 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Space NTK Collapse Near Bifurcations
May 12, 2026Rich feature learning in tasks that unfold over time often requires the model to pass through bifurcations, constituting qualitative changes in the underlying model dynamics. We develop a local theory of gradient descent near these transitions through the empirical state-space neural tangent kernel (sNTK). Our central finding is that bifurcations both dominate and simplify learning dynamics: near bifurcations, we can reduce sNTK to a rank-one operator corresponding to learning in a classical normal form system, providing an analytically tractable description of the local learning geometry, even for high-dimensional recurrent systems. Concretely, we give a procedure for decomposing sNTK into bifurcation-relevant and residual channels, showing that near commonly codimension-1 bifurcations the relevant channel is a rank-one operator that is highly amplified. This amplification causes the bifurcation channel to dominate the full sNTK. Thus, bifurcations locally warp the learning landscape, funneling gradient descent into a few critical dynamical directions and making the nearby kernel and loss geometry predictable from classical normal forms. We illustrate this in a student-teacher recurrent neural network: the first learned bifurcation coincides with a sharp collapse in sNTK effective rank and the emergence of a dominant parameter direction whose restricted sNTK closely matches the landscape predicted by the scalar pitchfork normal form. Finally, we show that low-rank natural gradient methods resolve the resulting learning instability near bifurcations with very little overhead over SGD.
Identifying Connectivity Distributions from Neural Dynamics Using Flows
Mar 27, 2026Connectivity structure shapes neural computation, but inferring this structure from population recordings is degenerate: multiple connectivity structures can generate identical dynamics. Recent work uses low-rank recurrent neural networks (lrRNNs) to infer low-dimensional latent dynamics and connectivity structure from observed activity, enabling a mechanistic interpretation of the dynamics. However, standard approaches for training lrRNNs can recover spurious structures irrelevant to the underlying dynamics. We first characterize the identifiability of connectivity structures in lrRNNs and determine conditions under which a unique solution exists. Then, to find such solutions, we develop an inference framework based on maximum entropy and continuous normalizing flows (CNFs), trained via flow matching. Instead of estimating a single connectivity matrix, our method learns the maximally unbiased distribution over connection weights consistent with observed dynamics. This approach captures complex yet necessary distributions such as heavy-tailed connectivity found in empirical data. We validate our method on synthetic datasets with connectivity structures that generate multistable attractors, limit cycles, and ring attractors, and demonstrate its applicability in recordings from rat frontal cortex during decision-making. Our framework shifts circuit inference from recovering connectivity to identifying which connectivity structures are computationally required, and which are artifacts of underconstrained inference.
KPFlow: An Operator Perspective on Dynamic Collapse Under Gradient Descent Training of Recurrent Networks
Jul 08, 2025
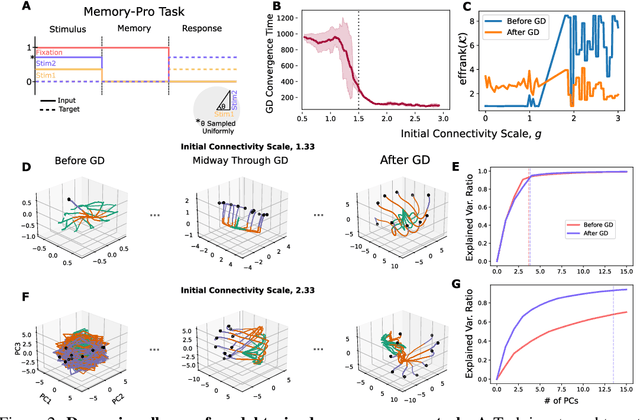

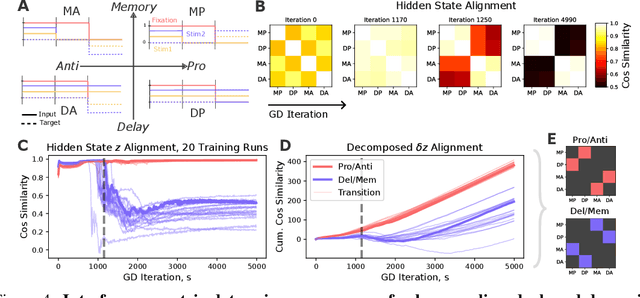
Gradient Descent (GD) and its variants are the primary tool for enabling efficient training of recurrent dynamical systems such as Recurrent Neural Networks (RNNs), Neural ODEs and Gated Recurrent units (GRUs). The dynamics that are formed in these models exhibit features such as neural collapse and emergence of latent representations that may support the remarkable generalization properties of networks. In neuroscience, qualitative features of these representations are used to compare learning in biological and artificial systems. Despite recent progress, there remains a need for theoretical tools to rigorously understand the mechanisms shaping learned representations, especially in finite, non-linear models. Here, we show that the gradient flow, which describes how the model's dynamics evolve over GD, can be decomposed into a product that involves two operators: a Parameter Operator, K, and a Linearized Flow Propagator, P. K mirrors the Neural Tangent Kernel in feed-forward neural networks, while P appears in Lyapunov stability and optimal control theory. We demonstrate two applications of our decomposition. First, we show how their interplay gives rise to low-dimensional latent dynamics under GD, and, specifically, how the collapse is a result of the network structure, over and above the nature of the underlying task. Second, for multi-task training, we show that the operators can be used to measure how objectives relevant to individual sub-tasks align. We experimentally and theoretically validate these findings, providing an efficient Pytorch package, \emph{KPFlow}, implementing robust analysis tools for general recurrent architectures. Taken together, our work moves towards building a next stage of understanding of GD learning in non-linear recurrent models.
Identifying the impact of local connectivity patterns on dynamics in excitatory-inhibitory networks
Nov 11, 2024



Networks of excitatory and inhibitory (EI) neurons form a canonical circuit in the brain. Seminal theoretical results on dynamics of such networks are based on the assumption that synaptic strengths depend on the type of neurons they connect, but are otherwise statistically independent. Recent synaptic physiology datasets however highlight the prominence of specific connectivity patterns that go well beyond what is expected from independent connections. While decades of influential research have demonstrated the strong role of the basic EI cell type structure, to which extent additional connectivity features influence dynamics remains to be fully determined. Here we examine the effects of pairwise connectivity motifs on the linear dynamics in EI networks using an analytical framework that approximates the connectivity in terms of low-rank structures. This low-rank approximation is based on a mathematical derivation of the dominant eigenvalues of the connectivity matrix and predicts the impact on responses to external inputs of connectivity motifs and their interactions with cell-type structure. Our results reveal that a particular pattern of connectivity, chain motifs, have a much stronger impact on dominant eigenmodes than other pairwise motifs. An overrepresentation of chain motifs induces a strong positive eigenvalue in inhibition-dominated networks and generates a potential instability that requires revisiting the classical excitation-inhibition balance criteria. Examining effects of external inputs, we show that chain motifs can on their own induce paradoxical responses where an increased input to inhibitory neurons leads to a decrease in their activity due to the recurrent feedback. These findings have direct implications for the interpretation of experiments in which responses to optogenetic perturbations are measured and used to infer the dynamical regime of cortical circuits.
Attention for Causal Relationship Discovery from Biological Neural Dynamics
Nov 23, 2023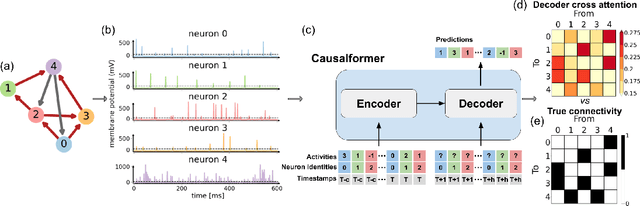

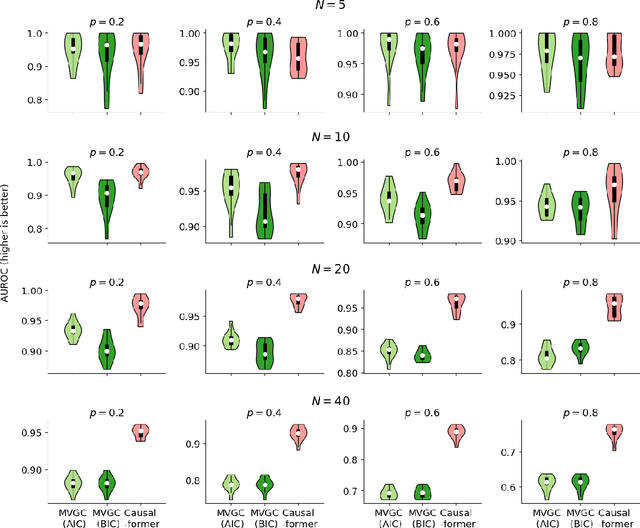

This paper explores the potential of the transformer models for learning Granger causality in networks with complex nonlinear dynamics at every node, as in neurobiological and biophysical networks. Our study primarily focuses on a proof-of-concept investigation based on simulated neural dynamics, for which the ground-truth causality is known through the underlying connectivity matrix. For transformer models trained to forecast neuronal population dynamics, we show that the cross attention module effectively captures the causal relationship among neurons, with an accuracy equal or superior to that for the most popular Granger causality analysis method. While we acknowledge that real-world neurobiology data will bring further challenges, including dynamic connectivity and unobserved variability, this research offers an encouraging preliminary glimpse into the utility of the transformer model for causal representation learning in neuroscience.
Evolutionary algorithms as an alternative to backpropagation for supervised training of Biophysical Neural Networks and Neural ODEs
Nov 21, 2023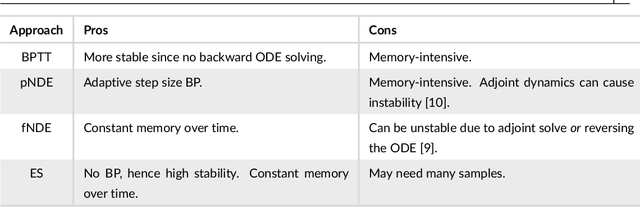
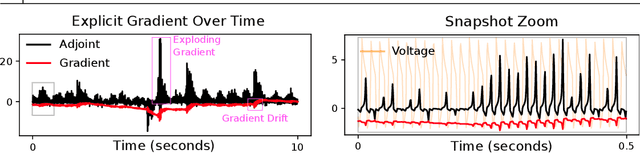
Training networks consisting of biophysically accurate neuron models could allow for new insights into how brain circuits can organize and solve tasks. We begin by analyzing the extent to which the central algorithm for neural network learning -- stochastic gradient descent through backpropagation (BP) -- can be used to train such networks. We find that properties of biophysically based neural network models needed for accurate modelling such as stiffness, high nonlinearity and long evaluation timeframes relative to spike times makes BP unstable and divergent in a variety of cases. To address these instabilities and inspired by recent work, we investigate the use of "gradient-estimating" evolutionary algorithms (EAs) for training biophysically based neural networks. We find that EAs have several advantages making them desirable over direct BP, including being forward-pass only, robust to noisy and rigid losses, allowing for discrete loss formulations, and potentially facilitating a more global exploration of parameters. We apply our method to train a recurrent network of Morris-Lecar neuron models on a stimulus integration and working memory task, and show how it can succeed in cases where direct BP is inapplicable. To expand on the viability of EAs in general, we apply them to a general neural ODE problem and a stiff neural ODE benchmark and find again that EAs can out-perform direct BP here, especially for the over-parameterized regime. Our findings suggest that biophysical neurons could provide useful benchmarks for testing the limits of BP-adjacent methods, and demonstrate the viability of EAs for training networks with complex components.
How connectivity structure shapes rich and lazy learning in neural circuits
Oct 12, 2023In theoretical neuroscience, recent work leverages deep learning tools to explore how some network attributes critically influence its learning dynamics. Notably, initial weight distributions with small (resp. large) variance may yield a rich (resp. lazy) regime, where significant (resp. minor) changes to network states and representation are observed over the course of learning. However, in biology, neural circuit connectivity generally has a low-rank structure and therefore differs markedly from the random initializations generally used for these studies. As such, here we investigate how the structure of the initial weights, in particular their effective rank, influences the network learning regime. Through both empirical and theoretical analyses, we discover that high-rank initializations typically yield smaller network changes indicative of lazier learning, a finding we also confirm with experimentally-driven initial connectivity in recurrent neural networks. Conversely, low-rank initialization biases learning towards richer learning. Importantly, however, as an exception to this rule, we find lazier learning can still occur with a low-rank initialization that aligns with task and data statistics. Our research highlights the pivotal role of initial weight structures in shaping learning regimes, with implications for metabolic costs of plasticity and risks of catastrophic forgetting.
A simple connection from loss flatness to compressed representations in neural networks
Oct 03, 2023



Deep neural networks' generalization capacity has been studied in a variety of ways, including at least two distinct categories of approach: one based on the shape of the loss landscape in parameter space, and the other based on the structure of the representation manifold in feature space (that is, in the space of unit activities). These two approaches are related, but they are rarely studied together and explicitly connected. Here, we present a simple analysis that makes such a connection. We show that, in the last phase of learning of deep neural networks, compression of the volume of the manifold of neural representations correlates with the flatness of the loss around the minima explored by ongoing parameter optimization. We show that this is predicted by a relatively simple mathematical relationship: loss flatness implies compression of neural representations. Our results build closely on prior work of \citet{ma_linear_2021}, which shows how flatness (i.e., small eigenvalues of the loss Hessian) develops in late phases of learning and lead to robustness to perturbations in network inputs. Moreover, we show there is no similarly direct connection between local dimensionality and sharpness, suggesting that this property may be controlled by different mechanisms than volume and hence may play a complementary role in neural representations. Overall, we advance a dual perspective on generalization in neural networks in both parameter and feature space.
Expressive probabilistic sampling in recurrent neural networks
Aug 22, 2023In sampling-based Bayesian models of brain function, neural activities are assumed to be samples from probability distributions that the brain uses for probabilistic computation. However, a comprehensive understanding of how mechanistic models of neural dynamics can sample from arbitrary distributions is still lacking. We use tools from functional analysis and stochastic differential equations to explore the minimum architectural requirements for $\textit{recurrent}$ neural circuits to sample from complex distributions. We first consider the traditional sampling model consisting of a network of neurons whose outputs directly represent the samples (sampler-only network). We argue that synaptic current and firing-rate dynamics in the traditional model have limited capacity to sample from a complex probability distribution. We show that the firing rate dynamics of a recurrent neural circuit with a separate set of output units can sample from an arbitrary probability distribution. We call such circuits reservoir-sampler networks (RSNs). We propose an efficient training procedure based on denoising score matching that finds recurrent and output weights such that the RSN implements Langevin sampling. We empirically demonstrate our model's ability to sample from several complex data distributions using the proposed neural dynamics and discuss its applicability to developing the next generation of sampling-based brain models.
Biologically-plausible backpropagation through arbitrary timespans via local neuromodulators
Jun 02, 2022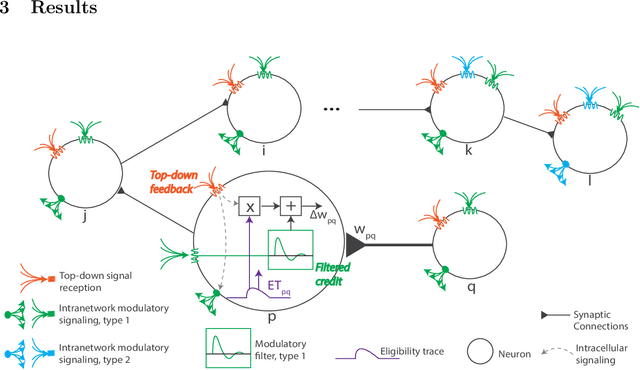
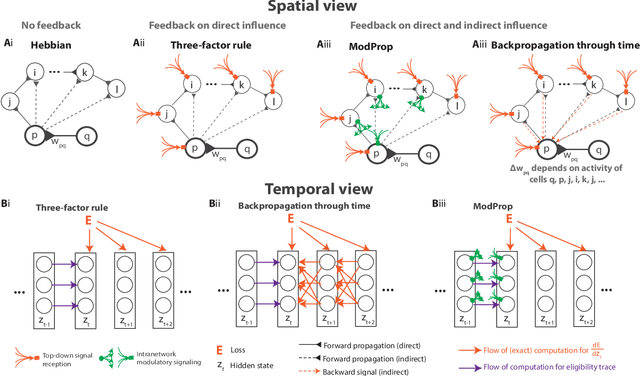
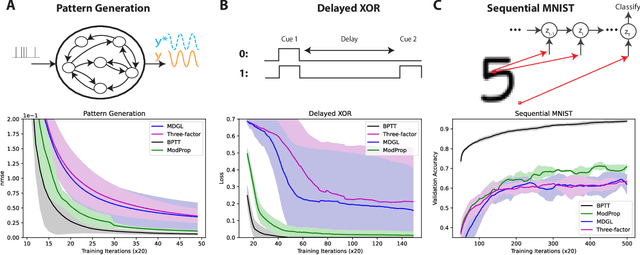
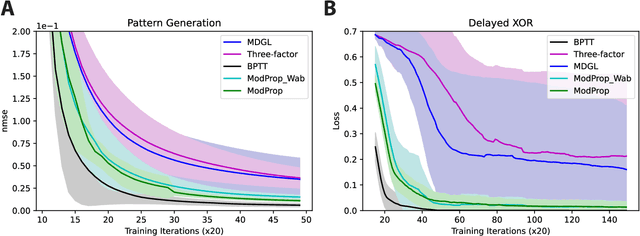
The spectacular successes of recurrent neural network models where key parameters are adjusted via backpropagation-based gradient descent have inspired much thought as to how biological neuronal networks might solve the corresponding synaptic credit assignment problem. There is so far little agreement, however, as to how biological networks could implement the necessary backpropagation through time, given widely recognized constraints of biological synaptic network signaling architectures. Here, we propose that extra-synaptic diffusion of local neuromodulators such as neuropeptides may afford an effective mode of backpropagation lying within the bounds of biological plausibility. Going beyond existing temporal truncation-based gradient approximations, our approximate gradient-based update rule, ModProp, propagates credit information through arbitrary time steps. ModProp suggests that modulatory signals can act on receiving cells by convolving their eligibility traces via causal, time-invariant and synapse-type-specific filter taps. Our mathematical analysis of ModProp learning, together with simulation results on benchmark temporal tasks, demonstrate the advantage of ModProp over existing biologically-plausible temporal credit assignment rules. These results suggest a potential neuronal mechanism for signaling credit information related to recurrent interactions over a longer time horizon. Finally, we derive an in-silico implementation of ModProp that could serve as a low-complexity and causal alternative to backpropagation through time.