 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of the Generalization Ability of Lidar 3D Object Detectors to Unseen Domains
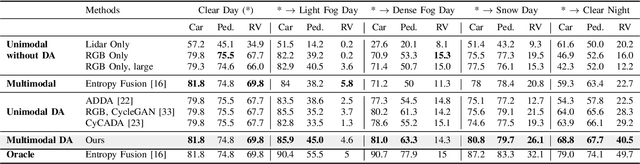
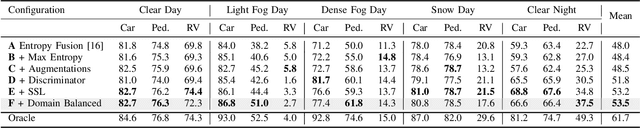
Feb 27, 20243D Object Detectors (3D-OD) are crucial for understanding the environment in many robotic tasks, especially autonomous driving. Including 3D information via Lidar sensors improves accuracy greatly. However, such detectors perform poorly on domains they were not trained on, i.e. different locations, sensors, weather, etc., limiting their reliability in safety-critical applications. There exist methods to adapt 3D-ODs to these domains; however, these methods treat 3D-ODs as a black box, neglecting underlying architectural decisions and source-domain training strategies. Instead, we dive deep into the details of 3D-ODs, focusing our efforts on fundamental factors that influence robustness prior to domain adaptation. We systematically investigate four design choices (and the interplay between them) often overlooked in 3D-OD robustness and domain adaptation: architecture, voxel encoding, data augmentations, and anchor strategies. We assess their impact on the robustness of nine state-of-the-art 3D-ODs across six benchmarks encompassing three types of domain gaps - sensor type, weather, and location. Our main findings are: (1) transformer backbones with local point features are more robust than 3D CNNs, (2) test-time anchor size adjustment is crucial for adaptation across geographical locations, significantly boosting scores without retraining, (3) source-domain augmentations allow the model to generalize to low-resolution sensors, and (4) surprisingly, robustness to bad weather is improved when training directly on more clean weather data than on training with bad weather data. We outline our main conclusions and findings to provide practical guidance on developing more robust 3D-ODs.
Urban-StyleGAN: Learning to Generate and Manipulate Images of Urban Scenes
May 16, 2023



A promise of Generative Adversarial Networks (GANs) is to provide cheap photorealistic data for training and validating AI models in autonomous driving. Despite their huge success, their performance on complex images featuring multiple objects is understudied. While some frameworks produce high-quality street scenes with little to no control over the image content, others offer more control at the expense of high-quality generation. A common limitation of both approaches is the use of global latent codes for the whole image, which hinders the learning of independent object distributions. Motivated by SemanticStyleGAN (SSG), a recent work on latent space disentanglement in human face generation, we propose a novel framework, Urban-StyleGAN, for urban scene generation and manipulation. We find that a straightforward application of SSG leads to poor results because urban scenes are more complex than human faces. To provide a more compact yet disentangled latent representation, we develop a class grouping strategy wherein individual classes are grouped into super-classes. Moreover, we employ an unsupervised latent exploration algorithm in the $\mathcal{S}$-space of the generator and show that it is more efficient than the conventional $\mathcal{W}^{+}$-space in controlling the image content. Results on the Cityscapes and Mapillary datasets show the proposed approach achieves significantly more controllability and improved image quality than previous approaches on urban scenes and is on par with general-purpose non-controllable generative models (like StyleGAN2) in terms of quality.
Towards Pragmatic Semantic Image Synthesis for Urban Scenes
May 16, 2023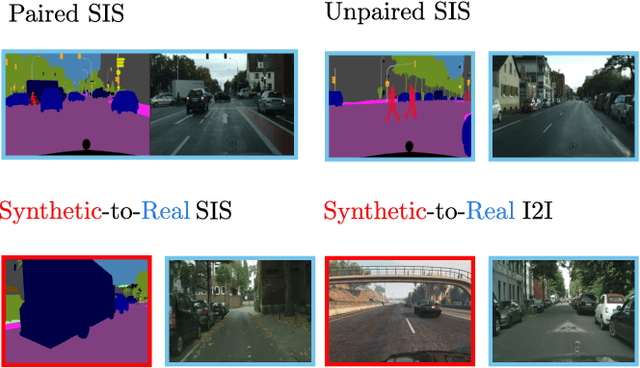

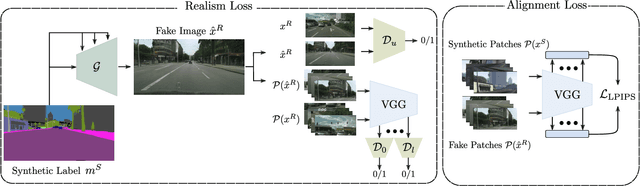

The need for large amounts of training and validation data is a huge concern in scaling AI algorithms for autonomous driving. Semantic Image Synthesis (SIS), or label-to-image translation, promises to address this issue by translating semantic layouts to images, providing a controllable generation of photorealistic data. However, they require a large amount of paired data, incurring extra costs. In this work, we present a new task: given a dataset with synthetic images and labels and a dataset with unlabeled real images, our goal is to learn a model that can generate images with the content of the input mask and the appearance of real images. This new task reframes the well-known unsupervised SIS task in a more practical setting, where we leverage cheaply available synthetic data from a driving simulator to learn how to generate photorealistic images of urban scenes. This stands in contrast to previous works, which assume that labels and images come from the same domain but are unpaired during training. We find that previous unsupervised works underperform on this task, as they do not handle distribution shifts between two different domains. To bypass these problems, we propose a novel framework with two main contributions. First, we leverage the synthetic image as a guide to the content of the generated image by penalizing the difference between their high-level features on a patch level. Second, in contrast to previous works which employ one discriminator that overfits the target domain semantic distribution, we employ a discriminator for the whole image and multiscale discriminators on the image patches. Extensive comparisons on the benchmarks GTA-V $\rightarrow$ Cityscapes and GTA-V $\rightarrow$ Mapillary show the superior performance of the proposed model against state-of-the-art on this task.
NIFF: Alleviating Forgetting in Generalized Few-Shot Object Detection via Neural Instance Feature Forging
Mar 09, 2023Privacy and memory are two recurring themes in a broad conversation about the societal impact of AI. These concerns arise from the need for huge amounts of data to train deep neural networks. A promise of Generalized Few-shot Object Detection (G-FSOD), a learning paradigm in AI, is to alleviate the need for collecting abundant training samples of novel classes we wish to detect by leveraging prior knowledge from old classes (i.e., base classes). G-FSOD strives to learn these novel classes while alleviating catastrophic forgetting of the base classes. However, existing approaches assume that the base images are accessible, an assumption that does not hold when sharing and storing data is problematic. In this work, we propose the first data-free knowledge distillation (DFKD) approach for G-FSOD that leverages the statistics of the region of interest (RoI) features from the base model to forge instance-level features without accessing the base images. Our contribution is three-fold: (1) we design a standalone lightweight generator with (2) class-wise heads (3) to generate and replay diverse instance-level base features to the RoI head while finetuning on the novel data. This stands in contrast to standard DFKD approaches in image classification, which invert the entire network to generate base images. Moreover, we make careful design choices in the novel finetuning pipeline to regularize the model. We show that our approach can dramatically reduce the base memory requirements, all while setting a new standard for G-FSOD on the challenging MS-COCO and PASCAL-VOC benchmarks.
Towards Discriminative and Transferable One-Stage Few-Shot Object Detectors
Oct 11, 2022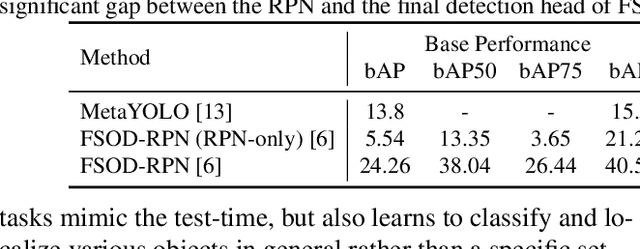
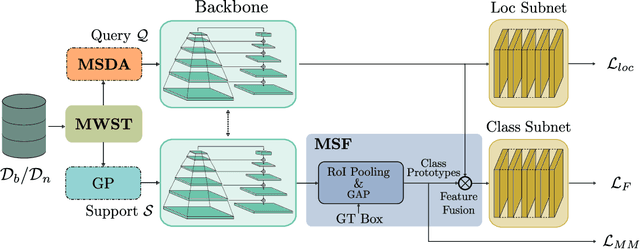
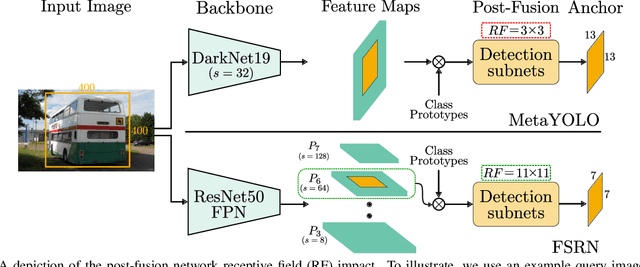
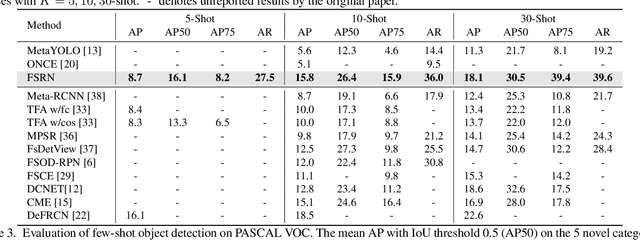
Recent object detection models require large amounts of annotated data for training a new classes of objects. Few-shot object detection (FSOD) aims to address this problem by learning novel classes given only a few samples. While competitive results have been achieved using two-stage FSOD detectors, typically one-stage FSODs underperform compared to them. We make the observation that the large gap in performance between two-stage and one-stage FSODs are mainly due to their weak discriminability, which is explained by a small post-fusion receptive field and a small number of foreground samples in the loss function. To address these limitations, we propose the Few-shot RetinaNet (FSRN) that consists of: a multi-way support training strategy to augment the number of foreground samples for dense meta-detectors, an early multi-level feature fusion providing a wide receptive field that covers the whole anchor area and two augmentation techniques on query and source images to enhance transferability. Extensive experiments show that the proposed approach addresses the limitations and boosts both discriminability and transferability. FSRN is almost two times faster than two-stage FSODs while remaining competitive in accuracy, and it outperforms the state-of-the-art of one-stage meta-detectors and also some two-stage FSODs on the MS-COCO and PASCAL VOC benchmarks.
CFA: Constraint-based Finetuning Approach for Generalized Few-Shot Object Detection
Apr 11, 2022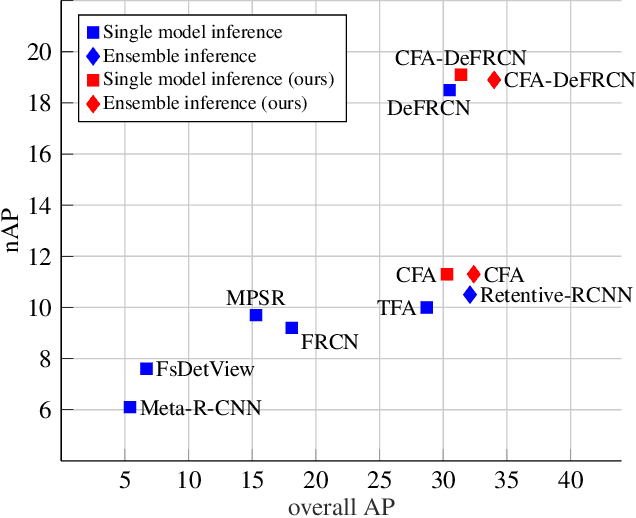
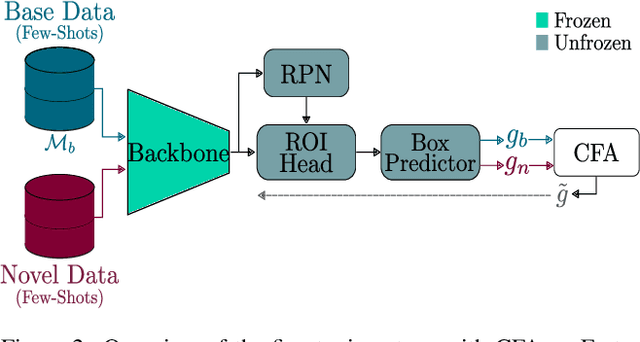
Few-shot object detection (FSOD) seeks to detect novel categories with limited data by leveraging prior knowledge from abundant base data. Generalized few-shot object detection (G-FSOD) aims to tackle FSOD without forgetting previously seen base classes and, thus, accounts for a more realistic scenario, where both classes are encountered during test time. While current FSOD methods suffer from catastrophic forgetting, G-FSOD addresses this limitation yet exhibits a performance drop on novel tasks compared to the state-of-the-art FSOD. In this work, we propose a constraint-based finetuning approach (CFA) to alleviate catastrophic forgetting, while achieving competitive results on the novel task without increasing the model capacity. CFA adapts a continual learning method, namely Average Gradient Episodic Memory (A-GEM) to G-FSOD. Specifically, more constraints on the gradient search strategy are imposed from which a new gradient update rule is derived, allowing for better knowledge exchange between base and novel classes. To evaluate our method, we conduct extensive experiments on MS-COCO and PASCAL-VOC datasets. Our method outperforms current FSOD and G-FSOD approaches on the novel task with minor degeneration on the base task. Moreover, CFA is orthogonal to FSOD approaches and operates as a plug-and-play module without increasing the model capacity or inference time.
Few-Shot Object Detection in Unseen Domains
Apr 11, 2022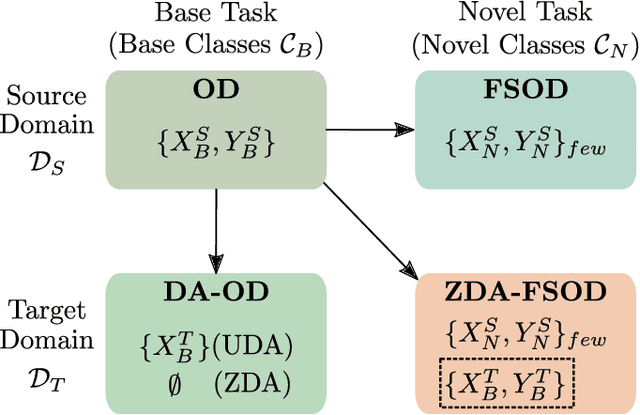
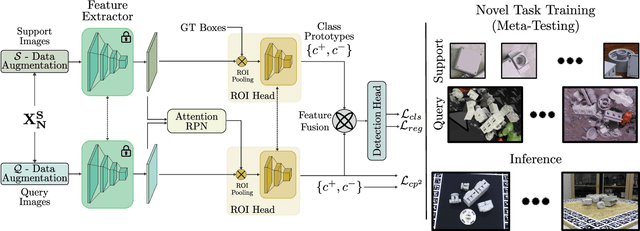

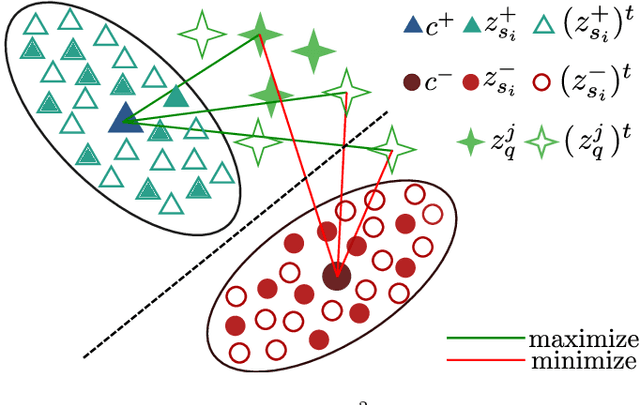
Few-shot object detection (FSOD) has thrived in recent years to learn novel object classes with limited data by transfering knowledge gained on abundant base classes. FSOD approaches commonly assume that both the scarcely provided examples of novel classes and test-time data belong to the same domain. However, this assumption does not hold in various industrial and robotics applications (e.g., object grasping and manipulation), where a model can learn novel classes from a source domain while inferring on classes from a different target domain. In this work, we address the task of zero-shot domain adaptation, also known as domain generalization, for FSOD. Specifically, we assume that neither images nor labels of the novel classes in the target domain are available during training. Our approach for solving the domain gap is two-fold. First, we leverage a meta-training paradigm, where we learn domain-invariant features on the base classes. Second, we propose various data augmentations techniques on the few shots of novel classes to account for all possible domain-specific information. To further constraint the network into encoding domain-agnostic class-specific representations only, a contrastive loss is proposed to maximize the mutual information between foreground proposals and class prototypes, and to reduce the network's bias to the background information. Our experiments on the T-LESS dataset show that the proposed approach succeeds in alleviating the domain gap considerably without utilizing labels or images of novel categories from the target domain.
An Unsupervised Domain Adaptive Approach for Multimodal 2D Object Detection in Adverse Weather Conditions
Mar 07, 2022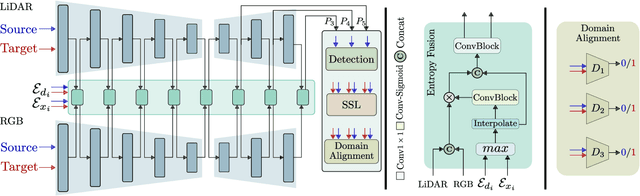
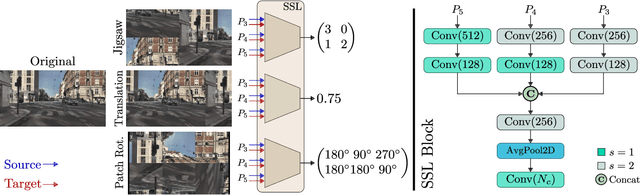
Integrating different representations from complementary sensing modalities is crucial for robust scene interpretation in autonomous driving. While deep learning architectures that fuse vision and range data for 2D object detection have thrived in recent years, the corresponding modalities can degrade in adverse weather or lighting conditions, ultimately leading to a drop in performance. Although domain adaptation methods attempt to bridge the domain gap between source and target domains, they do not readily extend to heterogeneous data distributions. In this work, we propose an unsupervised domain adaptation framework, which adapts a 2D object detector for RGB and lidar sensors to one or more target domains featuring adverse weather conditions. Our proposed approach consists of three components. First, a data augmentation scheme that simulates weather distortions is devised to add domain confusion and prevent overfitting on the source data. Second, to promote cross-domain foreground object alignment, we leverage the complementary features of multiple modalities through a multi-scale entropy-weighted domain discriminator. Finally, we use carefully designed pretext tasks to learn a more robust representation of the target domain data. Experiments performed on the DENSE dataset show that our method can substantially alleviate the domain gap under the single-target domain adaptation (STDA) setting and the less explored yet more general multi-target domain adaptation (MTDA) setting.
GLPU: A Geometric Approach For Lidar Pointcloud Upsampling
Feb 08, 2022



In autonomous driving, lidar is inherent for the understanding of the 3D environment. Lidar sensors vary in vertical resolutions, where a denser pointcloud depicts a more detailed environment, albeit at a significantly higher cost. Pointcloud upsampling predicts high-resolution pointclouds from sparser ones to bridge this performance gap at a lower cost. Although many upsampling frameworks have achieved a robust performance, a fair comparison is difficult as they were tested on different datasets and metrics. In this work, we first conduct a consistent comparative study to benchmark the existing algorithms on the KITTI dataset. Then, we observe that there are three common factors that hinder the performance: an inefficient data representation, a small receptive field, and low-frequency losses. By leveraging the scene geometry, a new self-supervised geometric lidar pointcloud upsampling (GLPU) framework is proposed to address the aforementioned limitations. Our experiments demonstrate the effectiveness and superior performance of GLPU compared to other techniques on the KITTI benchmark.
Investigating Cross-Domain Losses for Speech Enhancement
Oct 20, 2020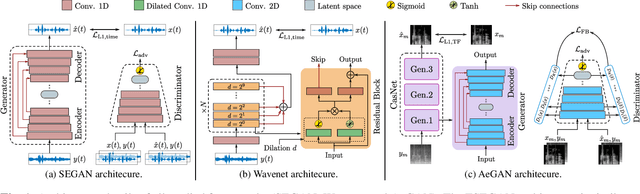
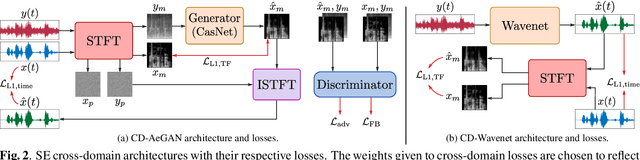
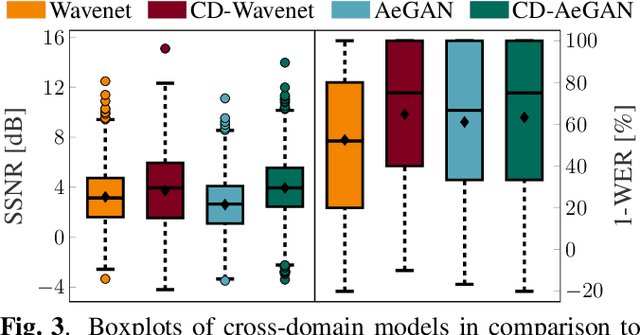
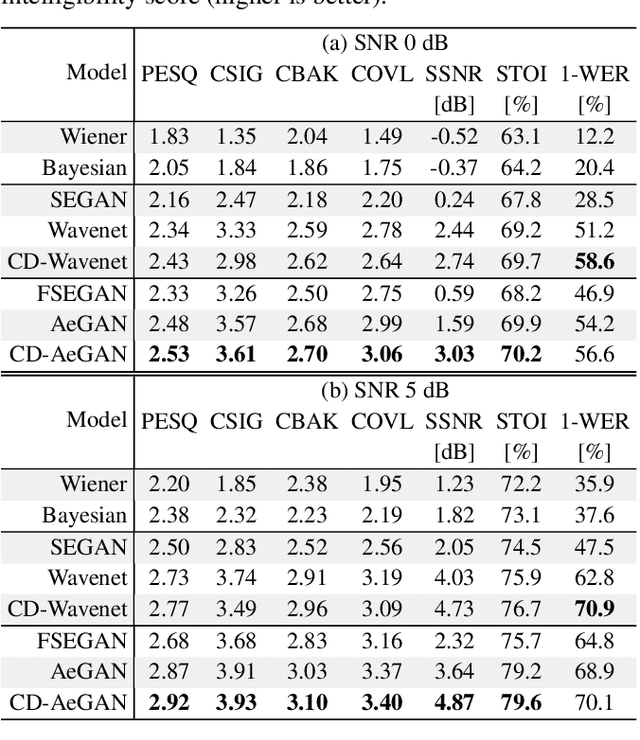
Recent years have seen a surge in the number of available frameworks for speech enhancement (SE) and recognition. Whether model-based or constructed via deep learning, these frameworks often rely in isolation on either time-domain signals or time-frequency (TF) representations of speech data. In this study, we investigate the advantages of each set of approaches by separately examining their impact on speech intelligibility and quality. Furthermore, we combine the fragmented benefits of time-domain and TF speech representations by introducing two new cross-domain SE frameworks. A quantitative comparative analysis against recent model-based and deep learning SE approaches is performed to illustrate the merit of the proposed frameworks.