 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJetFormer: A Scalable and Efficient Transformer for Jet Tagging from Offline Analysis to FPGA Triggers
Jan 23, 2026We present JetFormer, a versatile and scalable encoder-only Transformer architecture for particle jet tagging at the Large Hadron Collider (LHC). Unlike prior approaches that are often tailored to specific deployment regimes, JetFormer is designed to operate effectively across the full spectrum of jet tagging scenarios, from high-accuracy offline analysis to ultra-low-latency online triggering. The model processes variable-length sets of particle features without relying on input of explicit pairwise interactions, yet achieves competitive or superior performance compared to state-of-the-art methods. On the large-scale JetClass dataset, a large-scale JetFormer matches the accuracy of the interaction-rich ParT model (within 0.7%) while using 37.4% fewer FLOPs, demonstrating its computational efficiency and strong generalization. On benchmark HLS4ML 150P datasets, JetFormer consistently outperforms existing models such as MLPs, Deep Sets, and Interaction Networks by 3-4% in accuracy. To bridge the gap to hardware deployment, we further introduce a hardware-aware optimization pipeline based on multi-objective hyperparameter search, yielding compact variants like JetFormer-tiny suitable for FPGA-based trigger systems with sub-microsecond latency requirements. Through structured pruning and quantization, we show that JetFormer can be aggressively compressed with minimal accuracy loss. By unifying high-performance modeling and deployability within a single architectural framework, JetFormer provides a practical pathway for deploying Transformer-based jet taggers in both offline and online environments at the LHC. Code is available at https://github.com/walkieq/JetFormer.
EveNet: A Foundation Model for Particle Collision Data Analysis
Jan 23, 2026While deep learning is transforming data analysis in high-energy physics, computational challenges limit its potential. We address these challenges in the context of collider physics by introducing EveNet, an event-level foundation model pretrained on 500 million simulated collision events using a hybrid objective of self-supervised learning and physics-informed supervision. By leveraging a shared particle-cloud representation, EveNet outperforms state-of-the-art baselines across diverse tasks, including searches for heavy resonances and exotic Higgs decays, and demonstrates exceptional data efficiency in low-statistics regimes. Crucially, we validate the transferability of the model to experimental data by rediscovering the $Υ$ meson in CMS Open Data and show its capacity for precision physics through the robust extraction of quantum correlation observables stable against systematic uncertainties. These results indicate that EveNet can successfully encode the fundamental physical structure of particle interactions, which offers a unified and resource-efficient framework to accelerate discovery at current and future colliders.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024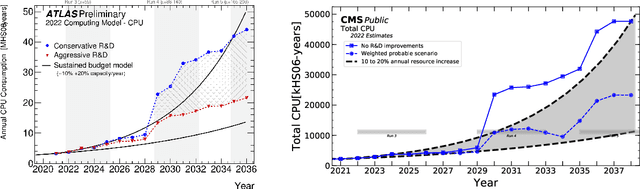
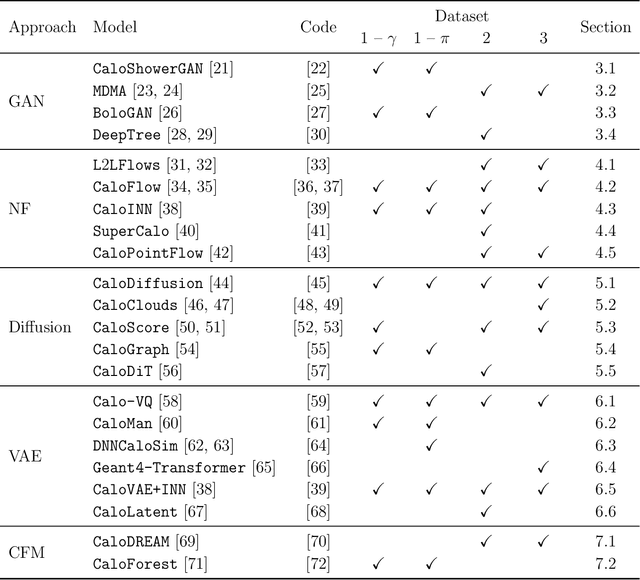
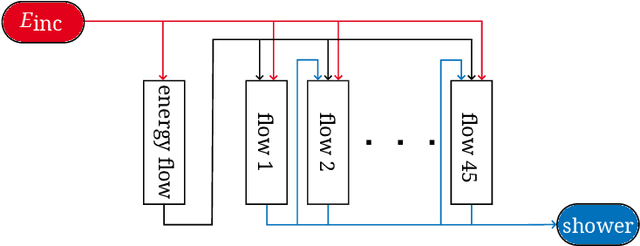
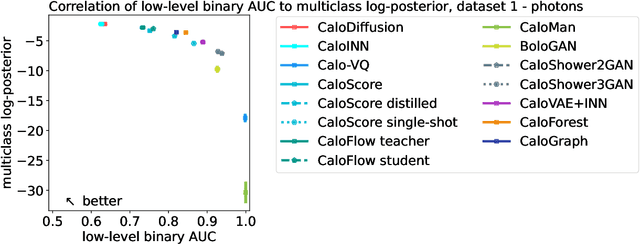
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Efficiently Training 7B LLM with 1 Million Sequence Length on 8 GPUs
Jul 16, 2024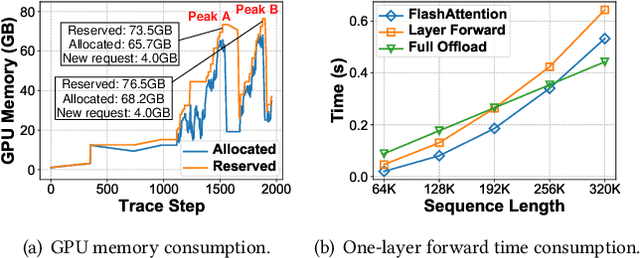

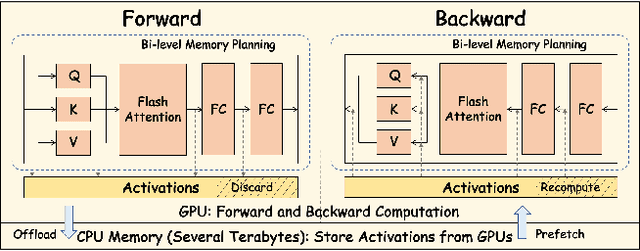
Nowadays, Large Language Models (LLMs) have been trained using extended context lengths to foster more creative applications. However, long context training poses great challenges considering the constraint of GPU memory. It not only leads to substantial activation memory consumption during training, but also incurs considerable memory fragmentation. To facilitate long context training, existing frameworks have adopted strategies such as recomputation and various forms of parallelisms. Nevertheless, these techniques rely on redundant computation or extensive communication, resulting in low Model FLOPS Utilization (MFU). In this paper, we propose MEMO, a novel LLM training framework designed for fine-grained activation memory management. Given the quadratic scaling of computation and linear scaling of memory with sequence lengths when using FlashAttention, we offload memory-consuming activations to CPU memory after each layer's forward pass and fetch them during the backward pass. To maximize the swapping of activations without hindering computation, and to avoid exhausting limited CPU memory, we implement a token-wise activation recomputation and swapping mechanism. Furthermore, we tackle the memory fragmentation issue by employing a bi-level Mixed Integer Programming (MIP) approach, optimizing the reuse of memory across transformer layers. Empirical results demonstrate that MEMO achieves an average of 2.42x and 2.26x MFU compared to Megatron-LM and DeepSpeed, respectively. This improvement is attributed to MEMO's ability to minimize memory fragmentation, reduce recomputation and intensive communication, and circumvent the delays associated with the memory reorganization process due to fragmentation. By leveraging fine-grained activation memory management, MEMO facilitates efficient training of 7B LLM with 1 million sequence length on just 8 A800 GPUs, achieving an MFU of 52.30%.
Calo-VQ: Vector-Quantized Two-Stage Generative Model in Calorimeter Simulation
May 10, 2024We introduce a novel machine learning method developed for the fast simulation of calorimeter detector response, adapting vector-quantized variational autoencoder (VQ-VAE). Our model adopts a two-stage generation strategy: initially compressing geometry-aware calorimeter data into a discrete latent space, followed by the application of a sequence model to learn and generate the latent tokens. Extensive experimentation on the Calo-challenge dataset underscores the efficiency of our approach, showcasing a remarkable improvement in the generation speed compared with conventional method by a factor of 2000. Remarkably, our model achieves the generation of calorimeter showers within milliseconds. Furthermore, comprehensive quantitative evaluations across various metrics are performed to validate physics performance of generation.