 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSENDAI: A Hierarchical Sparse-measurement, EfficieNt Data AssImilation Framework
Jan 29, 2026Bridging the gap between data-rich training regimes and observation-sparse deployment conditions remains a central challenge in spatiotemporal field reconstruction, particularly when target domains exhibit distributional shifts, heterogeneous structure, and multi-scale dynamics absent from available training data. We present SENDAI, a hierarchical Sparse-measurement, EfficieNt Data AssImilation Framework that reconstructs full spatial states from hyper sparse sensor observations by combining simulation-derived priors with learned discrepancy corrections. We demonstrate the performance on satellite remote sensing, reconstructing MODIS (Moderate Resolution Imaging Spectroradiometer) derived vegetation index fields across six globally distributed sites. Using seasonal periods as a proxy for domain shift, the framework consistently outperforms established baselines that require substantially denser observations -- SENDAI achieves a maximum SSIM improvement of 185% over traditional baselines and a 36% improvement over recent high-frequency-based methods. These gains are particularly pronounced for landscapes with sharp boundaries and sub-seasonal dynamics; more importantly, the framework effectively preserves diagnostically relevant structures -- such as field topologies, land cover discontinuities, and spatial gradients. By yielding corrections that are more structurally and spectrally separable, the reconstructed fields are better suited for downstream inference of indirectly observed variables. The results therefore highlight a lightweight and operationally viable framework for sparse-measurement reconstruction that is applicable to physically grounded inference, resource-limited deployment, and real-time monitor and control.
Cheap2Rich: A Multi-Fidelity Framework for Data Assimilation and System Identification of Multiscale Physics -- Rotating Detonation Engines
Jan 28, 2026Bridging the sim2real gap between computationally inexpensive models and complex physical systems remains a central challenge in machine learning applications to engineering problems, particularly in multi-scale settings where reduced-order models typically capture only dominant dynamics. In this work, we present Cheap2Rich, a multi-scale data assimilation framework that reconstructs high-fidelity state spaces from sparse sensor histories by combining a fast low-fidelity prior with learned, interpretable discrepancy corrections. We demonstrate the performance on rotating detonation engines (RDEs), a challenging class of systems that couple detonation-front propagation with injector-driven unsteadiness, mixing, and stiff chemistry across disparate scales. Our approach successfully reconstructs high-fidelity RDE states from sparse measurements while isolating physically meaningful discrepancy dynamics associated with injector-driven effects. The results highlight a general multi-fidelity framework for data assimilation and system identification in complex multi-scale systems, enabling rapid design exploration and real-time monitoring and control while providing interpretable discrepancy dynamics. Code for this project is is available at: github.com/kro0l1k/Cheap2Rich.
Terrain-Adaptive Mobile 3D Printing with Hierarchical Control
Jan 15, 2026Mobile 3D printing on unstructured terrain remains challenging due to the conflict between platform mobility and deposition precision. Existing gantry-based systems achieve high accuracy but lack mobility, while mobile platforms struggle to maintain print quality on uneven ground. We present a framework that tightly integrates AI-driven disturbance prediction with multi-modal sensor fusion and hierarchical hardware control, forming a closed-loop perception-learning-actuation system. The AI module learns terrain-to-perturbation mappings from IMU, vision, and depth sensors, enabling proactive compensation rather than reactive correction. This intelligence is embedded into a three-layer control architecture: path planning, predictive chassis-manipulator coordination, and precision hardware execution. Through outdoor experiments on terrain with slopes and surface irregularities, we demonstrate sub-centimeter printing accuracy while maintaining full platform mobility. This AI-hardware integration establishes a practical foundation for autonomous construction in unstructured environments.
The Seismic Wavefield Common Task Framework
Dec 22, 2025Seismology faces fundamental challenges in state forecasting and reconstruction (e.g., earthquake early warning and ground motion prediction) and managing the parametric variability of source locations, mechanisms, and Earth models (e.g., subsurface structure and topography effects). Addressing these with simulations is hindered by their massive scale, both in synthetic data volumes and numerical complexity, while real-data efforts are constrained by models that inadequately reflect the Earth's complexity and by sparse sensor measurements from the field. Recent machine learning (ML) efforts offer promise, but progress is obscured by a lack of proper characterization, fair reporting, and rigorous comparisons. To address this, we introduce a Common Task Framework (CTF) for ML for seismic wavefields, starting with three distinct wavefield datasets. Our CTF features a curated set of datasets at various scales (global, crustal, and local) and task-specific metrics spanning forecasting, reconstruction, and generalization under realistic constraints such as noise and limited data. Inspired by CTFs in fields like natural language processing, this framework provides a structured and rigorous foundation for head-to-head algorithm evaluation. We illustrate the evaluation procedure with scores reported for two of the datasets, showcasing the performance of various methods and foundation models for reconstructing seismic wavefields from both simulated and real-world sensor measurements. The CTF scores reveal the strengths, limitations, and suitability for specific problem classes. Our vision is to replace ad hoc comparisons with standardized evaluations on hidden test sets, raising the bar for rigor and reproducibility in scientific ML.
Information theory and discriminative sampling for model discovery
Dec 17, 2025



Fisher information and Shannon entropy are fundamental tools for understanding and analyzing dynamical systems from complementary perspectives. They can characterize unknown parameters by quantifying the information contained in variables, or measure how different initial trajectories or temporal segments of a trajectory contribute to learning or inferring system dynamics. In this work, we leverage the Fisher Information Matrix (FIM) within the data-driven framework of {\em sparse identification of nonlinear dynamics} (SINDy). We visualize information patterns in chaotic and non-chaotic systems for both single trajectories and multiple initial conditions, demonstrating how information-based analysis can improve sampling efficiency and enhance model performance by prioritizing more informative data. The benefits of statistical bagging are further elucidated through spectral analysis of the FIM. We also illustrate how Fisher information and entropy metrics can promote data efficiency in three scenarios: when only a single trajectory is available, when a tunable control parameter exists, and when multiple trajectories can be freely initialized. As data-driven model discovery continues to gain prominence, principled sampling strategies guided by quantifiable information metrics offer a powerful approach for improving learning efficiency and reducing data requirements.
Accelerating scientific discovery with the common task framework
Nov 06, 2025Machine learning (ML) and artificial intelligence (AI) algorithms are transforming and empowering the characterization and control of dynamic systems in the engineering, physical, and biological sciences. These emerging modeling paradigms require comparative metrics to evaluate a diverse set of scientific objectives, including forecasting, state reconstruction, generalization, and control, while also considering limited data scenarios and noisy measurements. We introduce a common task framework (CTF) for science and engineering, which features a growing collection of challenge data sets with a diverse set of practical and common objectives. The CTF is a critically enabling technology that has contributed to the rapid advance of ML/AI algorithms in traditional applications such as speech recognition, language processing, and computer vision. There is a critical need for the objective metrics of a CTF to compare the diverse algorithms being rapidly developed and deployed in practice today across science and engineering.
PySensors 2.0: A Python Package for Sparse Sensor Placement
Sep 09, 2025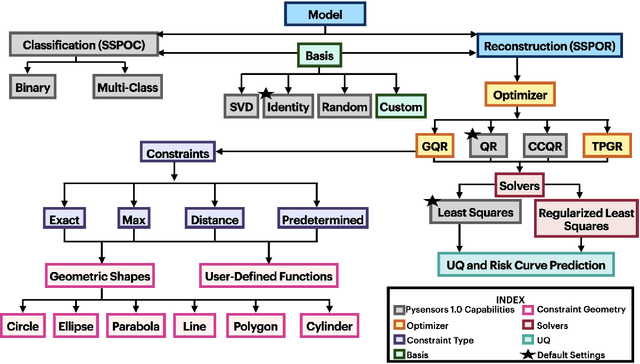
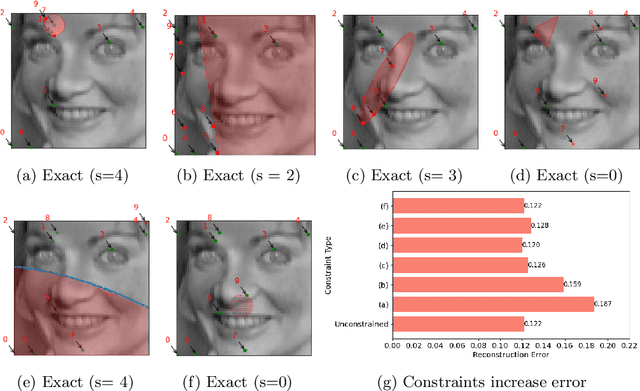
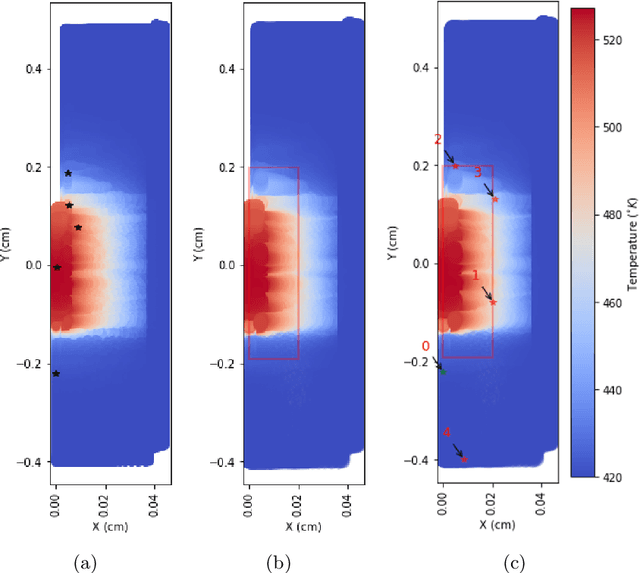
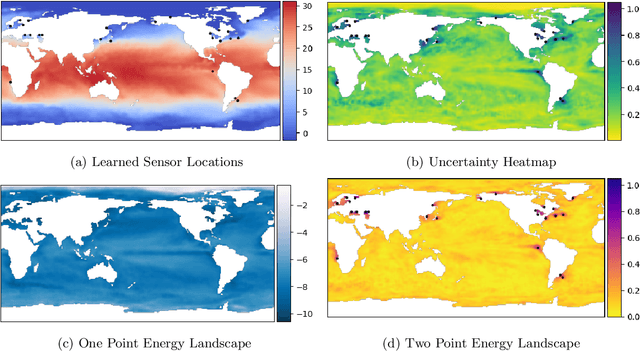
PySensors is a Python package for selecting and placing a sparse set of sensors for reconstruction and classification tasks. In this major update to \texttt{PySensors}, we introduce spatially constrained sensor placement capabilities, allowing users to enforce constraints such as maximum or exact sensor counts in specific regions, incorporate predetermined sensor locations, and maintain minimum distances between sensors. We extend functionality to support custom basis inputs, enabling integration of any data-driven or spectral basis. We also propose a thermodynamic approach that goes beyond a single ``optimal'' sensor configuration and maps the complete landscape of sensor interactions induced by the training data. This comprehensive view facilitates integration with external selection criteria and enables assessment of sensor replacement impacts. The new optimization technique also accounts for over- and under-sampling of sensors, utilizing a regularized least squares approach for robust reconstruction. Additionally, we incorporate noise-induced uncertainty quantification of the estimation error and provide visual uncertainty heat maps to guide deployment decisions. To highlight these additions, we provide a brief description of the mathematical algorithms and theory underlying these new capabilities. We demonstrate the usage of new features with illustrative code examples and include practical advice for implementation across various application domains. Finally, we outline a roadmap of potential extensions to further enhance the package's functionality and applicability to emerging sensing challenges.
CS-SHRED: Enhancing SHRED for Robust Recovery of Spatiotemporal Dynamics
Jul 30, 2025We present $\textbf{CS-SHRED}$, a novel deep learning architecture that integrates Compressed Sensing (CS) into a Shallow Recurrent Decoder ($\textbf{SHRED}$) to reconstruct spatiotemporal dynamics from incomplete, compressed, or corrupted data. Our approach introduces two key innovations. First, by incorporating CS techniques into the $\textbf{SHRED}$ architecture, our method leverages a batch-based forward framework with $\ell_1$ regularization to robustly recover signals even in scenarios with sparse sensor placements, noisy measurements, and incomplete sensor acquisitions. Second, an adaptive loss function dynamically combines Mean Squared Error (MSE) and Mean Absolute Error (MAE) terms with a piecewise Signal-to-Noise Ratio (SNR) regularization, which suppresses noise and outliers in low-SNR regions while preserving fine-scale features in high-SNR regions. We validate $\textbf{CS-SHRED}$ on challenging problems including viscoelastic fluid flows, maximum specific humidity fields, sea surface temperature distributions, and rotating turbulent flows. Compared to the traditional $\textbf{SHRED}$ approach, $\textbf{CS-SHRED}$ achieves significantly higher reconstruction fidelity - as demonstrated by improved SSIM and PSNR values, lower normalized errors, and enhanced LPIPS scores-thereby providing superior preservation of small-scale structures and increased robustness against noise and outliers. Our results underscore the advantages of the jointly trained CS and SHRED design architecture which includes an LSTM sequence model for characterizing the temporal evolution with a shallow decoder network (SDN) for modeling the high-dimensional state space. The SNR-guided adaptive loss function for the spatiotemporal data recovery establishes $\textbf{CS-SHRED}$ as a promising tool for a wide range of applications in environmental, climatic, and scientific data analyses.
PySHRED: A Python package for SHallow REcurrent Decoding for sparse sensing, model reduction and scientific discovery
Jul 28, 2025SHallow REcurrent Decoders (SHRED) provide a deep learning strategy for modeling high-dimensional dynamical systems and/or spatiotemporal data from dynamical system snapshot observations. PySHRED is a Python package that implements SHRED and several of its major extensions, including for robust sensing, reduced order modeling and physics discovery. In this paper, we introduce the version 1.0 release of PySHRED, which includes data preprocessors and a number of cutting-edge SHRED methods specifically designed to handle real-world data that may be noisy, multi-scale, parameterized, prohibitively high-dimensional, and strongly nonlinear. The package is easy to install, thoroughly-documented, supplemented with extensive code examples, and modularly-structured to support future additions. The entire codebase is released under the MIT license and is available at https://github.com/pyshred-dev/pyshred.
Mesh-free sparse identification of nonlinear dynamics
May 21, 2025Identifying the governing equations of a dynamical system is one of the most important tasks for scientific modeling. However, this procedure often requires high-quality spatio-temporal data uniformly sampled on structured grids. In this paper, we propose mesh-free SINDy, a novel algorithm which leverages the power of neural network approximation as well as auto-differentiation to identify governing equations from arbitrary sensor placements and non-uniform temporal data sampling. We show that mesh-free SINDy is robust to high noise levels and limited data while remaining computationally efficient. In our implementation, the training procedure is straight-forward and nearly free of hyperparameter tuning, making mesh-free SINDy widely applicable to many scientific and engineering problems. In the experiments, we demonstrate its effectiveness on a series of PDEs including the Burgers' equation, the heat equation, the Korteweg-De Vries equation and the 2D advection-diffusion equation. We conduct detailed numerical experiments on all datasets, varying the noise levels and number of samples, and we also compare our approach to previous state-of-the-art methods. It is noteworthy that, even in high-noise and low-data scenarios, mesh-free SINDy demonstrates robust PDE discovery, achieving successful identification with up to 75% noise for the Burgers' equation using 5,000 samples and with as few as 100 samples and 1% noise. All of this is achieved within a training time of under one minute.