 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestereo: Diffusion stereo video generation and restoration
Jun 06, 2025Stereo video generation has been gaining increasing attention with recent advancements in video diffusion models. However, most existing methods focus on generating 3D stereoscopic videos from monocular 2D videos. These approaches typically assume that the input monocular video is of high quality, making the task primarily about inpainting occluded regions in the warped video while preserving disoccluded areas. In this paper, we introduce a new pipeline that not only generates stereo videos but also enhances both left-view and right-view videos consistently with a single model. Our approach achieves this by fine-tuning the model on degraded data for restoration, as well as conditioning the model on warped masks for consistent stereo generation. As a result, our method can be fine-tuned on a relatively small synthetic stereo video datasets and applied to low-quality real-world videos, performing both stereo video generation and restoration. Experiments demonstrate that our method outperforms existing approaches both qualitatively and quantitatively in stereo video generation from low-resolution inputs.
Edge-preserving noise for diffusion models
Oct 02, 2024



Classical generative diffusion models learn an isotropic Gaussian denoising process, treating all spatial regions uniformly, thus neglecting potentially valuable structural information in the data. Inspired by the long-established work on anisotropic diffusion in image processing, we present a novel edge-preserving diffusion model that is a generalization of denoising diffusion probablistic models (DDPM). In particular, we introduce an edge-aware noise scheduler that varies between edge-preserving and isotropic Gaussian noise. We show that our model's generative process converges faster to results that more closely match the target distribution. We demonstrate its capability to better learn the low-to-mid frequencies within the dataset, which plays a crucial role in representing shapes and structural information. Our edge-preserving diffusion process consistently outperforms state-of-the-art baselines in unconditional image generation. It is also more robust for generative tasks guided by a shape-based prior, such as stroke-to-image generation. We present qualitative and quantitative results showing consistent improvements (FID score) of up to 30% for both tasks.
SABER-6D: Shape Representation Based Implicit Object Pose Estimation
Aug 11, 2024In this paper, we propose a novel encoder-decoder architecture, named SABER, to learn the 6D pose of the object in the embedding space by learning shape representation at a given pose. This model enables us to learn pose by performing shape representation at a target pose from RGB image input. We perform shape representation as an auxiliary task which helps us in learning rotations space for an object based on 2D images. An image encoder predicts the rotation in the embedding space and the DeepSDF based decoder learns to represent the object's shape at the given pose. As our approach is shape based, the pipeline is suitable for any type of object irrespective of the symmetry. Moreover, we need only a CAD model of the objects to train SABER. Our pipeline is synthetic data based and can also handle symmetric objects without symmetry labels and, thus, no additional labeled training data is needed. The experimental evaluation shows that our method achieves close to benchmark results for both symmetric objects and asymmetric objects on Occlusion-LineMOD, and T-LESS datasets.
Multiple importance sampling for stochastic gradient estimation
Jul 22, 2024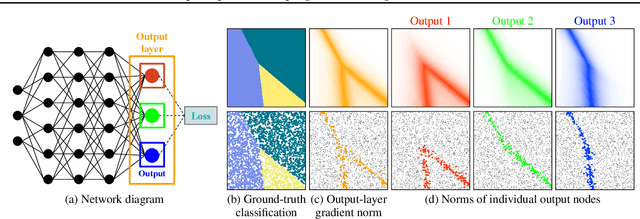
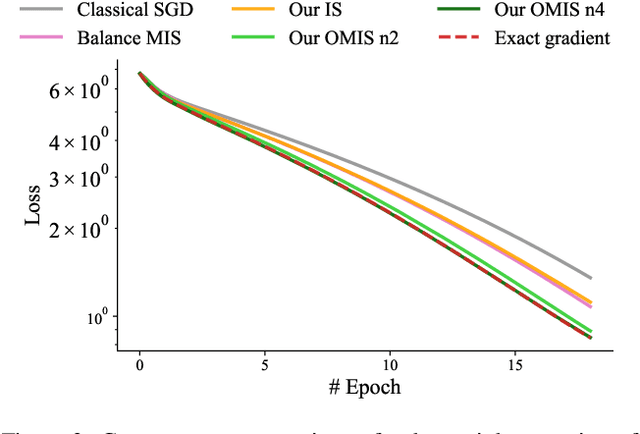
We introduce a theoretical and practical framework for efficient importance sampling of mini-batch samples for gradient estimation from single and multiple probability distributions. To handle noisy gradients, our framework dynamically evolves the importance distribution during training by utilizing a self-adaptive metric. Our framework combines multiple, diverse sampling distributions, each tailored to specific parameter gradients. This approach facilitates the importance sampling of vector-valued gradient estimation. Rather than naively combining multiple distributions, our framework involves optimally weighting data contribution across multiple distributions. This adapted combination of multiple importance yields superior gradient estimates, leading to faster training convergence. We demonstrate the effectiveness of our approach through empirical evaluations across a range of optimization tasks like classification and regression on both image and point cloud datasets.
Blue noise for diffusion models
Feb 07, 2024



Most of the existing diffusion models use Gaussian noise for training and sampling across all time steps, which may not optimally account for the frequency contents reconstructed by the denoising network. Despite the diverse applications of correlated noise in computer graphics, its potential for improving the training process has been underexplored. In this paper, we introduce a novel and general class of diffusion models taking correlated noise within and across images into account. More specifically, we propose a time-varying noise model to incorporate correlated noise into the training process, as well as a method for fast generation of correlated noise mask. Our model is built upon deterministic diffusion models and utilizes blue noise to help improve the generation quality compared to using Gaussian white (random) noise only. Further, our framework allows introducing correlation across images within a single mini-batch to improve gradient flow. We perform both qualitative and quantitative evaluations on a variety of datasets using our method, achieving improvements on different tasks over existing deterministic diffusion models in terms of FID metric.
Efficient Gradient Estimation via Adaptive Sampling and Importance Sampling
Nov 27, 2023
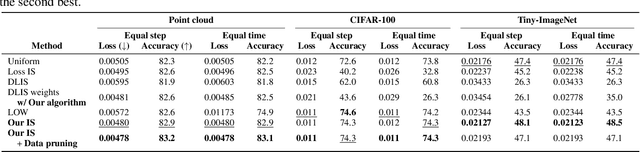
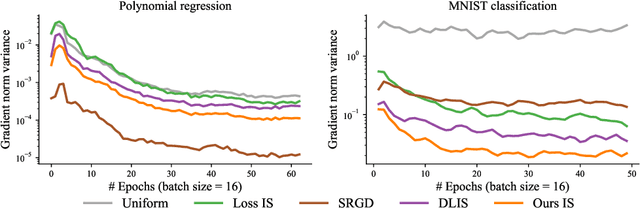

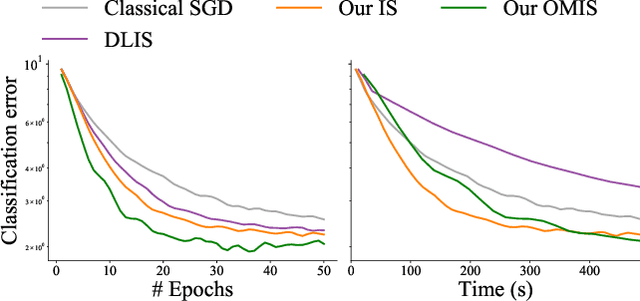
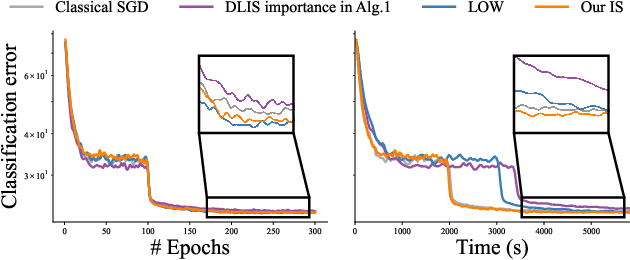
Machine learning problems rely heavily on stochastic gradient descent (SGD) for optimization. The effectiveness of SGD is contingent upon accurately estimating gradients from a mini-batch of data samples. Instead of the commonly used uniform sampling, adaptive or importance sampling reduces noise in gradient estimation by forming mini-batches that prioritize crucial data points. Previous research has suggested that data points should be selected with probabilities proportional to their gradient norm. Nevertheless, existing algorithms have struggled to efficiently integrate importance sampling into machine learning frameworks. In this work, we make two contributions. First, we present an algorithm that can incorporate existing importance functions into our framework. Second, we propose a simplified importance function that relies solely on the loss gradient of the output layer. By leveraging our proposed gradient estimation techniques, we observe improved convergence in classification and regression tasks with minimal computational overhead. We validate the effectiveness of our adaptive and importance-sampling approach on image and point-cloud datasets.
Joint Sampling and Optimisation for Inverse Rendering
Sep 27, 2023
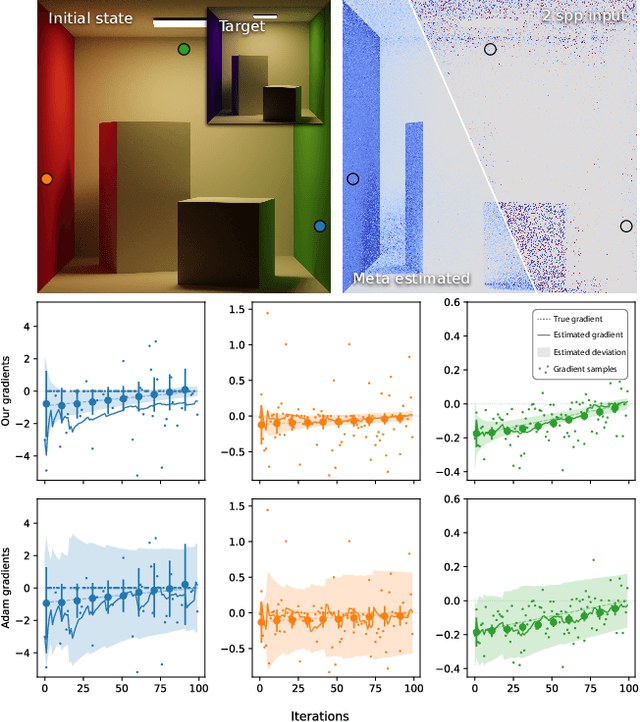
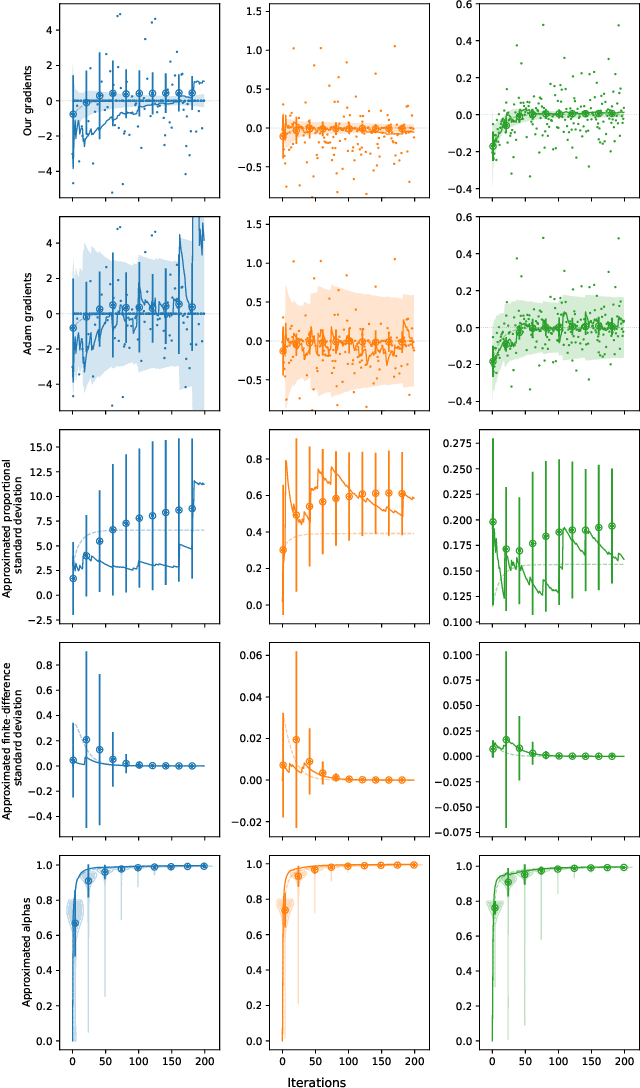

When dealing with difficult inverse problems such as inverse rendering, using Monte Carlo estimated gradients to optimise parameters can slow down convergence due to variance. Averaging many gradient samples in each iteration reduces this variance trivially. However, for problems that require thousands of optimisation iterations, the computational cost of this approach rises quickly. We derive a theoretical framework for interleaving sampling and optimisation. We update and reuse past samples with low-variance finite-difference estimators that describe the change in the estimated gradients between each iteration. By combining proportional and finite-difference samples, we continuously reduce the variance of our novel gradient meta-estimators throughout the optimisation process. We investigate how our estimator interlinks with Adam and derive a stable combination. We implement our method for inverse path tracing and demonstrate how our estimator speeds up convergence on difficult optimisation tasks.
Neural Relightable Participating Media Rendering
Oct 25, 2021
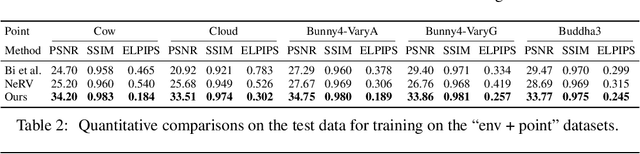
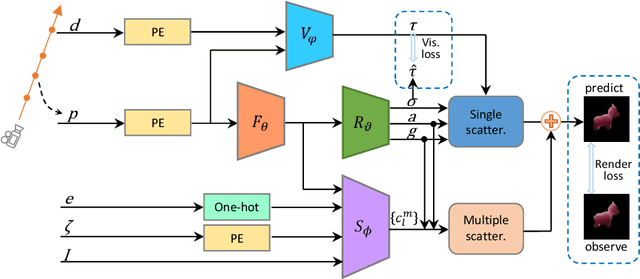

Learning neural radiance fields of a scene has recently allowed realistic novel view synthesis of the scene, but they are limited to synthesize images under the original fixed lighting condition. Therefore, they are not flexible for the eagerly desired tasks like relighting, scene editing and scene composition. To tackle this problem, several recent methods propose to disentangle reflectance and illumination from the radiance field. These methods can cope with solid objects with opaque surfaces but participating media are neglected. Also, they take into account only direct illumination or at most one-bounce indirect illumination, thus suffer from energy loss due to ignoring the high-order indirect illumination. We propose to learn neural representations for participating media with a complete simulation of global illumination. We estimate direct illumination via ray tracing and compute indirect illumination with spherical harmonics. Our approach avoids computing the lengthy indirect bounces and does not suffer from energy loss. Our experiments on multiple scenes show that our approach achieves superior visual quality and numerical performance compared to state-of-the-art methods, and it can generalize to deal with solid objects with opaque surfaces as well.
Ladybird: Quasi-Monte Carlo Sampling for Deep Implicit Field Based 3D Reconstruction with Symmetry
Jul 27, 2020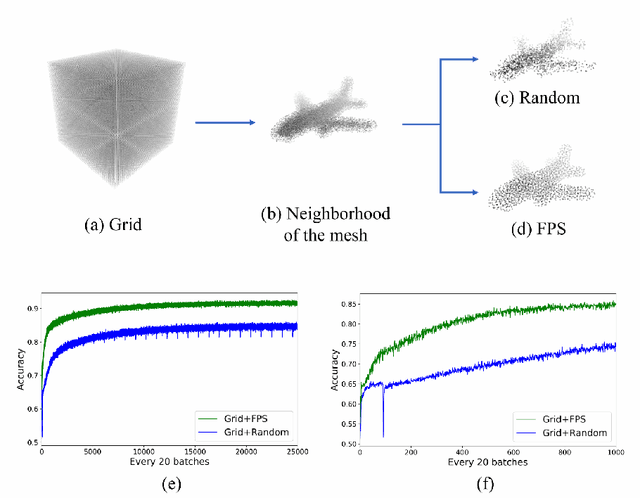
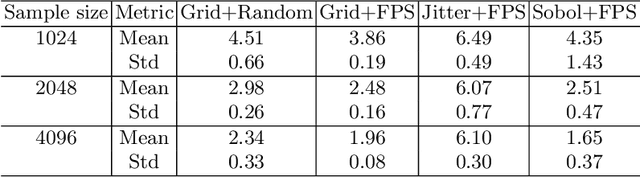
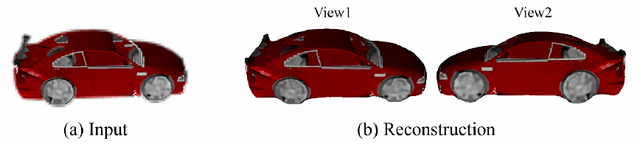

Deep implicit field regression methods are effective for 3D reconstruction from single-view images. However, the impact of different sampling patterns on the reconstruction quality is not well-understood. In this work, we first study the effect of point set discrepancy on the network training. Based on Farthest Point Sampling algorithm, we propose a sampling scheme that theoretically encourages better generalization performance, and results in fast convergence for SGD-based optimization algorithms. Secondly, based on the reflective symmetry of an object, we propose a feature fusion method that alleviates issues due to self-occlusions which makes it difficult to utilize local image features. Our proposed system Ladybird is able to create high quality 3D object reconstructions from a single input image. We evaluate Ladybird on a large scale 3D dataset (ShapeNet) demonstrating highly competitive results in terms of Chamfer distance, Earth Mover's distance and Intersection Over Union (IoU).