 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSABER-6D: Shape Representation Based Implicit Object Pose Estimation
Aug 11, 2024In this paper, we propose a novel encoder-decoder architecture, named SABER, to learn the 6D pose of the object in the embedding space by learning shape representation at a given pose. This model enables us to learn pose by performing shape representation at a target pose from RGB image input. We perform shape representation as an auxiliary task which helps us in learning rotations space for an object based on 2D images. An image encoder predicts the rotation in the embedding space and the DeepSDF based decoder learns to represent the object's shape at the given pose. As our approach is shape based, the pipeline is suitable for any type of object irrespective of the symmetry. Moreover, we need only a CAD model of the objects to train SABER. Our pipeline is synthetic data based and can also handle symmetric objects without symmetry labels and, thus, no additional labeled training data is needed. The experimental evaluation shows that our method achieves close to benchmark results for both symmetric objects and asymmetric objects on Occlusion-LineMOD, and T-LESS datasets.
NIFF: Alleviating Forgetting in Generalized Few-Shot Object Detection via Neural Instance Feature Forging
Mar 09, 2023Privacy and memory are two recurring themes in a broad conversation about the societal impact of AI. These concerns arise from the need for huge amounts of data to train deep neural networks. A promise of Generalized Few-shot Object Detection (G-FSOD), a learning paradigm in AI, is to alleviate the need for collecting abundant training samples of novel classes we wish to detect by leveraging prior knowledge from old classes (i.e., base classes). G-FSOD strives to learn these novel classes while alleviating catastrophic forgetting of the base classes. However, existing approaches assume that the base images are accessible, an assumption that does not hold when sharing and storing data is problematic. In this work, we propose the first data-free knowledge distillation (DFKD) approach for G-FSOD that leverages the statistics of the region of interest (RoI) features from the base model to forge instance-level features without accessing the base images. Our contribution is three-fold: (1) we design a standalone lightweight generator with (2) class-wise heads (3) to generate and replay diverse instance-level base features to the RoI head while finetuning on the novel data. This stands in contrast to standard DFKD approaches in image classification, which invert the entire network to generate base images. Moreover, we make careful design choices in the novel finetuning pipeline to regularize the model. We show that our approach can dramatically reduce the base memory requirements, all while setting a new standard for G-FSOD on the challenging MS-COCO and PASCAL-VOC benchmarks.
Towards Discriminative and Transferable One-Stage Few-Shot Object Detectors
Oct 11, 2022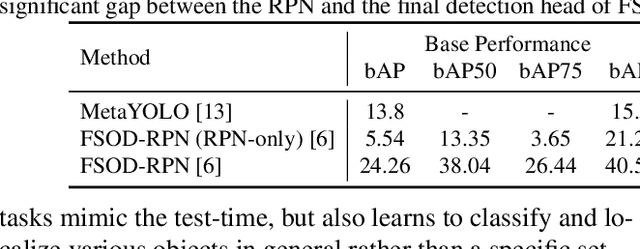
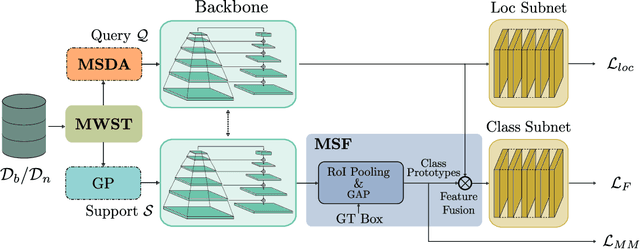
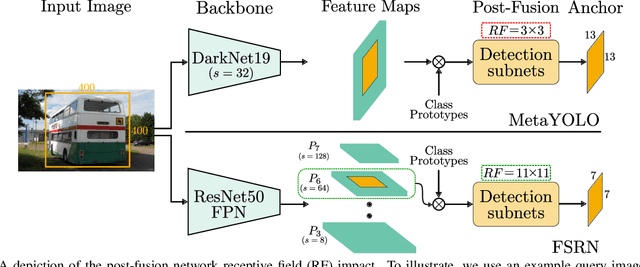
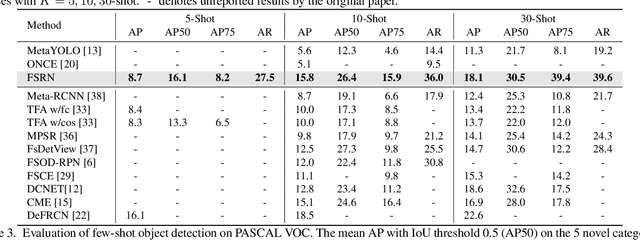
Recent object detection models require large amounts of annotated data for training a new classes of objects. Few-shot object detection (FSOD) aims to address this problem by learning novel classes given only a few samples. While competitive results have been achieved using two-stage FSOD detectors, typically one-stage FSODs underperform compared to them. We make the observation that the large gap in performance between two-stage and one-stage FSODs are mainly due to their weak discriminability, which is explained by a small post-fusion receptive field and a small number of foreground samples in the loss function. To address these limitations, we propose the Few-shot RetinaNet (FSRN) that consists of: a multi-way support training strategy to augment the number of foreground samples for dense meta-detectors, an early multi-level feature fusion providing a wide receptive field that covers the whole anchor area and two augmentation techniques on query and source images to enhance transferability. Extensive experiments show that the proposed approach addresses the limitations and boosts both discriminability and transferability. FSRN is almost two times faster than two-stage FSODs while remaining competitive in accuracy, and it outperforms the state-of-the-art of one-stage meta-detectors and also some two-stage FSODs on the MS-COCO and PASCAL VOC benchmarks.
CFA: Constraint-based Finetuning Approach for Generalized Few-Shot Object Detection
Apr 11, 2022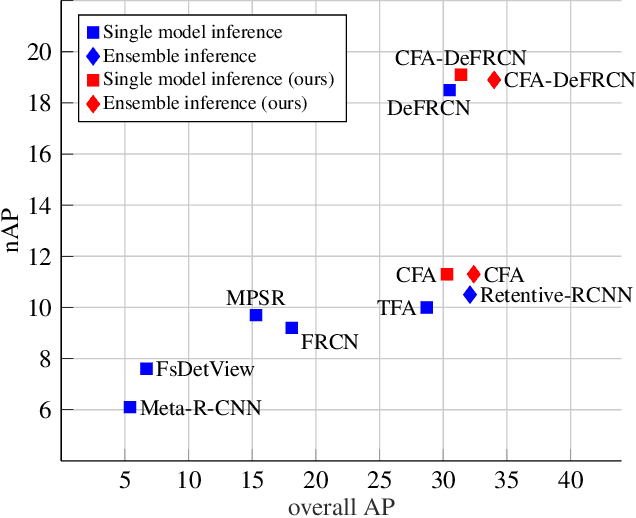
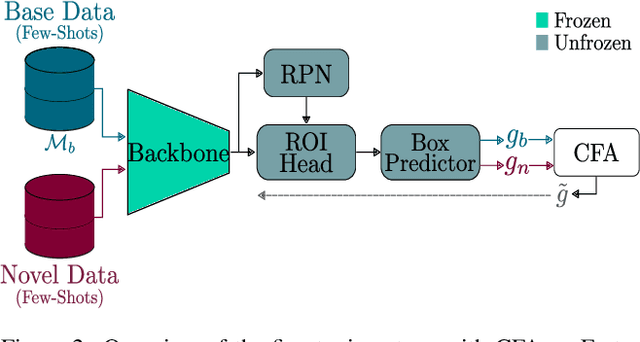
Few-shot object detection (FSOD) seeks to detect novel categories with limited data by leveraging prior knowledge from abundant base data. Generalized few-shot object detection (G-FSOD) aims to tackle FSOD without forgetting previously seen base classes and, thus, accounts for a more realistic scenario, where both classes are encountered during test time. While current FSOD methods suffer from catastrophic forgetting, G-FSOD addresses this limitation yet exhibits a performance drop on novel tasks compared to the state-of-the-art FSOD. In this work, we propose a constraint-based finetuning approach (CFA) to alleviate catastrophic forgetting, while achieving competitive results on the novel task without increasing the model capacity. CFA adapts a continual learning method, namely Average Gradient Episodic Memory (A-GEM) to G-FSOD. Specifically, more constraints on the gradient search strategy are imposed from which a new gradient update rule is derived, allowing for better knowledge exchange between base and novel classes. To evaluate our method, we conduct extensive experiments on MS-COCO and PASCAL-VOC datasets. Our method outperforms current FSOD and G-FSOD approaches on the novel task with minor degeneration on the base task. Moreover, CFA is orthogonal to FSOD approaches and operates as a plug-and-play module without increasing the model capacity or inference time.
Few-Shot Object Detection in Unseen Domains
Apr 11, 2022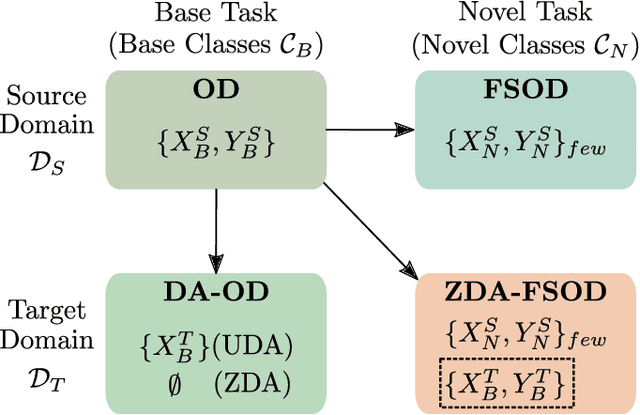
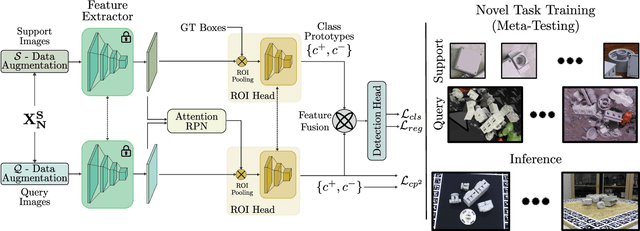

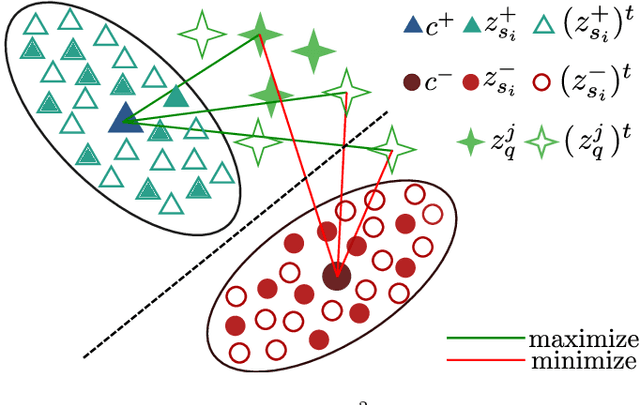
Few-shot object detection (FSOD) has thrived in recent years to learn novel object classes with limited data by transfering knowledge gained on abundant base classes. FSOD approaches commonly assume that both the scarcely provided examples of novel classes and test-time data belong to the same domain. However, this assumption does not hold in various industrial and robotics applications (e.g., object grasping and manipulation), where a model can learn novel classes from a source domain while inferring on classes from a different target domain. In this work, we address the task of zero-shot domain adaptation, also known as domain generalization, for FSOD. Specifically, we assume that neither images nor labels of the novel classes in the target domain are available during training. Our approach for solving the domain gap is two-fold. First, we leverage a meta-training paradigm, where we learn domain-invariant features on the base classes. Second, we propose various data augmentations techniques on the few shots of novel classes to account for all possible domain-specific information. To further constraint the network into encoding domain-agnostic class-specific representations only, a contrastive loss is proposed to maximize the mutual information between foreground proposals and class prototypes, and to reduce the network's bias to the background information. Our experiments on the T-LESS dataset show that the proposed approach succeeds in alleviating the domain gap considerably without utilizing labels or images of novel categories from the target domain.