 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Pragmatic Semantic Image Synthesis for Urban Scenes
Paper and Code
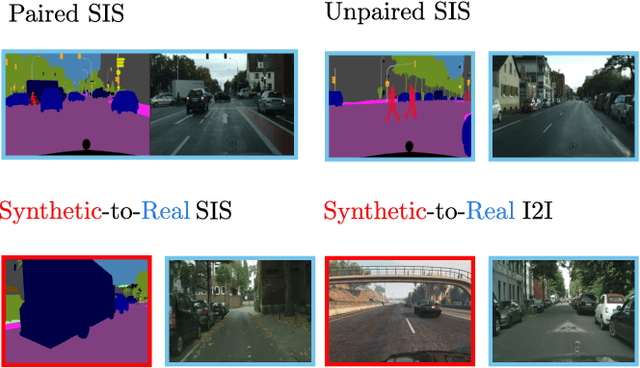

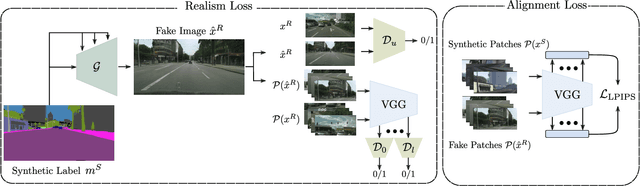

The need for large amounts of training and validation data is a huge concern in scaling AI algorithms for autonomous driving. Semantic Image Synthesis (SIS), or label-to-image translation, promises to address this issue by translating semantic layouts to images, providing a controllable generation of photorealistic data. However, they require a large amount of paired data, incurring extra costs. In this work, we present a new task: given a dataset with synthetic images and labels and a dataset with unlabeled real images, our goal is to learn a model that can generate images with the content of the input mask and the appearance of real images. This new task reframes the well-known unsupervised SIS task in a more practical setting, where we leverage cheaply available synthetic data from a driving simulator to learn how to generate photorealistic images of urban scenes. This stands in contrast to previous works, which assume that labels and images come from the same domain but are unpaired during training. We find that previous unsupervised works underperform on this task, as they do not handle distribution shifts between two different domains. To bypass these problems, we propose a novel framework with two main contributions. First, we leverage the synthetic image as a guide to the content of the generated image by penalizing the difference between their high-level features on a patch level. Second, in contrast to previous works which employ one discriminator that overfits the target domain semantic distribution, we employ a discriminator for the whole image and multiscale discriminators on the image patches. Extensive comparisons on the benchmarks GTA-V $\rightarrow$ Cityscapes and GTA-V $\rightarrow$ Mapillary show the superior performance of the proposed model against state-of-the-art on this task.