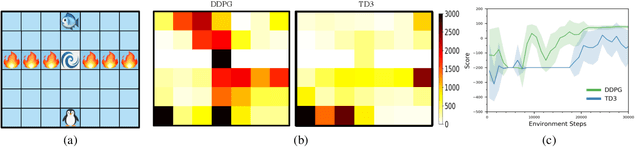
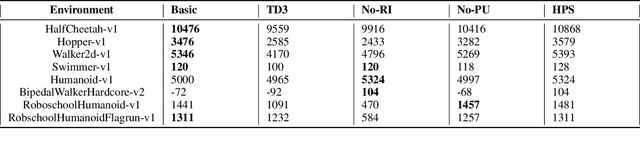

Combining off-policy reinforcement learning methods with function approximators such as neural networks has been found to lead to overestimation of the value function and sub-optimal solutions. Improvement such as TD3 has been proposed to address this issue. However, we surprisingly find that its performance lags behind the vanilla actor-critic methods (such as DDPG) in some primitive environments. In this paper, we show that the failure of some cases can be attributed to insufficient exploration. We reveal the culprit of insufficient exploration in TD3, and propose a novel algorithm toward this problem that ADapts between Exploration and Robustness, namely ADER. To enhance the exploration ability while eliminating the overestimation bias, we introduce a dynamic penalty term in value estimation calculated from estimated uncertainty, which takes into account different compositions of the uncertainty in different learning stages. Experiments in several challenging environments demonstrate the supremacy of the proposed method in continuous control tasks.
Action Set Based Policy Optimization for Safe Power Grid Management
Jun 29, 2021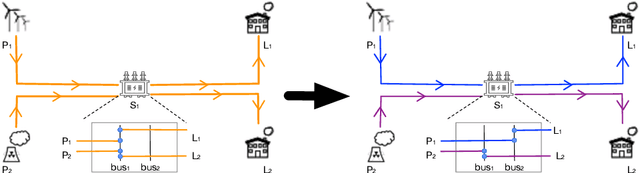

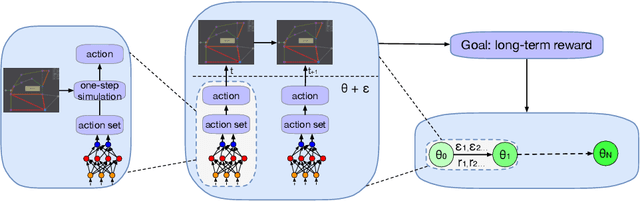

Maintaining the stability of the modern power grid is becoming increasingly difficult due to fluctuating power consumption, unstable power supply coming from renewable energies, and unpredictable accidents such as man-made and natural disasters. As the operation on the power grid must consider its impact on future stability, reinforcement learning (RL) has been employed to provide sequential decision-making in power grid management. However, existing methods have not considered the environmental constraints. As a result, the learned policy has risk of selecting actions that violate the constraints in emergencies, which will escalate the issue of overloaded power lines and lead to large-scale blackouts. In this work, we propose a novel method for this problem, which builds on top of the search-based planning algorithm. At the planning stage, the search space is limited to the action set produced by the policy. The selected action strictly follows the constraints by testing its outcome with the simulation function provided by the system. At the learning stage, to address the problem that gradients cannot be propagated to the policy, we introduce Evolutionary Strategies (ES) with black-box policy optimization to improve the policy directly, maximizing the returns of the long run. In NeurIPS 2020 Learning to Run Power Network (L2RPN) competition, our solution safely managed the power grid and ranked first in both tracks.
Efficient and Robust Reinforcement Learning with Uncertainty-based Value Expansion
Dec 10, 2019



By integrating dynamics models into model-free reinforcement learning (RL) methods, model-based value expansion (MVE) algorithms have shown a significant advantage in sample efficiency as well as value estimation. However, these methods suffer from higher function approximation errors than model-free methods in stochastic environments due to a lack of modeling the environmental randomness. As a result, their performance lags behind the best model-free algorithms in some challenging scenarios. In this paper, we propose a novel Hybrid-RL method that builds on MVE, namely the Risk Averse Value Expansion (RAVE). With imaginative rollouts generated by an ensemble of probabilistic dynamics models, we further introduce the aversion of risks by seeking the lower confidence bound of the estimation. Experiments on a range of challenging environments show that by modeling the uncertainty completely, RAVE substantially enhances the robustness of previous model-based methods, and yields state-of-the-art performance. With this technique, our solution gets the first place in NeurIPS 2019: Learn to Move.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
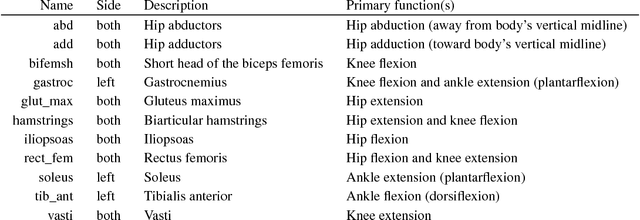
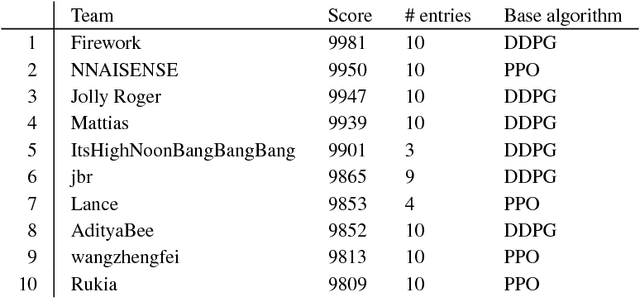

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.