 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVAR: Co-generation of Video and Action for Robotic Manipulation via Multi-Modal Diffusion
Dec 17, 2025We present a method to generate video-action pairs that follow text instructions, starting from an initial image observation and the robot's joint states. Our approach automatically provides action labels for video diffusion models, overcoming the common lack of action annotations and enabling their full use for robotic policy learning. Existing methods either adopt two-stage pipelines, which limit tightly coupled cross-modal information sharing, or rely on adapting a single-modal diffusion model for a joint distribution that cannot fully leverage pretrained video knowledge. To overcome these limitations, we (1) extend a pretrained video diffusion model with a parallel, dedicated action diffusion model that preserves pretrained knowledge, (2) introduce a Bridge Attention mechanism to enable effective cross-modal interaction, and (3) design an action refinement module to convert coarse actions into precise controls for low-resolution datasets. Extensive evaluations on multiple public benchmarks and real-world datasets demonstrate that our method generates higher-quality videos, more accurate actions, and significantly outperforms existing baselines, offering a scalable framework for leveraging large-scale video data for robotic learning.
DRAW2ACT: Turning Depth-Encoded Trajectories into Robotic Demonstration Videos
Dec 16, 2025Video diffusion models provide powerful real-world simulators for embodied AI but remain limited in controllability for robotic manipulation. Recent works on trajectory-conditioned video generation address this gap but often rely on 2D trajectories or single modality conditioning, which restricts their ability to produce controllable and consistent robotic demonstrations. We present DRAW2ACT, a depth-aware trajectory-conditioned video generation framework that extracts multiple orthogonal representations from the input trajectory, capturing depth, semantics, shape and motion, and injects them into the diffusion model. Moreover, we propose to jointly generate spatially aligned RGB and depth videos, leveraging cross-modality attention mechanisms and depth supervision to enhance the spatio-temporal consistency. Finally, we introduce a multimodal policy model conditioned on the generated RGB and depth sequences to regress the robot's joint angles. Experiments on Bridge V2, Berkeley Autolab, and simulation benchmarks show that DRAW2ACT achieves superior visual fidelity and consistency while yielding higher manipulation success rates compared to existing baselines.
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Jun 10, 2025Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
ConsistentDreamer: View-Consistent Meshes Through Balanced Multi-View Gaussian Optimization
Feb 13, 2025Recent advances in diffusion models have significantly improved 3D generation, enabling the use of assets generated from an image for embodied AI simulations. However, the one-to-many nature of the image-to-3D problem limits their use due to inconsistent content and quality across views. Previous models optimize a 3D model by sampling views from a view-conditioned diffusion prior, but diffusion models cannot guarantee view consistency. Instead, we present ConsistentDreamer, where we first generate a set of fixed multi-view prior images and sample random views between them with another diffusion model through a score distillation sampling (SDS) loss. Thereby, we limit the discrepancies between the views guided by the SDS loss and ensure a consistent rough shape. In each iteration, we also use our generated multi-view prior images for fine-detail reconstruction. To balance between the rough shape and the fine-detail optimizations, we introduce dynamic task-dependent weights based on homoscedastic uncertainty, updated automatically in each iteration. Additionally, we employ opacity, depth distortion, and normal alignment losses to refine the surface for mesh extraction. Our method ensures better view consistency and visual quality compared to the state-of-the-art.
An Empirical Study of the Generalization Ability of Lidar 3D Object Detectors to Unseen Domains
Feb 27, 20243D Object Detectors (3D-OD) are crucial for understanding the environment in many robotic tasks, especially autonomous driving. Including 3D information via Lidar sensors improves accuracy greatly. However, such detectors perform poorly on domains they were not trained on, i.e. different locations, sensors, weather, etc., limiting their reliability in safety-critical applications. There exist methods to adapt 3D-ODs to these domains; however, these methods treat 3D-ODs as a black box, neglecting underlying architectural decisions and source-domain training strategies. Instead, we dive deep into the details of 3D-ODs, focusing our efforts on fundamental factors that influence robustness prior to domain adaptation. We systematically investigate four design choices (and the interplay between them) often overlooked in 3D-OD robustness and domain adaptation: architecture, voxel encoding, data augmentations, and anchor strategies. We assess their impact on the robustness of nine state-of-the-art 3D-ODs across six benchmarks encompassing three types of domain gaps - sensor type, weather, and location. Our main findings are: (1) transformer backbones with local point features are more robust than 3D CNNs, (2) test-time anchor size adjustment is crucial for adaptation across geographical locations, significantly boosting scores without retraining, (3) source-domain augmentations allow the model to generalize to low-resolution sensors, and (4) surprisingly, robustness to bad weather is improved when training directly on more clean weather data than on training with bad weather data. We outline our main conclusions and findings to provide practical guidance on developing more robust 3D-ODs.
A Semi-Paired Approach For Label-to-Image Translation
Jun 26, 2023Data efficiency, or the ability to generalize from a few labeled data, remains a major challenge in deep learning. Semi-supervised learning has thrived in traditional recognition tasks alleviating the need for large amounts of labeled data, yet it remains understudied in image-to-image translation (I2I) tasks. In this work, we introduce the first semi-supervised (semi-paired) framework for label-to-image translation, a challenging subtask of I2I which generates photorealistic images from semantic label maps. In the semi-paired setting, the model has access to a small set of paired data and a larger set of unpaired images and labels. Instead of using geometrical transformations as a pretext task like previous works, we leverage an input reconstruction task by exploiting the conditional discriminator on the paired data as a reverse generator. We propose a training algorithm for this shared network, and we present a rare classes sampling algorithm to focus on under-represented classes. Experiments on 3 standard benchmarks show that the proposed model outperforms state-of-the-art unsupervised and semi-supervised approaches, as well as some fully supervised approaches while using a much smaller number of paired samples.
Towards Pragmatic Semantic Image Synthesis for Urban Scenes
May 16, 2023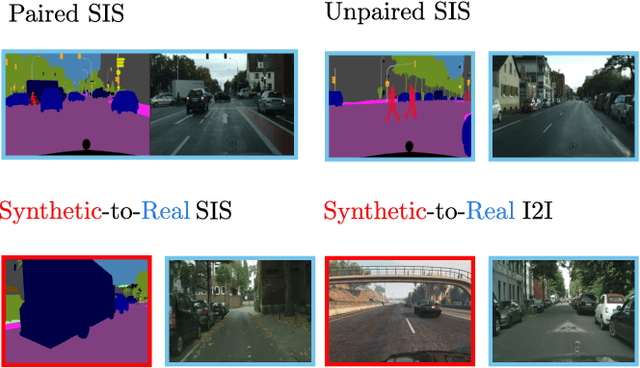


The need for large amounts of training and validation data is a huge concern in scaling AI algorithms for autonomous driving. Semantic Image Synthesis (SIS), or label-to-image translation, promises to address this issue by translating semantic layouts to images, providing a controllable generation of photorealistic data. However, they require a large amount of paired data, incurring extra costs. In this work, we present a new task: given a dataset with synthetic images and labels and a dataset with unlabeled real images, our goal is to learn a model that can generate images with the content of the input mask and the appearance of real images. This new task reframes the well-known unsupervised SIS task in a more practical setting, where we leverage cheaply available synthetic data from a driving simulator to learn how to generate photorealistic images of urban scenes. This stands in contrast to previous works, which assume that labels and images come from the same domain but are unpaired during training. We find that previous unsupervised works underperform on this task, as they do not handle distribution shifts between two different domains. To bypass these problems, we propose a novel framework with two main contributions. First, we leverage the synthetic image as a guide to the content of the generated image by penalizing the difference between their high-level features on a patch level. Second, in contrast to previous works which employ one discriminator that overfits the target domain semantic distribution, we employ a discriminator for the whole image and multiscale discriminators on the image patches. Extensive comparisons on the benchmarks GTA-V $\rightarrow$ Cityscapes and GTA-V $\rightarrow$ Mapillary show the superior performance of the proposed model against state-of-the-art on this task.
Urban-StyleGAN: Learning to Generate and Manipulate Images of Urban Scenes
May 16, 2023



A promise of Generative Adversarial Networks (GANs) is to provide cheap photorealistic data for training and validating AI models in autonomous driving. Despite their huge success, their performance on complex images featuring multiple objects is understudied. While some frameworks produce high-quality street scenes with little to no control over the image content, others offer more control at the expense of high-quality generation. A common limitation of both approaches is the use of global latent codes for the whole image, which hinders the learning of independent object distributions. Motivated by SemanticStyleGAN (SSG), a recent work on latent space disentanglement in human face generation, we propose a novel framework, Urban-StyleGAN, for urban scene generation and manipulation. We find that a straightforward application of SSG leads to poor results because urban scenes are more complex than human faces. To provide a more compact yet disentangled latent representation, we develop a class grouping strategy wherein individual classes are grouped into super-classes. Moreover, we employ an unsupervised latent exploration algorithm in the $\mathcal{S}$-space of the generator and show that it is more efficient than the conventional $\mathcal{W}^{+}$-space in controlling the image content. Results on the Cityscapes and Mapillary datasets show the proposed approach achieves significantly more controllability and improved image quality than previous approaches on urban scenes and is on par with general-purpose non-controllable generative models (like StyleGAN2) in terms of quality.
Wavelet-based Unsupervised Label-to-Image Translation
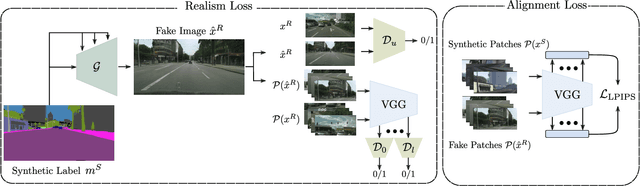
May 16, 2023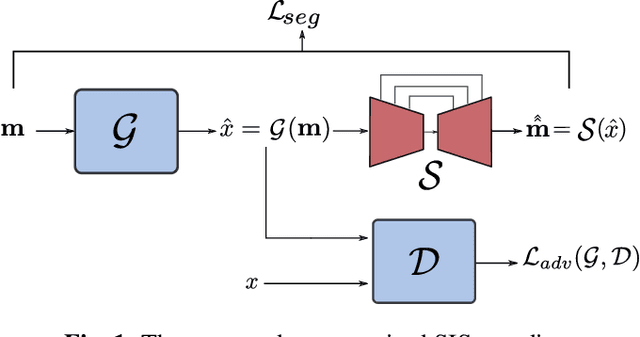
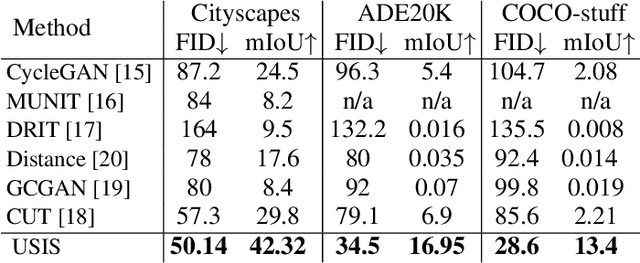
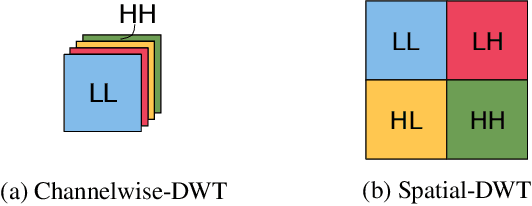
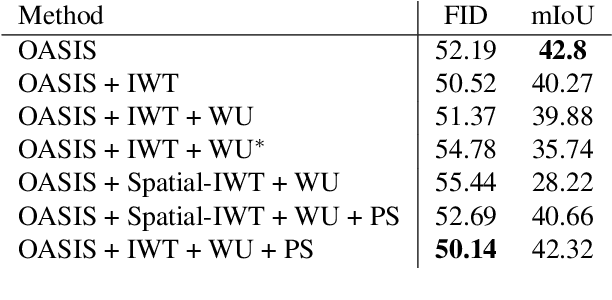
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.
NIFF: Alleviating Forgetting in Generalized Few-Shot Object Detection via Neural Instance Feature Forging
Mar 09, 2023Privacy and memory are two recurring themes in a broad conversation about the societal impact of AI. These concerns arise from the need for huge amounts of data to train deep neural networks. A promise of Generalized Few-shot Object Detection (G-FSOD), a learning paradigm in AI, is to alleviate the need for collecting abundant training samples of novel classes we wish to detect by leveraging prior knowledge from old classes (i.e., base classes). G-FSOD strives to learn these novel classes while alleviating catastrophic forgetting of the base classes. However, existing approaches assume that the base images are accessible, an assumption that does not hold when sharing and storing data is problematic. In this work, we propose the first data-free knowledge distillation (DFKD) approach for G-FSOD that leverages the statistics of the region of interest (RoI) features from the base model to forge instance-level features without accessing the base images. Our contribution is three-fold: (1) we design a standalone lightweight generator with (2) class-wise heads (3) to generate and replay diverse instance-level base features to the RoI head while finetuning on the novel data. This stands in contrast to standard DFKD approaches in image classification, which invert the entire network to generate base images. Moreover, we make careful design choices in the novel finetuning pipeline to regularize the model. We show that our approach can dramatically reduce the base memory requirements, all while setting a new standard for G-FSOD on the challenging MS-COCO and PASCAL-VOC benchmarks.