 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuMask: Diffusion Language Model for Token-level Prompt Pruning
Apr 08, 2026In-Context Learning and Chain-of-Thought prompting improve reasoning in large language models (LLMs). These typically come at the cost of longer, more expensive prompts that may contain redundant information. Prompt compression based on pruning offers a practical solution, yet existing methods rely on sequential token removal which is computationally intensive. We present DiffuMask, a diffusion-based framework integrating hierarchical shot-level and token-level pruning signals, that enables rapid and parallel prompt pruning via iterative mask prediction. DiffuMask substantially accelerates the compression process via masking multiple tokens in each denoising step. It offers tunable control over retained content, preserving essential reasoning context and achieving up to 80\% prompt length reduction. Meanwhile, it maintains or improves accuracy across in-domain, out-of-domain, and cross-model settings. Our results show that DiffuMask provides a generalizable and controllable framework for prompt compression, facilitating faster and more reliable in-context reasoning in LLMs.
RPNT: Robust Pre-trained Neural Transformer -- A Pathway for Generalized Motor Decoding
Jan 25, 2026Brain decoding aims to interpret and translate neural activity into behaviors. As such, it is imperative that decoding models are able to generalize across variations, such as recordings from different brain sites, distinct sessions, different types of behavior, and a variety of subjects. Current models can only partially address these challenges and warrant the development of pretrained neural transformer models capable to adapt and generalize. In this work, we propose RPNT - Robust Pretrained Neural Transformer, designed to achieve robust generalization through pretraining, which in turn enables effective finetuning given a downstream task. In particular, RPNT unique components include 1) Multidimensional rotary positional embedding (MRoPE) to aggregate experimental metadata such as site coordinates, session name and behavior types; 2) Context-based attention mechanism via convolution kernels operating on global attention to learn local temporal structures for handling non-stationarity of neural population activity; 3) Robust self-supervised learning (SSL) objective with uniform causal masking strategies and contrastive representations. We pretrained two separate versions of RPNT on distinct datasets a) Multi-session, multi-task, and multi-subject microelectrode benchmark; b) Multi-site recordings using high-density Neuropixel 1.0 probes. The datasets include recordings from the dorsal premotor cortex (PMd) and from the primary motor cortex (M1) regions of nonhuman primates (NHPs) as they performed reaching tasks. After pretraining, we evaluated the generalization of RPNT in cross-session, cross-type, cross-subject, and cross-site downstream behavior decoding tasks. Our results show that RPNT consistently achieves and surpasses the decoding performance of existing decoding models in all tasks.
Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
Neural Tangent Knowledge Distillation for Optical Convolutional Networks
Aug 11, 2025Hybrid Optical Neural Networks (ONNs, typically consisting of an optical frontend and a digital backend) offer an energy-efficient alternative to fully digital deep networks for real-time, power-constrained systems. However, their adoption is limited by two main challenges: the accuracy gap compared to large-scale networks during training, and discrepancies between simulated and fabricated systems that further degrade accuracy. While previous work has proposed end-to-end optimizations for specific datasets (e.g., MNIST) and optical systems, these approaches typically lack generalization across tasks and hardware designs. To address these limitations, we propose a task-agnostic and hardware-agnostic pipeline that supports image classification and segmentation across diverse optical systems. To assist optical system design before training, we estimate achievable model accuracy based on user-specified constraints such as physical size and the dataset. For training, we introduce Neural Tangent Knowledge Distillation (NTKD), which aligns optical models with electronic teacher networks, thereby narrowing the accuracy gap. After fabrication, NTKD also guides fine-tuning of the digital backend to compensate for implementation errors. Experiments on multiple datasets (e.g., MNIST, CIFAR, Carvana Masking) and hardware configurations show that our pipeline consistently improves ONN performance and enables practical deployment in both pre-fabrication simulations and physical implementations.
KPFlow: An Operator Perspective on Dynamic Collapse Under Gradient Descent Training of Recurrent Networks
Jul 08, 2025
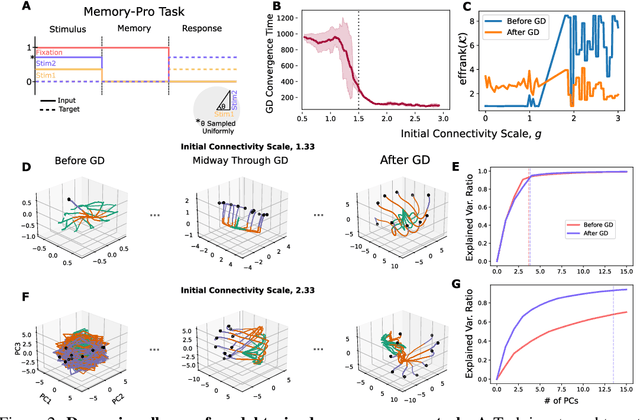

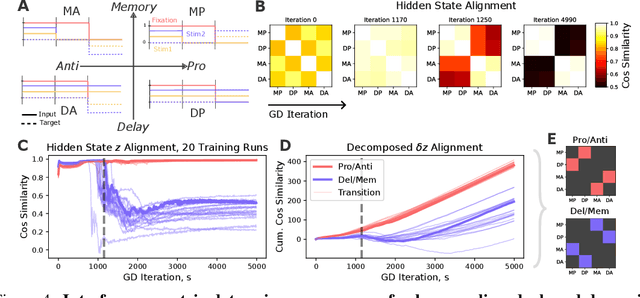
Gradient Descent (GD) and its variants are the primary tool for enabling efficient training of recurrent dynamical systems such as Recurrent Neural Networks (RNNs), Neural ODEs and Gated Recurrent units (GRUs). The dynamics that are formed in these models exhibit features such as neural collapse and emergence of latent representations that may support the remarkable generalization properties of networks. In neuroscience, qualitative features of these representations are used to compare learning in biological and artificial systems. Despite recent progress, there remains a need for theoretical tools to rigorously understand the mechanisms shaping learned representations, especially in finite, non-linear models. Here, we show that the gradient flow, which describes how the model's dynamics evolve over GD, can be decomposed into a product that involves two operators: a Parameter Operator, K, and a Linearized Flow Propagator, P. K mirrors the Neural Tangent Kernel in feed-forward neural networks, while P appears in Lyapunov stability and optimal control theory. We demonstrate two applications of our decomposition. First, we show how their interplay gives rise to low-dimensional latent dynamics under GD, and, specifically, how the collapse is a result of the network structure, over and above the nature of the underlying task. Second, for multi-task training, we show that the operators can be used to measure how objectives relevant to individual sub-tasks align. We experimentally and theoretically validate these findings, providing an efficient Pytorch package, \emph{KPFlow}, implementing robust analysis tools for general recurrent architectures. Taken together, our work moves towards building a next stage of understanding of GD learning in non-linear recurrent models.
Hyperpruning: Efficient Search through Pruned Variants of Recurrent Neural Networks Leveraging Lyapunov Spectrum
Jun 09, 2025

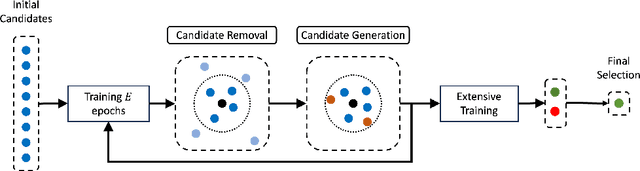

A variety of pruning methods have been introduced for over-parameterized Recurrent Neural Networks to improve efficiency in terms of power consumption and storage utilization. These advances motivate a new paradigm, termed `hyperpruning', which seeks to identify the most suitable pruning strategy for a given network architecture and application. Unlike conventional hyperparameter search, where the optimal configuration's accuracy remains uncertain, in the context of network pruning, the accuracy of the dense model sets the target for the accuracy of the pruned one. The goal, therefore, is to discover pruned variants that match or even surpass this established accuracy. However, exhaustive search over pruning configurations is computationally expensive and lacks early performance guarantees. To address this challenge, we propose a novel Lyapunov Spectrum (LS)-based distance metric that enables early comparison between pruned and dense networks, allowing accurate prediction of post-training performance. By integrating this LS-based distance with standard hyperparameter optimization algorithms, we introduce an efficient hyperpruning framework, termed LS-based Hyperpruning (LSH). LSH reduces search time by an order of magnitude compared to conventional approaches relying on full training. Experiments on stacked LSTM and RHN architectures using the Penn Treebank dataset, and on AWD-LSTM-MoS using WikiText-2, demonstrate that under fixed training budgets and target pruning ratios, LSH consistently identifies superior pruned models. Remarkably, these pruned variants not only outperform those selected by loss-based baseline but also exceed the performance of their dense counterpart.
SAVVY: Spatial Awareness via Audio-Visual LLMs through Seeing and Hearing
Jun 04, 20253D spatial reasoning in dynamic, audio-visual environments is a cornerstone of human cognition yet remains largely unexplored by existing Audio-Visual Large Language Models (AV-LLMs) and benchmarks, which predominantly focus on static or 2D scenes. We introduce SAVVY-Bench, the first benchmark for 3D spatial reasoning in dynamic scenes with synchronized spatial audio. SAVVY-Bench is comprised of thousands of relationships involving static and moving objects, and requires fine-grained temporal grounding, consistent 3D localization, and multi-modal annotation. To tackle this challenge, we propose SAVVY, a novel training-free reasoning pipeline that consists of two stages: (i) Egocentric Spatial Tracks Estimation, which leverages AV-LLMs as well as other audio-visual methods to track the trajectories of key objects related to the query using both visual and spatial audio cues, and (ii) Dynamic Global Map Construction, which aggregates multi-modal queried object trajectories and converts them into a unified global dynamic map. Using the constructed map, a final QA answer is obtained through a coordinate transformation that aligns the global map with the queried viewpoint. Empirical evaluation demonstrates that SAVVY substantially enhances performance of state-of-the-art AV-LLMs, setting a new standard and stage for approaching dynamic 3D spatial reasoning in AV-LLMs.
Hearing Anywhere in Any Environment
Apr 14, 2025In mixed reality applications, a realistic acoustic experience in spatial environments is as crucial as the visual experience for achieving true immersion. Despite recent advances in neural approaches for Room Impulse Response (RIR) estimation, most existing methods are limited to the single environment on which they are trained, lacking the ability to generalize to new rooms with different geometries and surface materials. We aim to develop a unified model capable of reconstructing the spatial acoustic experience of any environment with minimum additional measurements. To this end, we present xRIR, a framework for cross-room RIR prediction. The core of our generalizable approach lies in combining a geometric feature extractor, which captures spatial context from panorama depth images, with a RIR encoder that extracts detailed acoustic features from only a few reference RIR samples. To evaluate our method, we introduce ACOUSTICROOMS, a new dataset featuring high-fidelity simulation of over 300,000 RIRs from 260 rooms. Experiments show that our method strongly outperforms a series of baselines. Furthermore, we successfully perform sim-to-real transfer by evaluating our model on four real-world environments, demonstrating the generalizability of our approach and the realism of our dataset.
SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding
Apr 08, 2025



We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.