 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Style Vectors for Steering Large Language Models: A Human Evaluation
Jan 29, 2026Controlling the behavior of large language models (LLMs) at inference time is essential for aligning outputs with human abilities and safety requirements. \emph{Activation steering} provides a lightweight alternative to prompt engineering and fine-tuning by directly modifying internal activations to guide generation. This research advances the literature in three significant directions. First, while previous work demonstrated the technical feasibility of steering emotional tone using automated classifiers, this paper presents the first human evaluation of activation steering concerning the emotional tone of LLM outputs, collecting over 7,000 crowd-sourced ratings from 190 participants via Prolific ($n=190$). These ratings assess both perceived emotional intensity and overall text quality. Second, we find strong alignment between human and model-based quality ratings (mean $r=0.776$, range $0.157$--$0.985$), indicating automatic scoring can proxy perceived quality. Moderate steering strengths ($λ\approx 0.15$) reliably amplify target emotions while preserving comprehensibility, with the strongest effects for disgust ($η_p^2 = 0.616$) and fear ($η_p^2 = 0.540$), and minimal effects for surprise ($η_p^2 = 0.042$). Finally, upgrading from Alpaca to LlaMA-3 yielded more consistent steering with significant effects across emotions and strengths (all $p < 0.001$). Inter-rater reliability was high (ICC $= 0.71$--$0.87$), underscoring the robustness of the findings. These findings support activation-based control as a scalable method for steering LLM behavior across affective dimensions.
Style Vectors for Steering Generative Large Language Model
Feb 02, 2024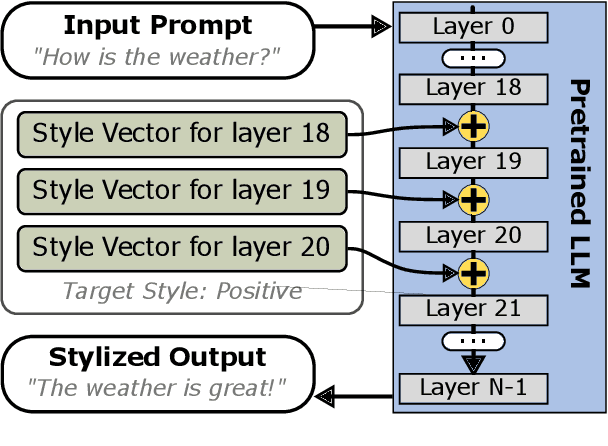
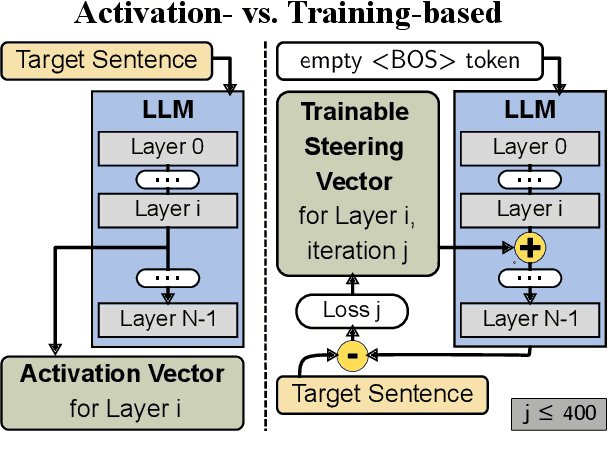
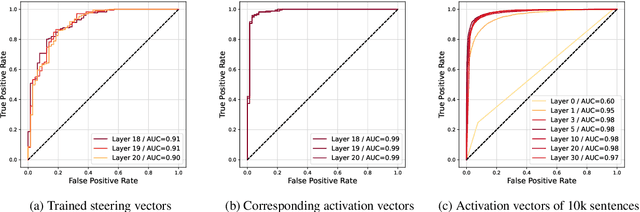
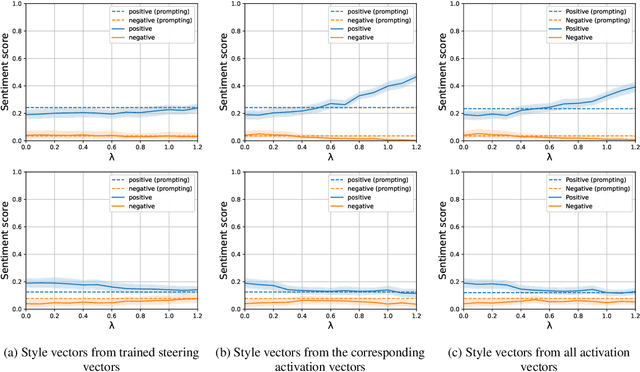
This research explores strategies for steering the output of large language models (LLMs) towards specific styles, such as sentiment, emotion, or writing style, by adding style vectors to the activations of hidden layers during text generation. We show that style vectors can be simply computed from recorded layer activations for input texts in a specific style in contrast to more complex training-based approaches. Through a series of experiments, we demonstrate the effectiveness of activation engineering using such style vectors to influence the style of generated text in a nuanced and parameterisable way, distinguishing it from prompt engineering. The presented research constitutes a significant step towards developing more adaptive and effective AI-empowered interactive systems.
Abstract Flow for Temporal Semantic Segmentation on the Permutohedral Lattice
Mar 29, 2022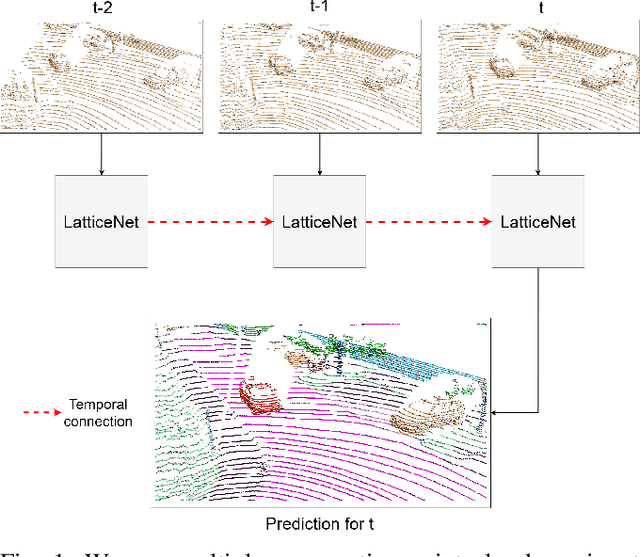
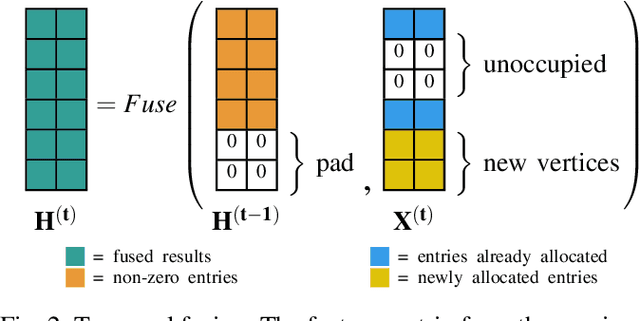
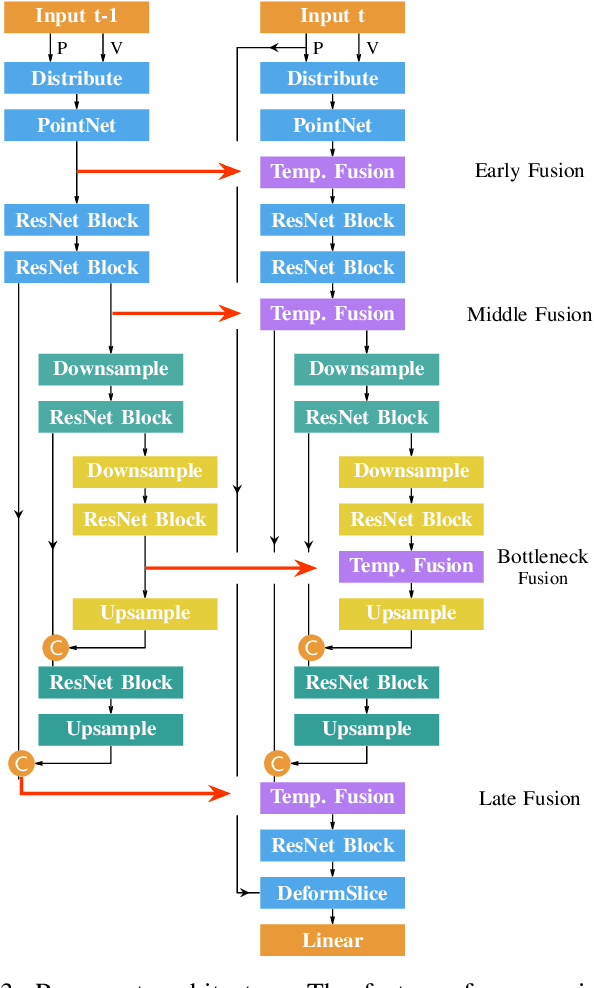
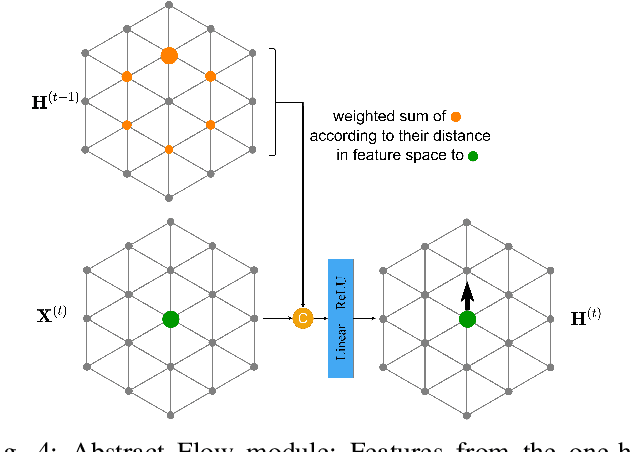
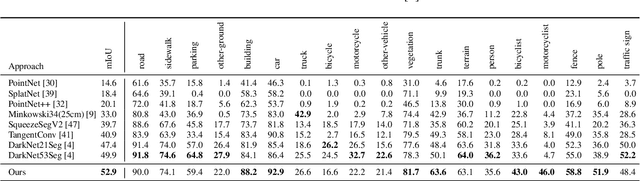
Semantic segmentation is a core ability required by autonomous agents, as being able to distinguish which parts of the scene belong to which object class is crucial for navigation and interaction with the environment. Approaches which use only one time-step of data cannot distinguish between moving objects nor can they benefit from temporal integration. In this work, we extend a backbone LatticeNet to process temporal point cloud data. Additionally, we take inspiration from optical flow methods and propose a new module called Abstract Flow which allows the network to match parts of the scene with similar abstract features and gather the information temporally. We obtain state-of-the-art results on the SemanticKITTI dataset that contains LiDAR scans from real urban environments. We share the PyTorch implementation of TemporalLatticeNet at https://github.com/AIS-Bonn/temporal_latticenet .
LatticeNet: Fast Spatio-Temporal Point Cloud Segmentation Using Permutohedral Lattices
Aug 09, 2021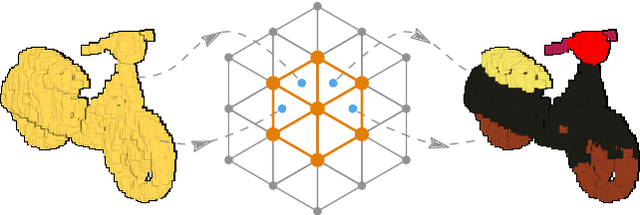
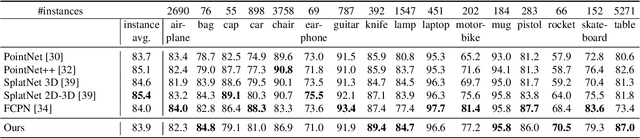
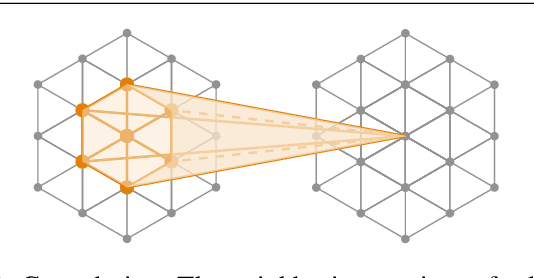
Deep convolutional neural networks (CNNs) have shown outstanding performance in the task of semantically segmenting images. Applying the same methods on 3D data still poses challenges due to the heavy memory requirements and the lack of structured data. Here, we propose LatticeNet, a novel approach for 3D semantic segmentation, which takes raw point clouds as input. A PointNet describes the local geometry which we embed into a sparse permutohedral lattice. The lattice allows for fast convolutions while keeping a low memory footprint. Further, we introduce DeformSlice, a novel learned data-dependent interpolation for projecting lattice features back onto the point cloud. We present results of 3D segmentation on multiple datasets where our method achieves state-of-the-art performance. We also extend and evaluate our network for instance and dynamic object segmentation.
LatticeNet: Fast Point Cloud Segmentation Using Permutohedral Lattices
Dec 12, 2019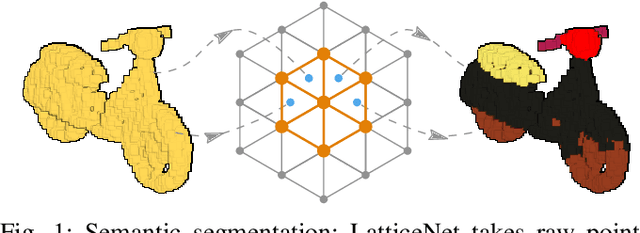


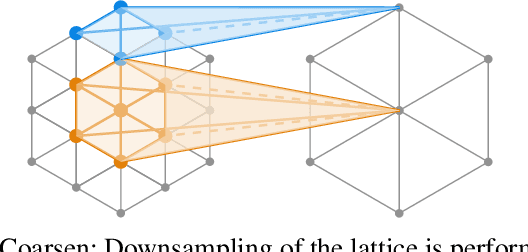
Deep convolutional neural networks (CNNs) have shown outstanding performance in the task of semantically segmenting images. However, applying the same methods on 3D data still poses challenges due to the heavy memory requirements and the lack of structured data. Here, we propose LatticeNet, a novel approach for 3D semantic segmentation, which takes as input raw point clouds. A PointNet describes the local geometry which we embed into a sparse permutohedral lattice. The lattice allows for fast convolutions while keeping a low memory footprint. Further, we introduce DeformSlice, a novel learned data-dependent interpolation for projecting lattice features back onto the point cloud. We present results of 3D segmentation on various datasets where our method achieves state-of-the-art performance.