 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context Compression with Interleaved Vision-Text Transformation
Jan 15, 2026Recent achievements of vision-language models in end-to-end OCR point to a new avenue for low-loss compression of textual information. This motivates earlier works that render the Transformer's input into images for prefilling, which effectively reduces the number of tokens through visual encoding, thereby alleviating the quadratically increased Attention computations. However, this partial compression fails to save computational or memory costs at token-by-token inference. In this paper, we investigate global context compression, which saves tokens at both prefilling and inference stages. Consequently, we propose VIST2, a novel Transformer that interleaves input text chunks alongside their visual encoding, while depending exclusively on visual tokens in the pre-context to predict the next text token distribution. Around this idea, we render text chunks into sketch images and train VIST2 in multiple stages, starting from curriculum-scheduled pretraining for optical language modeling, followed by modal-interleaved instruction tuning. We conduct extensive experiments using VIST2 families scaled from 0.6B to 8B to explore the training recipe and hyperparameters. With a 4$\times$ compression ratio, the resulting models demonstrate significant superiority over baselines on long writing tasks, achieving, on average, a 3$\times$ speedup in first-token generation, 77% reduction in memory usage, and 74% reduction in FLOPS. Our codes and datasets will be public to support further studies.
EOC-Bench: Can MLLMs Identify, Recall, and Forecast Objects in an Egocentric World?
Jun 05, 2025



The emergence of multimodal large language models (MLLMs) has driven breakthroughs in egocentric vision applications. These applications necessitate persistent, context-aware understanding of objects, as users interact with tools in dynamic and cluttered environments. However, existing embodied benchmarks primarily focus on static scene exploration, emphasizing object's appearance and spatial attributes while neglecting the assessment of dynamic changes arising from users' interactions. To address this gap, we introduce EOC-Bench, an innovative benchmark designed to systematically evaluate object-centric embodied cognition in dynamic egocentric scenarios. Specially, EOC-Bench features 3,277 meticulously annotated QA pairs categorized into three temporal categories: Past, Present, and Future, covering 11 fine-grained evaluation dimensions and 3 visual object referencing types. To ensure thorough assessment, we develop a mixed-format human-in-the-loop annotation framework with four types of questions and design a novel multi-scale temporal accuracy metric for open-ended temporal evaluation. Based on EOC-Bench, we conduct comprehensive evaluations of various proprietary, open-source, and object-level MLLMs. EOC-Bench serves as a crucial tool for advancing the embodied object cognitive capabilities of MLLMs, establishing a robust foundation for developing reliable core models for embodied systems.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Align$^2$LLaVA: Cascaded Human and Large Language Model Preference Alignment for Multi-modal Instruction Curation
Sep 27, 2024



Recent advances in Multi-modal Large Language Models (MLLMs), such as LLaVA-series models, are driven by massive machine-generated instruction-following data tuning. Such automatic instruction collection pipelines, however, inadvertently introduce significant variability in data quality. This paper introduces a novel instruction curation algorithm, derived from two unique perspectives, human and LLM preference alignment, to compress this vast corpus of machine-generated multimodal instructions to a compact and high-quality form: (i) For human preference alignment, we have collected a machine-generated multimodal instruction dataset and established a comprehensive set of both subjective and objective criteria to guide the data quality assessment critically from human experts. By doing so, a reward model was trained on the annotated dataset to internalize the nuanced human understanding of instruction alignment. (ii) For LLM preference alignment, given the instruction selected by the reward model, we propose leveraging the inner LLM used in MLLM to align the writing style of visual instructions with that of the inner LLM itself, resulting in LLM-aligned instruction improvement. Extensive experiments demonstrate that we can maintain or even improve model performance by compressing synthetic multimodal instructions by up to 90%. Impressively, by aggressively reducing the total training sample size from 158k to 14k (9$\times$ smaller), our model consistently outperforms its full-size dataset counterpart across various MLLM benchmarks. Our project is available at https://github.com/DCDmllm/Align2LLaVA.
Efficiently Training 7B LLM with 1 Million Sequence Length on 8 GPUs
Jul 16, 2024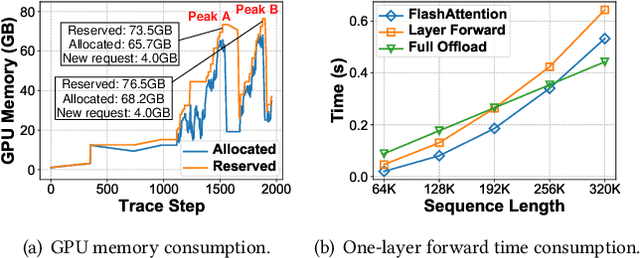

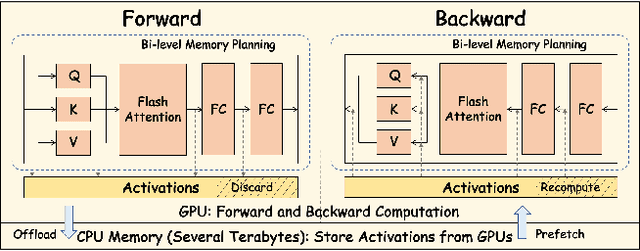
Nowadays, Large Language Models (LLMs) have been trained using extended context lengths to foster more creative applications. However, long context training poses great challenges considering the constraint of GPU memory. It not only leads to substantial activation memory consumption during training, but also incurs considerable memory fragmentation. To facilitate long context training, existing frameworks have adopted strategies such as recomputation and various forms of parallelisms. Nevertheless, these techniques rely on redundant computation or extensive communication, resulting in low Model FLOPS Utilization (MFU). In this paper, we propose MEMO, a novel LLM training framework designed for fine-grained activation memory management. Given the quadratic scaling of computation and linear scaling of memory with sequence lengths when using FlashAttention, we offload memory-consuming activations to CPU memory after each layer's forward pass and fetch them during the backward pass. To maximize the swapping of activations without hindering computation, and to avoid exhausting limited CPU memory, we implement a token-wise activation recomputation and swapping mechanism. Furthermore, we tackle the memory fragmentation issue by employing a bi-level Mixed Integer Programming (MIP) approach, optimizing the reuse of memory across transformer layers. Empirical results demonstrate that MEMO achieves an average of 2.42x and 2.26x MFU compared to Megatron-LM and DeepSpeed, respectively. This improvement is attributed to MEMO's ability to minimize memory fragmentation, reduce recomputation and intensive communication, and circumvent the delays associated with the memory reorganization process due to fragmentation. By leveraging fine-grained activation memory management, MEMO facilitates efficient training of 7B LLM with 1 million sequence length on just 8 A800 GPUs, achieving an MFU of 52.30%.
IDEAL: Leveraging Infinite and Dynamic Characterizations of Large Language Models for Query-focused Summarization
Jul 15, 2024
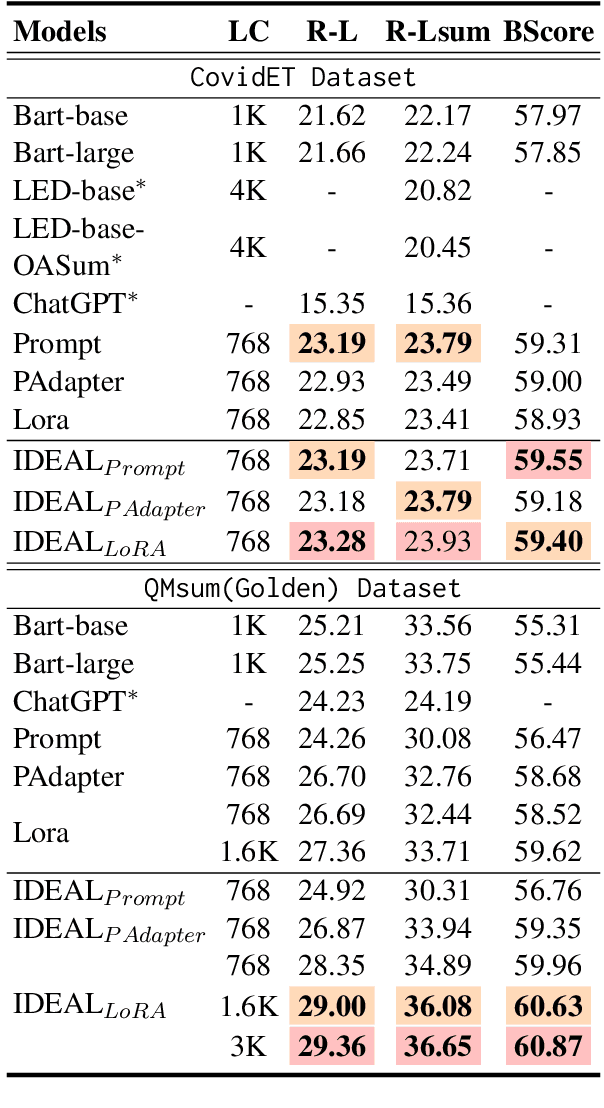
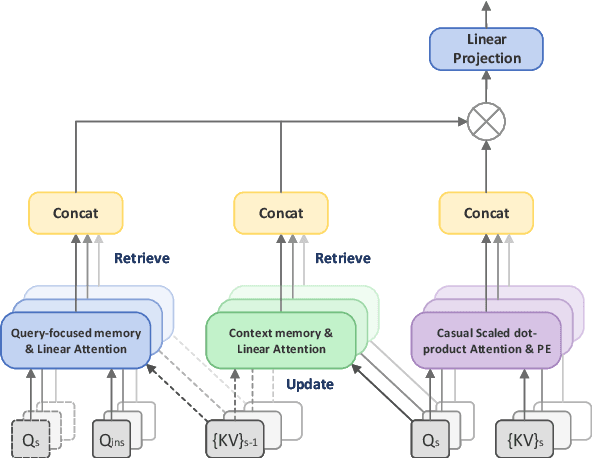
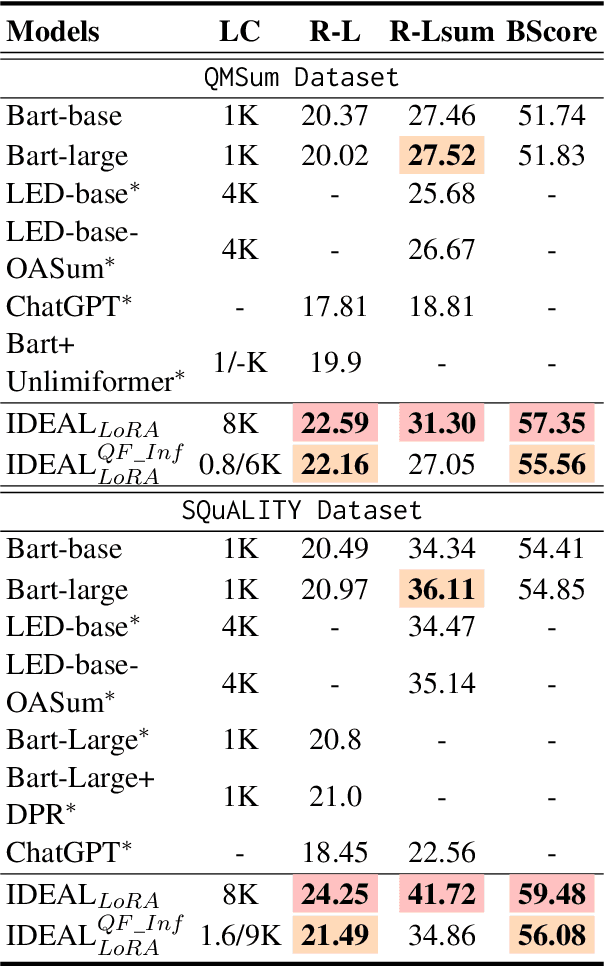
Query-focused summarization (QFS) aims to produce summaries that answer particular questions of interest, enabling greater user control and personalization. With the advent of large language models (LLMs), shows their impressive capability of textual understanding through large-scale pretraining, which implies the great potential of extractive snippet generation. In this paper, we systematically investigated two indispensable characteristics that the LLMs-based QFS models should be harnessed, Lengthy Document Summarization and Efficiently Fine-grained Query-LLM Alignment, respectively. Correspondingly, we propose two modules called Query-aware HyperExpert and Query-focused Infini-attention to access the aforementioned characteristics. These innovations pave the way for broader application and accessibility in the field of QFS technology. Extensive experiments conducted on existing QFS benchmarks indicate the effectiveness and generalizability of the proposed approach. Our code is publicly available at https://github.com/DCDmllm/IDEAL_Summary.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
May 23, 2024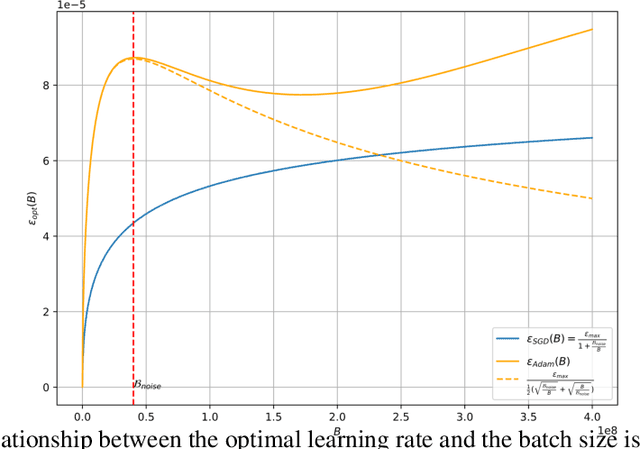
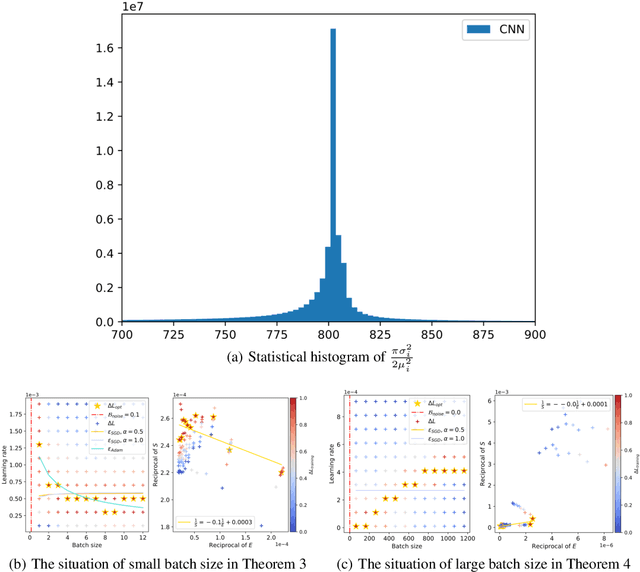
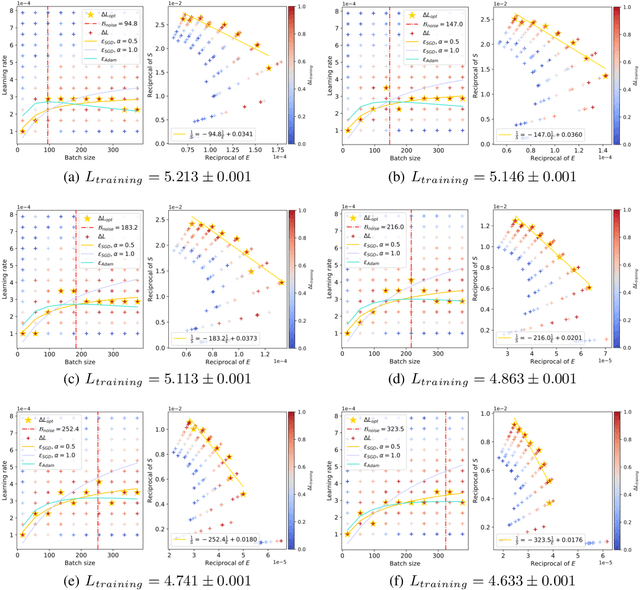
In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
Angel-PTM: A Scalable and Economical Large-scale Pre-training System in Tencent
Mar 06, 2023



Recent years have witnessed the unprecedented achievements of large-scale pre-trained models, especially the Transformer models. Many products and services in Tencent Inc., such as WeChat, QQ, and Tencent Advertisement, have been opted in to gain the power of pre-trained models. In this work, we present Angel-PTM, a productive deep learning system designed for pre-training and fine-tuning Transformer models. Angel-PTM can train extremely large-scale models with hierarchical memory efficiently. The key designs of Angel-PTM are the fine-grained memory management via the Page abstraction and a unified scheduling method that coordinate the computations, data movements, and communications. Furthermore, Angel-PTM supports extreme model scaling with SSD storage and implements the lock-free updating mechanism to address the SSD I/O bandwidth bottlenecks. Experimental results demonstrate that Angel-PTM outperforms existing systems by up to 114.8% in terms of maximum model scale as well as up to 88.9% in terms of training throughput. Additionally, experiments on GPT3-175B and T5-MoE-1.2T models utilizing hundreds of GPUs verify the strong scalability of Angel-PTM.