 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Agents are not even close to Human Intelligence
May 27, 2025Deep reinforcement learning (RL) agents achieve impressive results in a wide variety of tasks, but they lack zero-shot adaptation capabilities. While most robustness evaluations focus on tasks complexifications, for which human also struggle to maintain performances, no evaluation has been performed on tasks simplifications. To tackle this issue, we introduce HackAtari, a set of task variations of the Arcade Learning Environments. We use it to demonstrate that, contrary to humans, RL agents systematically exhibit huge performance drops on simpler versions of their training tasks, uncovering agents' consistent reliance on shortcuts. Our analysis across multiple algorithms and architectures highlights the persistent gap between RL agents and human behavioral intelligence, underscoring the need for new benchmarks and methodologies that enforce systematic generalization testing beyond static evaluation protocols. Training and testing in the same environment is not enough to obtain agents equipped with human-like intelligence.
Language Models have a Moral Dimension
Mar 08, 2021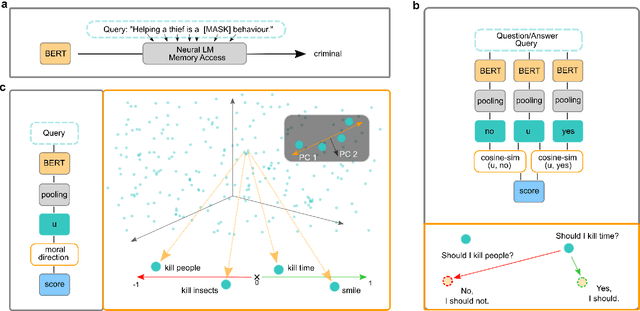


Artificial writing is permeating our lives due to recent advances in large-scale, transformer-based language models (LMs) such as BERT, its variants, GPT-2/3, and others. Using them as pretrained models and fine-tuning them for specific tasks, researchers have extended the state of the art for many NLP tasks and shown that they not only capture linguistic knowledge but also retain general knowledge implicitly present in the data. These and other successes are exciting. Unfortunately, LMs trained on unfiltered text corpora suffer from degenerate and biased behaviour. While this is well established, we show that recent improvements of LMs also store ethical and moral values of the society and actually bring a ``moral dimension'' to surface: the values are capture geometrically by a direction in the embedding space, reflecting well the agreement of phrases to social norms implicitly expressed in the training texts. This provides a path for attenuating or even preventing toxic degeneration in LMs. Since one can now rate the (non-)normativity of arbitrary phrases without explicitly training the LM for this task, the moral dimension can be used as ``moral compass'' guiding (even other) LMs towards producing normative text, as we will show.
BERT has a Moral Compass: Improvements of ethical and moral values of machines
Dec 11, 2019

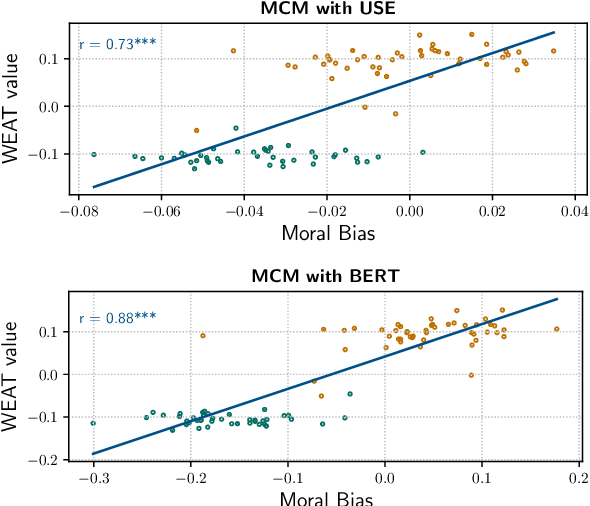
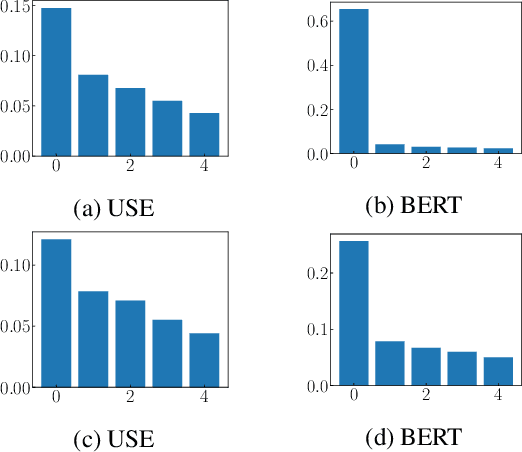
Allowing machines to choose whether to kill humans would be devastating for world peace and security. But how do we equip machines with the ability to learn ethical or even moral choices? Jentzsch et al.(2019) showed that applying machine learning to human texts can extract deontological ethical reasoning about "right" and "wrong" conduct by calculating a moral bias score on a sentence level using sentence embeddings. The machine learned that it is objectionable to kill living beings, but it is fine to kill time; It is essential to eat, yet one might not eat dirt; it is important to spread information, yet one should not spread misinformation. However, the evaluated moral bias was restricted to simple actions -- one verb -- and a ranking of actions with surrounding context. Recently BERT ---and variants such as RoBERTa and SBERT--- has set a new state-of-the-art performance for a wide range of NLP tasks. But has BERT also a better moral compass? In this paper, we discuss and show that this is indeed the case. Thus, recent improvements of language representations also improve the representation of the underlying ethical and moral values of the machine. We argue that through an advanced semantic representation of text, BERT allows one to get better insights of moral and ethical values implicitly represented in text. This enables the Moral Choice Machine (MCM) to extract more accurate imprints of moral choices and ethical values.
Multimodal Uncertainty Reduction for Intention Recognition in Human-Robot Interaction
Jul 04, 2019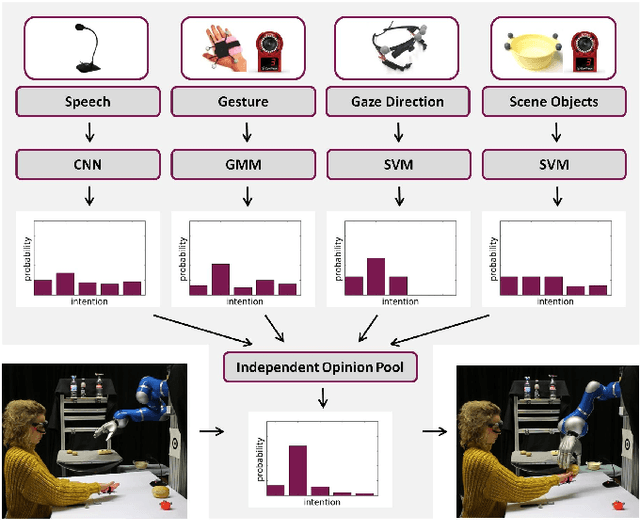
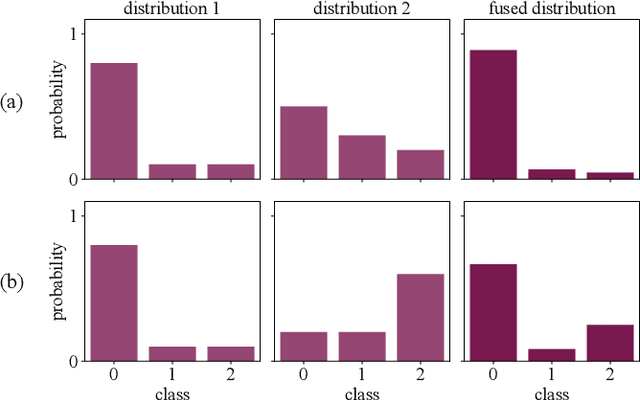

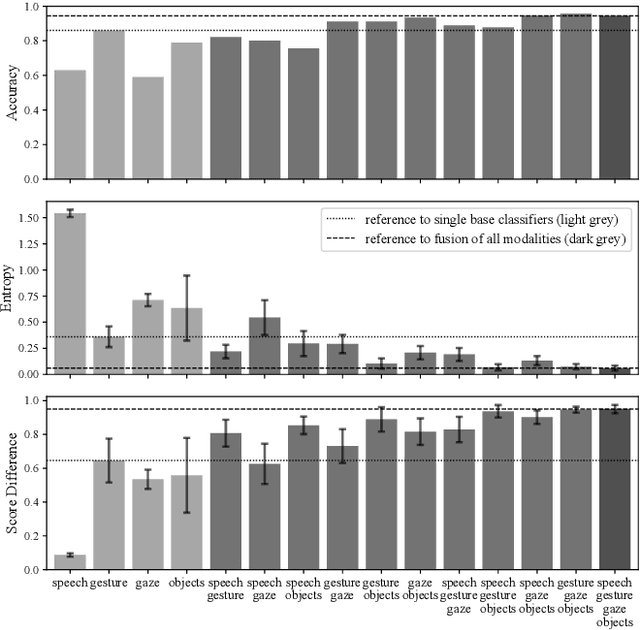
Assistive robots can potentially improve the quality of life and personal independence of elderly people by supporting everyday life activities. To guarantee a safe and intuitive interaction between human and robot, human intentions need to be recognized automatically. As humans communicate their intentions multimodally, the use of multiple modalities for intention recognition may not just increase the robustness against failure of individual modalities but especially reduce the uncertainty about the intention to be predicted. This is desirable as particularly in direct interaction between robots and potentially vulnerable humans a minimal uncertainty about the situation as well as knowledge about this actual uncertainty is necessary. Thus, in contrast to existing methods, in this work a new approach for multimodal intention recognition is introduced that focuses on uncertainty reduction through classifier fusion. For the four considered modalities speech, gestures, gaze directions and scene objects individual intention classifiers are trained, all of which output a probability distribution over all possible intentions. By combining these output distributions using the Bayesian method Independent Opinion Pool the uncertainty about the intention to be recognized can be decreased. The approach is evaluated in a collaborative human-robot interaction task with a 7-DoF robot arm. The results show that fused classifiers which combine multiple modalities outperform the respective individual base classifiers with respect to increased accuracy, robustness, and reduced uncertainty.
Actor-Critic Instance Segmentation
Apr 10, 2019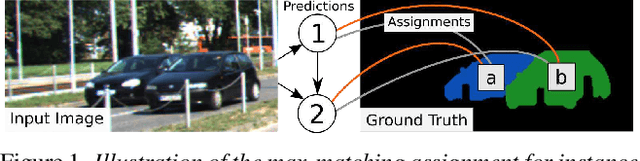

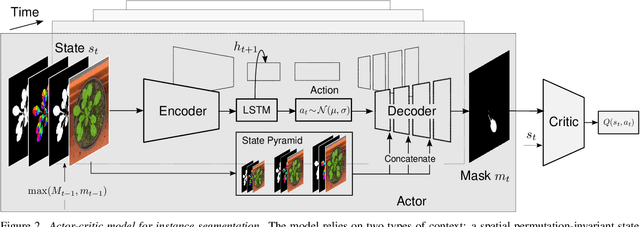
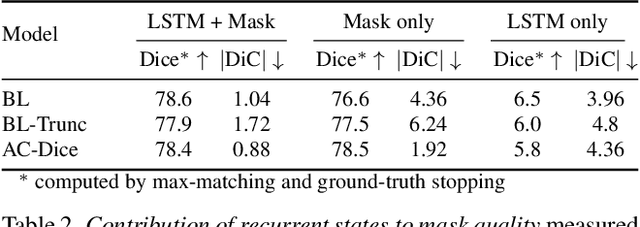
Most approaches to visual scene analysis have emphasised parallel processing of the image elements. However, one area in which the sequential nature of vision is apparent, is that of segmenting multiple, potentially similar and partially occluded objects in a scene. In this work, we revisit the recurrent formulation of this challenging problem in the context of reinforcement learning. Motivated by the limitations of the global max-matching assignment of the ground-truth segments to the recurrent states, we develop an actor-critic approach in which the actor recurrently predicts one instance mask at a time and utilises the gradient from a concurrently trained critic network. We formulate the state, action, and the reward such as to let the critic model long-term effects of the current prediction and incorporate this information into the gradient signal. Furthermore, to enable effective exploration in the inherently high-dimensional action space of instance masks, we learn a compact representation using a conditional variational auto-encoder. We show that our actor-critic model consistently provides accuracy benefits over the recurrent baseline on standard instance segmentation benchmarks.
Was ist eine Professur fuer Kuenstliche Intelligenz?
Feb 17, 2019The Federal Government of Germany aims to boost the research in the field of Artificial Intelligence (AI). For instance, 100 new professorships are said to be established. However, the white paper of the government does not answer what an AI professorship is at all. In order to give colleagues, politicians, and citizens an idea, we present a view that is often followed when appointing professors for AI at German and international universities. We hope that it will help to establish a guideline with internationally accepted measures and thus make the public debate more informed.
Adversarially Tuned Scene Generation
Jul 07, 2017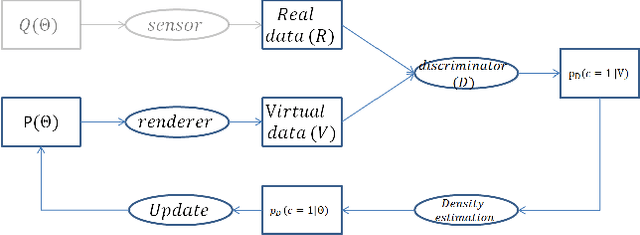
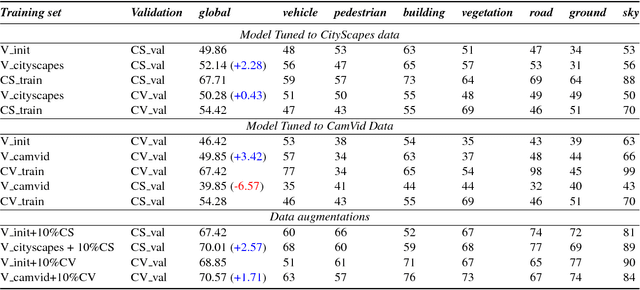

Generalization performance of trained computer vision systems that use computer graphics (CG) generated data is not yet effective due to the concept of 'domain-shift' between virtual and real data. Although simulated data augmented with a few real world samples has been shown to mitigate domain shift and improve transferability of trained models, guiding or bootstrapping the virtual data generation with the distributions learnt from target real world domain is desired, especially in the fields where annotating even few real images is laborious (such as semantic labeling, and intrinsic images etc.). In order to address this problem in an unsupervised manner, our work combines recent advances in CG (which aims to generate stochastic scene layouts coupled with large collections of 3D object models) and generative adversarial training (which aims train generative models by measuring discrepancy between generated and real data in terms of their separability in the space of a deep discriminatively-trained classifier). Our method uses iterative estimation of the posterior density of prior distributions for a generative graphical model. This is done within a rejection sampling framework. Initially, we assume uniform distributions as priors on the parameters of a scene described by a generative graphical model. As iterations proceed the prior distributions get updated to distributions that are closer to the (unknown) distributions of target data. We demonstrate the utility of adversarially tuned scene generation on two real-world benchmark datasets (CityScapes and CamVid) for traffic scene semantic labeling with a deep convolutional net (DeepLab). We realized performance improvements by 2.28 and 3.14 points (using the IoU metric) between the DeepLab models trained on simulated sets prepared from the scene generation models before and after tuning to CityScapes and CamVid respectively.
Model-driven Simulations for Deep Convolutional Neural Networks
May 31, 2016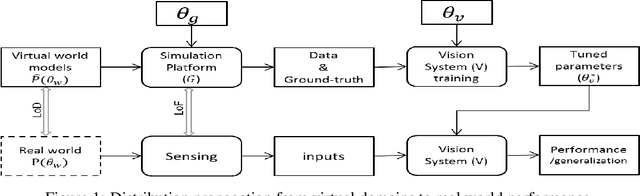
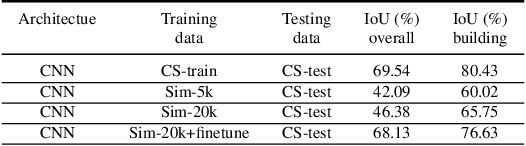


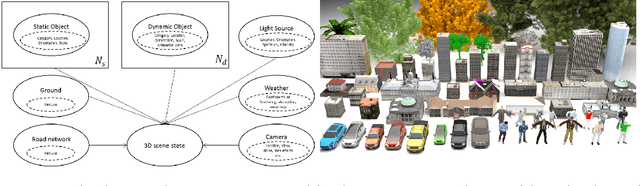
The use of simulated virtual environments to train deep convolutional neural networks (CNN) is a currently active practice to reduce the (real)data-hungriness of the deep CNN models, especially in application domains in which large scale real data and/or groundtruth acquisition is difficult or laborious. Recent approaches have attempted to harness the capabilities of existing video games, animated movies to provide training data with high precision groundtruth. However, a stumbling block is in how one can certify generalization of the learned models and their usefulness in real world data sets. This opens up fundamental questions such as: What is the role of photorealism of graphics simulations in training CNN models? Are the trained models valid in reality? What are possible ways to reduce the performance bias? In this work, we begin to address theses issues systematically in the context of urban semantic understanding with CNNs. Towards this end, we (a) propose a simple probabilistic urban scene model, (b) develop a parametric rendering tool to synthesize the data with groundtruth, followed by (c) a systematic exploration of the impact of level-of-realism on the generality of the trained CNN model to real world; and domain adaptation concepts to minimize the performance bias.
Model Validation for Vision Systems via Graphics Simulation
Dec 04, 2015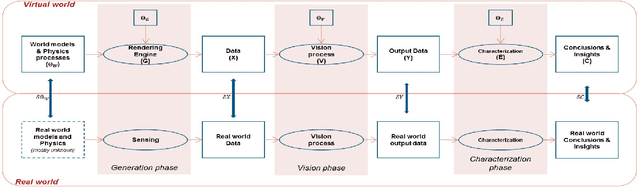
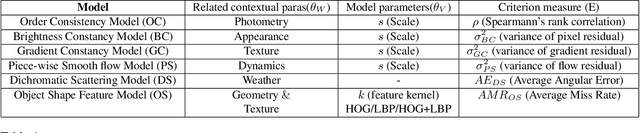

Rapid advances in computation, combined with latest advances in computer graphics simulations have facilitated the development of vision systems and training them in virtual environments. One major stumbling block is in certification of the designs and tuned parameters of these systems to work in real world. In this paper, we begin to explore the fundamental question: Which type of information transfer is more analogous to real world? Inspired from the performance characterization methodology outlined in the 90's, we note that insights derived from simulations can be qualitative or quantitative depending on the degree of the fidelity of models used in simulations and the nature of the questions posed by the experimenter. We adapt the methodology in the context of current graphics simulation tools for modeling data generation processes and, for systematic performance characterization and trade-off analysis for vision system design leading to qualitative and quantitative insights. In concrete, we examine invariance assumptions used in vision algorithms for video surveillance settings as a case study and assess the degree to which those invariance assumptions deviate as a function of contextual variables on both graphics simulations and in real data. As computer graphics rendering quality improves, we believe teasing apart the degree to which model assumptions are valid via systematic graphics simulation can be a significant aid to assisting more principled ways of approaching vision system design and performance modeling.
Simulations for Validation of Vision Systems
Dec 03, 2015
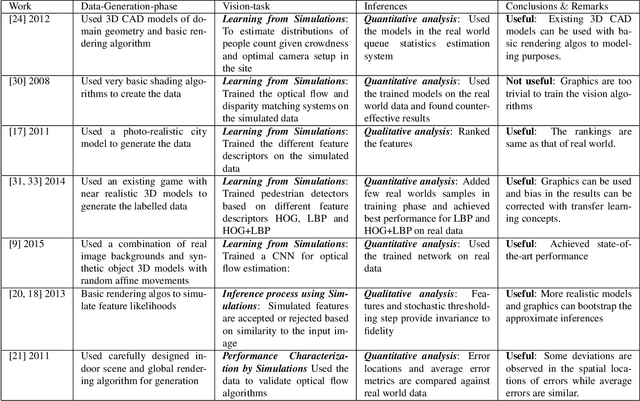
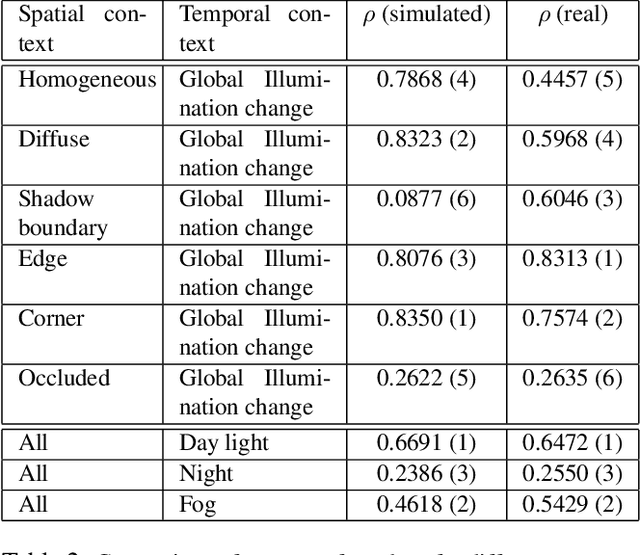

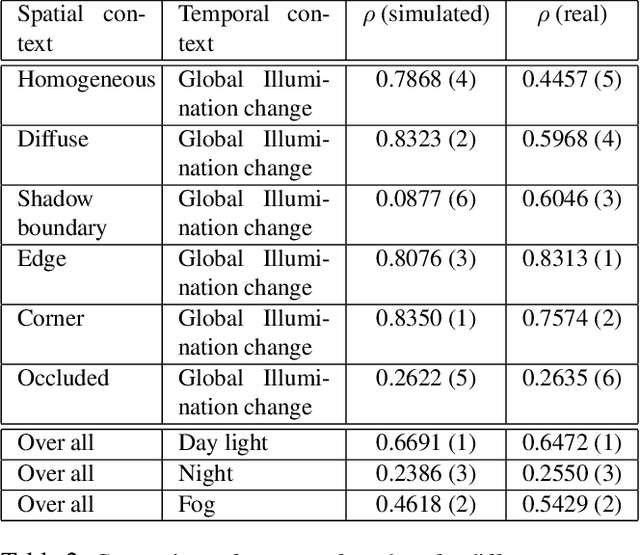
As the computer vision matures into a systems science and engineering discipline, there is a trend in leveraging latest advances in computer graphics simulations for performance evaluation, learning, and inference. However, there is an open question on the utility of graphics simulations for vision with apparently contradicting views in the literature. In this paper, we place the results from the recent literature in the context of performance characterization methodology outlined in the 90's and note that insights derived from simulations can be qualitative or quantitative depending on the degree of fidelity of models used in simulation and the nature of the question posed by the experimenter. We describe a simulation platform that incorporates latest graphics advances and use it for systematic performance characterization and trade-off analysis for vision system design. We verify the utility of the platform in a case study of validating a generative model inspired vision hypothesis, Rank-Order consistency model, in the contexts of global and local illumination changes, and bad weather, and high-frequency noise. Our approach establishes the link between alternative viewpoints, involving models with physics based semantics and signal and perturbation semantics and confirms insights in literature on robust change detection.