 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
Jan 12, 2026Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.
Adaptive Termination for Multi-round Parallel Reasoning: An Universal Semantic Entropy-Guided Framework
Jul 09, 2025Recent advances in large language models (LLMs) have accelerated progress toward artificial general intelligence, with inference-time scaling emerging as a key technique. Contemporary approaches leverage either sequential reasoning (iteratively extending chains of thought) or parallel reasoning (generating multiple solutions simultaneously) to scale inference. However, both paradigms face fundamental limitations: sequential scaling typically relies on arbitrary token budgets for termination, leading to inefficiency or premature cutoff; while parallel scaling often lacks coordination among parallel branches and requires intrusive fine-tuning to perform effectively. In light of these challenges, we aim to design a flexible test-time collaborative inference framework that exploits the complementary strengths of both sequential and parallel reasoning paradigms. Towards this goal, the core challenge lies in developing an efficient and accurate intrinsic quality metric to assess model responses during collaborative inference, enabling dynamic control and early termination of the reasoning trace. To address this challenge, we introduce semantic entropy (SE), which quantifies the semantic diversity of parallel model responses and serves as a robust indicator of reasoning quality due to its strong negative correlation with accuracy...
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
ADER:Adapting between Exploration and Robustness for Actor-Critic Methods
Sep 08, 2021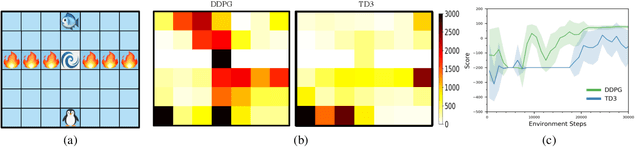

Combining off-policy reinforcement learning methods with function approximators such as neural networks has been found to lead to overestimation of the value function and sub-optimal solutions. Improvement such as TD3 has been proposed to address this issue. However, we surprisingly find that its performance lags behind the vanilla actor-critic methods (such as DDPG) in some primitive environments. In this paper, we show that the failure of some cases can be attributed to insufficient exploration. We reveal the culprit of insufficient exploration in TD3, and propose a novel algorithm toward this problem that ADapts between Exploration and Robustness, namely ADER. To enhance the exploration ability while eliminating the overestimation bias, we introduce a dynamic penalty term in value estimation calculated from estimated uncertainty, which takes into account different compositions of the uncertainty in different learning stages. Experiments in several challenging environments demonstrate the supremacy of the proposed method in continuous control tasks.
Action Set Based Policy Optimization for Safe Power Grid Management
Jun 29, 2021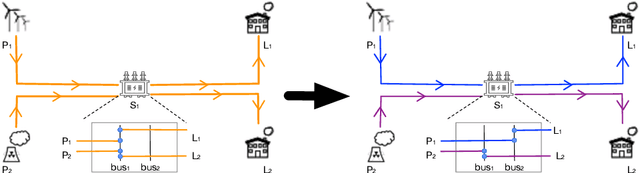

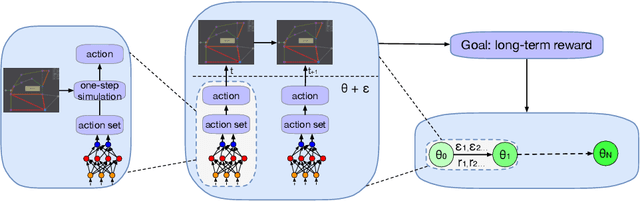

Maintaining the stability of the modern power grid is becoming increasingly difficult due to fluctuating power consumption, unstable power supply coming from renewable energies, and unpredictable accidents such as man-made and natural disasters. As the operation on the power grid must consider its impact on future stability, reinforcement learning (RL) has been employed to provide sequential decision-making in power grid management. However, existing methods have not considered the environmental constraints. As a result, the learned policy has risk of selecting actions that violate the constraints in emergencies, which will escalate the issue of overloaded power lines and lead to large-scale blackouts. In this work, we propose a novel method for this problem, which builds on top of the search-based planning algorithm. At the planning stage, the search space is limited to the action set produced by the policy. The selected action strictly follows the constraints by testing its outcome with the simulation function provided by the system. At the learning stage, to address the problem that gradients cannot be propagated to the policy, we introduce Evolutionary Strategies (ES) with black-box policy optimization to improve the policy directly, maximizing the returns of the long run. In NeurIPS 2020 Learning to Run Power Network (L2RPN) competition, our solution safely managed the power grid and ranked first in both tracks.