 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounDiff: Diffusion-Based Ground Surface Generation from Digital Surface Models
Nov 13, 2025Digital Terrain Models (DTMs) represent the bare-earth elevation and are important in numerous geospatial applications. Such data models cannot be directly measured by sensors and are typically generated from Digital Surface Models (DSMs) derived from LiDAR or photogrammetry. Traditional filtering approaches rely on manually tuned parameters, while learning-based methods require well-designed architectures, often combined with post-processing. To address these challenges, we introduce Ground Diffusion (GrounDiff), the first diffusion-based framework that iteratively removes non-ground structures by formulating the problem as a denoising task. We incorporate a gated design with confidence-guided generation that enables selective filtering. To increase scalability, we further propose Prior-Guided Stitching (PrioStitch), which employs a downsampled global prior automatically generated using GrounDiff to guide local high-resolution predictions. We evaluate our method on the DSM-to-DTM translation task across diverse datasets, showing that GrounDiff consistently outperforms deep learning-based state-of-the-art methods, reducing RMSE by up to 93% on ALS2DTM and up to 47% on USGS benchmarks. In the task of road reconstruction, which requires both high precision and smoothness, our method achieves up to 81% lower distance error compared to specialized techniques on the GeRoD benchmark, while maintaining competitive surface smoothness using only DSM inputs, without task-specific optimization. Our variant for road reconstruction, GrounDiff+, is specifically designed to produce even smoother surfaces, further surpassing state-of-the-art methods. The project page is available at https://deepscenario.github.io/GrounDiff/.
Highly Accurate and Diverse Traffic Data: The DeepScenario Open 3D Dataset
Apr 24, 2025



Accurate 3D trajectory data is crucial for advancing autonomous driving. Yet, traditional datasets are usually captured by fixed sensors mounted on a car and are susceptible to occlusion. Additionally, such an approach can precisely reconstruct the dynamic environment in the close vicinity of the measurement vehicle only, while neglecting objects that are further away. In this paper, we introduce the DeepScenario Open 3D Dataset (DSC3D), a high-quality, occlusion-free dataset of 6 degrees of freedom bounding box trajectories acquired through a novel monocular camera drone tracking pipeline. Our dataset includes more than 175,000 trajectories of 14 types of traffic participants and significantly exceeds existing datasets in terms of diversity and scale, containing many unprecedented scenarios such as complex vehicle-pedestrian interaction on highly populated urban streets and comprehensive parking maneuvers from entry to exit. DSC3D dataset was captured in five various locations in Europe and the United States and include: a parking lot, a crowded inner-city, a steep urban intersection, a federal highway, and a suburban intersection. Our 3D trajectory dataset aims to enhance autonomous driving systems by providing detailed environmental 3D representations, which could lead to improved obstacle interactions and safety. We demonstrate its utility across multiple applications including motion prediction, motion planning, scenario mining, and generative reactive traffic agents. Our interactive online visualization platform and the complete dataset are publicly available at app.deepscenario.com, facilitating research in motion prediction, behavior modeling, and safety validation.
Shape Your Ground: Refining Road Surfaces Beyond Planar Representations
Apr 15, 2025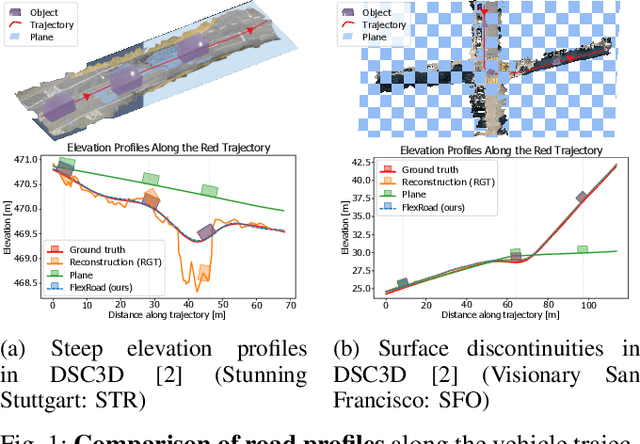



Road surface reconstruction from aerial images is fundamental for autonomous driving, urban planning, and virtual simulation, where smoothness, compactness, and accuracy are critical quality factors. Existing reconstruction methods often produce artifacts and inconsistencies that limit usability, while downstream tasks have a tendency to represent roads as planes for simplicity but at the cost of accuracy. We introduce FlexRoad, the first framework to directly address road surface smoothing by fitting Non-Uniform Rational B-Splines (NURBS) surfaces to 3D road points obtained from photogrammetric reconstructions or geodata providers. Our method at its core utilizes the Elevation-Constrained Spatial Road Clustering (ECSRC) algorithm for robust anomaly correction, significantly reducing surface roughness and fitting errors. To facilitate quantitative comparison between road surface reconstruction methods, we present GeoRoad Dataset (GeRoD), a diverse collection of road surface and terrain profiles derived from openly accessible geodata. Experiments on GeRoD and the photogrammetry-based DeepScenario Open 3D Dataset (DSC3D) demonstrate that FlexRoad considerably surpasses commonly used road surface representations across various metrics while being insensitive to various input sources, terrains, and noise types. By performing ablation studies, we identify the key role of each component towards high-quality reconstruction performance, making FlexRoad a generic method for realistic road surface modeling.
MonoCT: Overcoming Monocular 3D Detection Domain Shift with Consistent Teacher Models
Mar 17, 2025We tackle the problem of monocular 3D object detection across different sensors, environments, and camera setups. In this paper, we introduce a novel unsupervised domain adaptation approach, MonoCT, that generates highly accurate pseudo labels for self-supervision. Inspired by our observation that accurate depth estimation is critical to mitigating domain shifts, MonoCT introduces a novel Generalized Depth Enhancement (GDE) module with an ensemble concept to improve depth estimation accuracy. Moreover, we introduce a novel Pseudo Label Scoring (PLS) module by exploring inner-model consistency measurement and a Diversity Maximization (DM) strategy to further generate high-quality pseudo labels for self-training. Extensive experiments on six benchmarks show that MonoCT outperforms existing SOTA domain adaptation methods by large margins (~21% minimum for AP Mod.) and generalizes well to car, traffic camera and drone views.
CARLA Drone: Monocular 3D Object Detection from a Different Perspective
Aug 21, 2024



Existing techniques for monocular 3D detection have a serious restriction. They tend to perform well only on a limited set of benchmarks, faring well either on ego-centric car views or on traffic camera views, but rarely on both. To encourage progress, this work advocates for an extended evaluation of 3D detection frameworks across different camera perspectives. We make two key contributions. First, we introduce the CARLA Drone dataset, CDrone. Simulating drone views, it substantially expands the diversity of camera perspectives in existing benchmarks. Despite its synthetic nature, CDrone represents a real-world challenge. To show this, we confirm that previous techniques struggle to perform well both on CDrone and a real-world 3D drone dataset. Second, we develop an effective data augmentation pipeline called GroundMix. Its distinguishing element is the use of the ground for creating 3D-consistent augmentation of a training image. GroundMix significantly boosts the detection accuracy of a lightweight one-stage detector. In our expanded evaluation, we achieve the average precision on par with or substantially higher than the previous state of the art across all tested datasets.
NIFF: Alleviating Forgetting in Generalized Few-Shot Object Detection via Neural Instance Feature Forging
Mar 09, 2023Privacy and memory are two recurring themes in a broad conversation about the societal impact of AI. These concerns arise from the need for huge amounts of data to train deep neural networks. A promise of Generalized Few-shot Object Detection (G-FSOD), a learning paradigm in AI, is to alleviate the need for collecting abundant training samples of novel classes we wish to detect by leveraging prior knowledge from old classes (i.e., base classes). G-FSOD strives to learn these novel classes while alleviating catastrophic forgetting of the base classes. However, existing approaches assume that the base images are accessible, an assumption that does not hold when sharing and storing data is problematic. In this work, we propose the first data-free knowledge distillation (DFKD) approach for G-FSOD that leverages the statistics of the region of interest (RoI) features from the base model to forge instance-level features without accessing the base images. Our contribution is three-fold: (1) we design a standalone lightweight generator with (2) class-wise heads (3) to generate and replay diverse instance-level base features to the RoI head while finetuning on the novel data. This stands in contrast to standard DFKD approaches in image classification, which invert the entire network to generate base images. Moreover, we make careful design choices in the novel finetuning pipeline to regularize the model. We show that our approach can dramatically reduce the base memory requirements, all while setting a new standard for G-FSOD on the challenging MS-COCO and PASCAL-VOC benchmarks.
A Robust Unsupervised Ensemble of Feature-Based Explanations using Restricted Boltzmann Machines
Nov 14, 2021
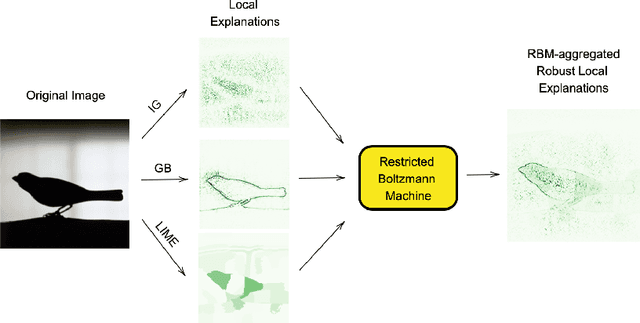
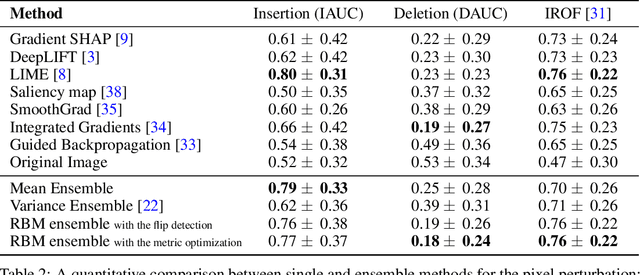

Understanding the results of deep neural networks is an essential step towards wider acceptance of deep learning algorithms. Many approaches address the issue of interpreting artificial neural networks, but often provide divergent explanations. Moreover, different hyperparameters of an explanatory method can lead to conflicting interpretations. In this paper, we propose a technique for aggregating the feature attributions of different explanatory algorithms using Restricted Boltzmann Machines (RBMs) to achieve a more reliable and robust interpretation of deep neural networks. Several challenging experiments on real-world datasets show that the proposed RBM method outperforms popular feature attribution methods and basic ensemble techniques.