 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Shape Reconstruction with Geometry-Guided Langevin Dynamics
Mar 27, 2026Reconstructing complete 3D shapes from incomplete or noisy observations is a fundamentally ill-posed problem that requires balancing measurement consistency with shape plausibility. Existing methods for shape reconstruction can achieve strong geometric fidelity in ideal conditions but fail under realistic conditions with incomplete measurements or noise. At the same time, recent generative models for 3D shapes can synthesize highly realistic and detailed shapes but fail to be consistent with observed measurements. In this work, we introduce GG-Langevin: Geometry-Guided Langevin dynamics, a probabilistic approach that unifies these complementary perspectives. By traversing the trajectories of Langevin dynamics induced by a diffusion model, while preserving measurement consistency at every step, we generatively reconstruct shapes that fit both the measurements and the data-informed prior. We demonstrate through extensive experiments that GG-Langevin achieves higher geometric accuracy and greater robustness to missing data than existing methods for surface reconstruction.
FlowFeat: Pixel-Dense Embedding of Motion Profiles
Nov 10, 2025Dense and versatile image representations underpin the success of virtually all computer vision applications. However, state-of-the-art networks, such as transformers, produce low-resolution feature grids, which are suboptimal for dense prediction tasks. To address this limitation, we present FlowFeat, a high-resolution and multi-task feature representation. The key ingredient behind FlowFeat is a novel distillation technique that embeds a distribution of plausible apparent motions, or motion profiles. By leveraging optical flow networks and diverse video data, we develop an effective self-supervised training framework that statistically approximates the apparent motion. With its remarkable level of spatial detail, FlowFeat encodes a compelling degree of geometric and semantic cues while exhibiting high temporal consistency. Empirically, FlowFeat significantly enhances the representational power of five state-of-the-art encoders and alternative upsampling strategies across three dense tasks: video object segmentation, monocular depth estimation and semantic segmentation. Training FlowFeat is computationally inexpensive and robust to inaccurate flow estimation, remaining highly effective even when using unsupervised flow networks. Our work takes a step forward towards reliable and versatile dense image representations.
Back on Track: Bundle Adjustment for Dynamic Scene Reconstruction
Apr 20, 2025Traditional SLAM systems, which rely on bundle adjustment, struggle with highly dynamic scenes commonly found in casual videos. Such videos entangle the motion of dynamic elements, undermining the assumption of static environments required by traditional systems. Existing techniques either filter out dynamic elements or model their motion independently. However, the former often results in incomplete reconstructions, whereas the latter can lead to inconsistent motion estimates. Taking a novel approach, this work leverages a 3D point tracker to separate the camera-induced motion from the observed motion of dynamic objects. By considering only the camera-induced component, bundle adjustment can operate reliably on all scene elements as a result. We further ensure depth consistency across video frames with lightweight post-processing based on scale maps. Our framework combines the core of traditional SLAM -- bundle adjustment -- with a robust learning-based 3D tracker front-end. Integrating motion decomposition, bundle adjustment and depth refinement, our unified framework, BA-Track, accurately tracks the camera motion and produces temporally coherent and scale-consistent dense reconstructions, accommodating both static and dynamic elements. Our experiments on challenging datasets reveal significant improvements in camera pose estimation and 3D reconstruction accuracy.
Scene-Centric Unsupervised Panoptic Segmentation
Apr 02, 2025Unsupervised panoptic segmentation aims to partition an image into semantically meaningful regions and distinct object instances without training on manually annotated data. In contrast to prior work on unsupervised panoptic scene understanding, we eliminate the need for object-centric training data, enabling the unsupervised understanding of complex scenes. To that end, we present the first unsupervised panoptic method that directly trains on scene-centric imagery. In particular, we propose an approach to obtain high-resolution panoptic pseudo labels on complex scene-centric data, combining visual representations, depth, and motion cues. Utilizing both pseudo-label training and a panoptic self-training strategy yields a novel approach that accurately predicts panoptic segmentation of complex scenes without requiring any human annotations. Our approach significantly improves panoptic quality, e.g., surpassing the recent state of the art in unsupervised panoptic segmentation on Cityscapes by 9.4% points in PQ.
It's a (Blind) Match! Towards Vision-Language Correspondence without Parallel Data
Mar 31, 2025The platonic representation hypothesis suggests that vision and language embeddings become more homogeneous as model and dataset sizes increase. In particular, pairwise distances within each modality become more similar. This suggests that as foundation models mature, it may become possible to match vision and language embeddings in a fully unsupervised fashion, i.e. without parallel data. We present the first feasibility study, and investigate conformity of existing vision and language foundation models in the context of unsupervised, or "blind", matching. First, we formulate unsupervised matching as a quadratic assignment problem and introduce a novel heuristic that outperforms previous solvers. We also develop a technique to find optimal matching problems, for which a non-trivial match is very likely. Second, we conduct an extensive study deploying a range of vision and language models on four datasets. Our analysis reveals that for many problem instances, vision and language representations can be indeed matched without supervision. This finding opens up the exciting possibility of embedding semantic knowledge into other modalities virtually annotation-free. As a proof of concept, we showcase an unsupervised classifier, which achieves non-trivial classification accuracy without any image-text annotation.
CARLA Drone: Monocular 3D Object Detection from a Different Perspective
Aug 21, 2024



Existing techniques for monocular 3D detection have a serious restriction. They tend to perform well only on a limited set of benchmarks, faring well either on ego-centric car views or on traffic camera views, but rarely on both. To encourage progress, this work advocates for an extended evaluation of 3D detection frameworks across different camera perspectives. We make two key contributions. First, we introduce the CARLA Drone dataset, CDrone. Simulating drone views, it substantially expands the diversity of camera perspectives in existing benchmarks. Despite its synthetic nature, CDrone represents a real-world challenge. To show this, we confirm that previous techniques struggle to perform well both on CDrone and a real-world 3D drone dataset. Second, we develop an effective data augmentation pipeline called GroundMix. Its distinguishing element is the use of the ground for creating 3D-consistent augmentation of a training image. GroundMix significantly boosts the detection accuracy of a lightweight one-stage detector. In our expanded evaluation, we achieve the average precision on par with or substantially higher than the previous state of the art across all tested datasets.
DiffCD: A Symmetric Differentiable Chamfer Distance for Neural Implicit Surface Fitting
Jul 24, 2024Neural implicit surfaces can be used to recover accurate 3D geometry from imperfect point clouds. In this work, we show that state-of-the-art techniques work by minimizing an approximation of a one-sided Chamfer distance. This shape metric is not symmetric, as it only ensures that the point cloud is near the surface but not vice versa. As a consequence, existing methods can produce inaccurate reconstructions with spurious surfaces. Although one approach against spurious surfaces has been widely used in the literature, we theoretically and experimentally show that it is equivalent to regularizing the surface area, resulting in over-smoothing. As a more appealing alternative, we propose DiffCD, a novel loss function corresponding to the symmetric Chamfer distance. In contrast to previous work, DiffCD also assures that the surface is near the point cloud, which eliminates spurious surfaces without the need for additional regularization. We experimentally show that DiffCD reliably recovers a high degree of shape detail, substantially outperforming existing work across varying surface complexity and noise levels. Project code is available at https://github.com/linusnie/diffcd.
Boosting Unsupervised Semantic Segmentation with Principal Mask Proposals
Apr 25, 2024



Unsupervised semantic segmentation aims to automatically partition images into semantically meaningful regions by identifying global categories within an image corpus without any form of annotation. Building upon recent advances in self-supervised representation learning, we focus on how to leverage these large pre-trained models for the downstream task of unsupervised segmentation. We present PriMaPs - Principal Mask Proposals - decomposing images into semantically meaningful masks based on their feature representation. This allows us to realize unsupervised semantic segmentation by fitting class prototypes to PriMaPs with a stochastic expectation-maximization algorithm, PriMaPs-EM. Despite its conceptual simplicity, PriMaPs-EM leads to competitive results across various pre-trained backbone models, including DINO and DINOv2, and across datasets, such as Cityscapes, COCO-Stuff, and Potsdam-3. Importantly, PriMaPs-EM is able to boost results when applied orthogonally to current state-of-the-art unsupervised semantic segmentation pipelines.
Flattening the Parent Bias: Hierarchical Semantic Segmentation in the Poincaré Ball
Apr 15, 2024Hierarchy is a natural representation of semantic taxonomies, including the ones routinely used in image segmentation. Indeed, recent work on semantic segmentation reports improved accuracy from supervised training leveraging hierarchical label structures. Encouraged by these results, we revisit the fundamental assumptions behind that work. We postulate and then empirically verify that the reasons for the observed improvement in segmentation accuracy may be entirely unrelated to the use of the semantic hierarchy. To demonstrate this, we design a range of cross-domain experiments with a representative hierarchical approach. We find that on the new testing domains, a flat (non-hierarchical) segmentation network, in which the parents are inferred from the children, has superior segmentation accuracy to the hierarchical approach across the board. Complementing these findings and inspired by the intrinsic properties of hyperbolic spaces, we study a more principled approach to hierarchical segmentation using the Poincar\'e ball model. The hyperbolic representation largely outperforms the previous (Euclidean) hierarchical approach as well and is on par with our flat Euclidean baseline in terms of segmentation accuracy. However, it additionally exhibits surprisingly strong calibration quality of the parent nodes in the semantic hierarchy, especially on the more challenging domains. Our combined analysis suggests that the established practice of hierarchical segmentation may be limited to in-domain settings, whereas flat classifiers generalize substantially better, especially if they are modeled in the hyperbolic space.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022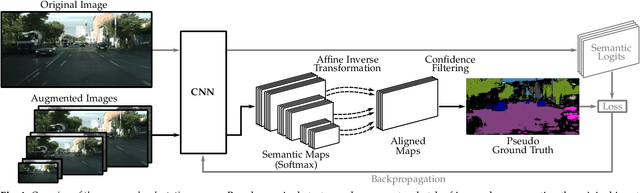


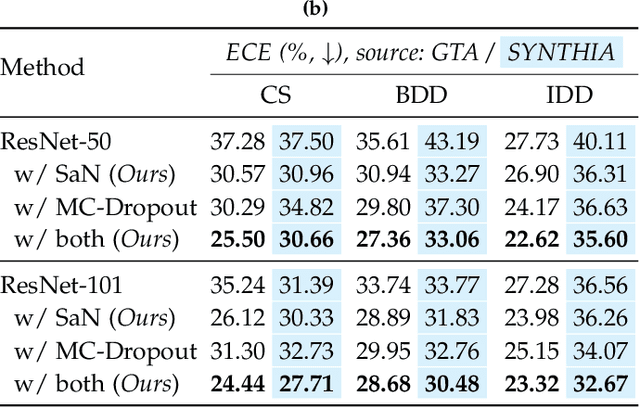
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.