 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Prompt Engineering Strategies for Sentiment Control in AI-Generated Texts
Feb 06, 2026The groundbreaking capabilities of Large Language Models (LLMs) offer new opportunities for enhancing human-computer interaction through emotion-adaptive Artificial Intelligence (AI). However, deliberately controlling the sentiment in these systems remains challenging. The present study investigates the potential of prompt engineering for controlling sentiment in LLM-generated text, providing a resource-sensitive and accessible alternative to existing methods. Using Ekman's six basic emotions (e.g., joy, disgust), we examine various prompting techniques, including Zero-Shot and Chain-of-Thought prompting using gpt-3.5-turbo, and compare it to fine-tuning. Our results indicate that prompt engineering effectively steers emotions in AI-generated texts, offering a practical and cost-effective alternative to fine-tuning, especially in data-constrained settings. In this regard, Few-Shot prompting with human-written examples was the most effective among other techniques, likely due to the additional task-specific guidance. The findings contribute valuable insights towards developing emotion-adaptive AI systems.
The Effectiveness of Style Vectors for Steering Large Language Models: A Human Evaluation
Jan 29, 2026Controlling the behavior of large language models (LLMs) at inference time is essential for aligning outputs with human abilities and safety requirements. \emph{Activation steering} provides a lightweight alternative to prompt engineering and fine-tuning by directly modifying internal activations to guide generation. This research advances the literature in three significant directions. First, while previous work demonstrated the technical feasibility of steering emotional tone using automated classifiers, this paper presents the first human evaluation of activation steering concerning the emotional tone of LLM outputs, collecting over 7,000 crowd-sourced ratings from 190 participants via Prolific ($n=190$). These ratings assess both perceived emotional intensity and overall text quality. Second, we find strong alignment between human and model-based quality ratings (mean $r=0.776$, range $0.157$--$0.985$), indicating automatic scoring can proxy perceived quality. Moderate steering strengths ($λ\approx 0.15$) reliably amplify target emotions while preserving comprehensibility, with the strongest effects for disgust ($η_p^2 = 0.616$) and fear ($η_p^2 = 0.540$), and minimal effects for surprise ($η_p^2 = 0.042$). Finally, upgrading from Alpaca to LlaMA-3 yielded more consistent steering with significant effects across emotions and strengths (all $p < 0.001$). Inter-rater reliability was high (ICC $= 0.71$--$0.87$), underscoring the robustness of the findings. These findings support activation-based control as a scalable method for steering LLM behavior across affective dimensions.
AI Assistants for Spaceflight Procedures: Combining Generative Pre-Trained Transformer and Retrieval-Augmented Generation on Knowledge Graphs With Augmented Reality Cues
Sep 21, 2024
This paper describes the capabilities and potential of the intelligent personal assistant (IPA) CORE (Checklist Organizer for Research and Exploration), designed to support astronauts during procedures onboard the International Space Station (ISS), the Lunar Gateway station, and beyond. We reflect on the importance of a reliable and flexible assistant capable of offline operation and highlight the usefulness of audiovisual interaction using augmented reality elements to intuitively display checklist information. We argue that current approaches to the design of IPAs in space operations fall short of meeting these criteria. Therefore, we propose CORE as an assistant that combines Knowledge Graphs (KGs), Retrieval-Augmented Generation (RAG) for a Generative Pre-Trained Transformer (GPT), and Augmented Reality (AR) elements to ensure an intuitive understanding of procedure steps, reliability, offline availability, and flexibility in terms of response style and procedure updates.
Style Vectors for Steering Generative Large Language Model
Feb 02, 2024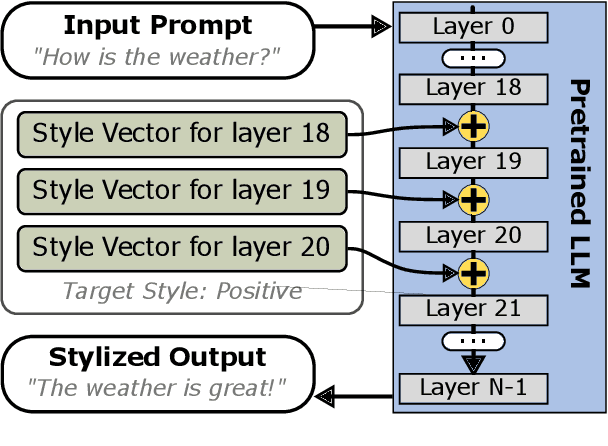
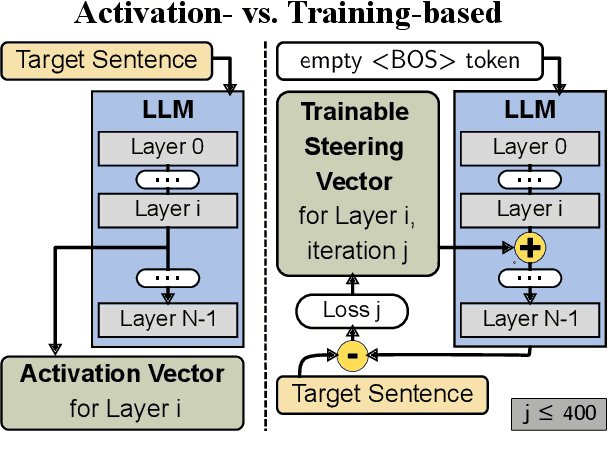
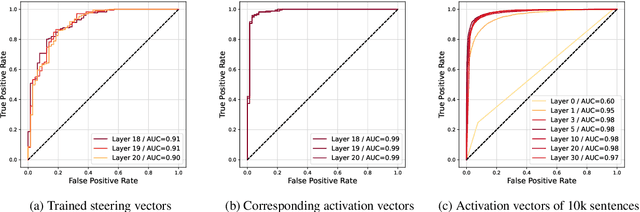
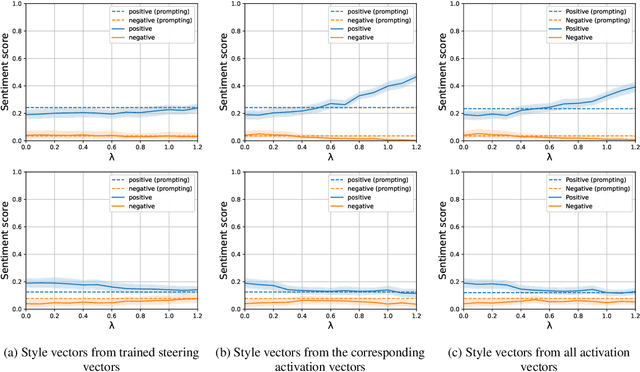
This research explores strategies for steering the output of large language models (LLMs) towards specific styles, such as sentiment, emotion, or writing style, by adding style vectors to the activations of hidden layers during text generation. We show that style vectors can be simply computed from recorded layer activations for input texts in a specific style in contrast to more complex training-based approaches. Through a series of experiments, we demonstrate the effectiveness of activation engineering using such style vectors to influence the style of generated text in a nuanced and parameterisable way, distinguishing it from prompt engineering. The presented research constitutes a significant step towards developing more adaptive and effective AI-empowered interactive systems.
Gender Bias in BERT -- Measuring and Analysing Biases through Sentiment Rating in a Realistic Downstream Classification Task
Jun 27, 2023Pretrained language models are publicly available and constantly finetuned for various real-life applications. As they become capable of grasping complex contextual information, harmful biases are likely increasingly intertwined with those models. This paper analyses gender bias in BERT models with two main contributions: First, a novel bias measure is introduced, defining biases as the difference in sentiment valuation of female and male sample versions. Second, we comprehensively analyse BERT's biases on the example of a realistic IMDB movie classifier. By systematically varying elements of the training pipeline, we can conclude regarding their impact on the final model bias. Seven different public BERT models in nine training conditions, i.e. 63 models in total, are compared. Almost all conditions yield significant gender biases. Results indicate that reflected biases stem from public BERT models rather than task-specific data, emphasising the weight of responsible usage.
Requirements for Explainability and Acceptance of Artificial Intelligence in Collaborative Work
Jun 27, 2023

The increasing prevalence of Artificial Intelligence (AI) in safety-critical contexts such as air-traffic control leads to systems that are practical and efficient, and to some extent explainable to humans to be trusted and accepted. The present structured literature analysis examines n = 236 articles on the requirements for the explainability and acceptance of AI. Results include a comprehensive review of n = 48 articles on information people need to perceive an AI as explainable, the information needed to accept an AI, and representation and interaction methods promoting trust in an AI. Results indicate that the two main groups of users are developers who require information about the internal operations of the model and end users who require information about AI results or behavior. Users' information needs vary in specificity, complexity, and urgency and must consider context, domain knowledge, and the user's cognitive resources. The acceptance of AI systems depends on information about the system's functions and performance, privacy and ethical considerations, as well as goal-supporting information tailored to individual preferences and information to establish trust in the system. Information about the system's limitations and potential failures can increase acceptance and trust. Trusted interaction methods are human-like, including natural language, speech, text, and visual representations such as graphs, charts, and animations. Our results have significant implications for future human-centric AI systems being developed. Thus, they are suitable as input for further application-specific investigations of user needs.
ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models
Jun 07, 2023
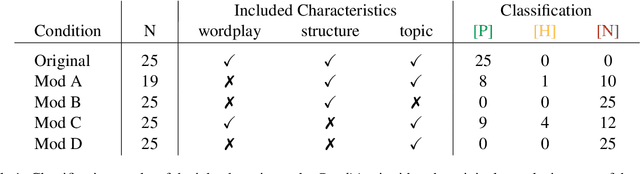

Humor is a central aspect of human communication that has not been solved for artificial agents so far. Large language models (LLMs) are increasingly able to capture implicit and contextual information. Especially, OpenAI's ChatGPT recently gained immense public attention. The GPT3-based model almost seems to communicate on a human level and can even tell jokes. Humor is an essential component of human communication. But is ChatGPT really funny? We put ChatGPT's sense of humor to the test. In a series of exploratory experiments around jokes, i.e., generation, explanation, and detection, we seek to understand ChatGPT's capability to grasp and reproduce human humor. Since the model itself is not accessible, we applied prompt-based experiments. Our empirical evidence indicates that jokes are not hard-coded but mostly also not newly generated by the model. Over 90% of 1008 generated jokes were the same 25 Jokes. The system accurately explains valid jokes but also comes up with fictional explanations for invalid jokes. Joke-typical characteristics can mislead ChatGPT in the classification of jokes. ChatGPT has not solved computational humor yet but it can be a big leap toward "funny" machines.
BERT has a Moral Compass: Improvements of ethical and moral values of machines
Dec 11, 2019

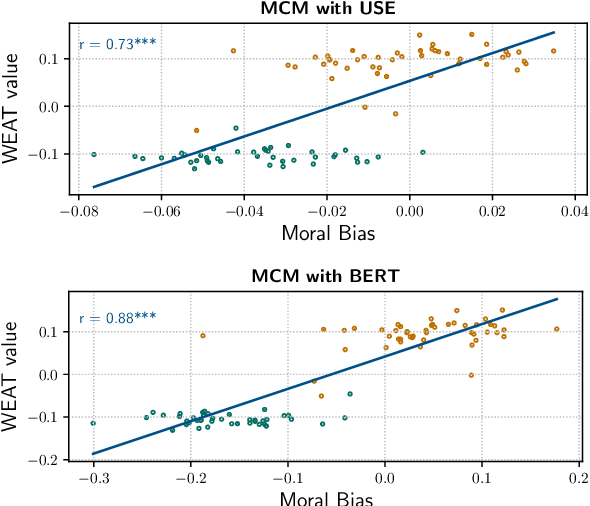
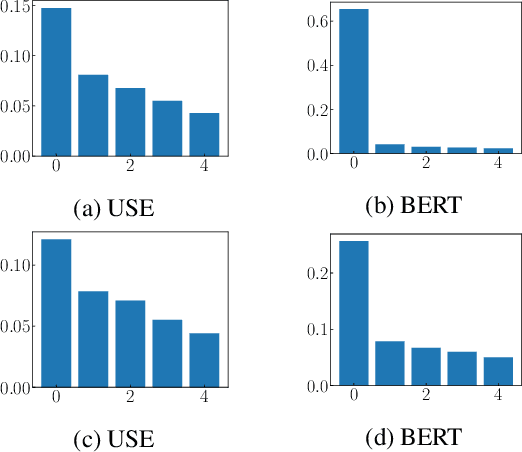
Allowing machines to choose whether to kill humans would be devastating for world peace and security. But how do we equip machines with the ability to learn ethical or even moral choices? Jentzsch et al.(2019) showed that applying machine learning to human texts can extract deontological ethical reasoning about "right" and "wrong" conduct by calculating a moral bias score on a sentence level using sentence embeddings. The machine learned that it is objectionable to kill living beings, but it is fine to kill time; It is essential to eat, yet one might not eat dirt; it is important to spread information, yet one should not spread misinformation. However, the evaluated moral bias was restricted to simple actions -- one verb -- and a ranking of actions with surrounding context. Recently BERT ---and variants such as RoBERTa and SBERT--- has set a new state-of-the-art performance for a wide range of NLP tasks. But has BERT also a better moral compass? In this paper, we discuss and show that this is indeed the case. Thus, recent improvements of language representations also improve the representation of the underlying ethical and moral values of the machine. We argue that through an advanced semantic representation of text, BERT allows one to get better insights of moral and ethical values implicitly represented in text. This enables the Moral Choice Machine (MCM) to extract more accurate imprints of moral choices and ethical values.