 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestereo: Diffusion stereo video generation and restoration
Jun 06, 2025Stereo video generation has been gaining increasing attention with recent advancements in video diffusion models. However, most existing methods focus on generating 3D stereoscopic videos from monocular 2D videos. These approaches typically assume that the input monocular video is of high quality, making the task primarily about inpainting occluded regions in the warped video while preserving disoccluded areas. In this paper, we introduce a new pipeline that not only generates stereo videos but also enhances both left-view and right-view videos consistently with a single model. Our approach achieves this by fine-tuning the model on degraded data for restoration, as well as conditioning the model on warped masks for consistent stereo generation. As a result, our method can be fine-tuned on a relatively small synthetic stereo video datasets and applied to low-quality real-world videos, performing both stereo video generation and restoration. Experiments demonstrate that our method outperforms existing approaches both qualitatively and quantitatively in stereo video generation from low-resolution inputs.
Edge-preserving noise for diffusion models
Oct 02, 2024



Classical generative diffusion models learn an isotropic Gaussian denoising process, treating all spatial regions uniformly, thus neglecting potentially valuable structural information in the data. Inspired by the long-established work on anisotropic diffusion in image processing, we present a novel edge-preserving diffusion model that is a generalization of denoising diffusion probablistic models (DDPM). In particular, we introduce an edge-aware noise scheduler that varies between edge-preserving and isotropic Gaussian noise. We show that our model's generative process converges faster to results that more closely match the target distribution. We demonstrate its capability to better learn the low-to-mid frequencies within the dataset, which plays a crucial role in representing shapes and structural information. Our edge-preserving diffusion process consistently outperforms state-of-the-art baselines in unconditional image generation. It is also more robust for generative tasks guided by a shape-based prior, such as stroke-to-image generation. We present qualitative and quantitative results showing consistent improvements (FID score) of up to 30% for both tasks.
Multiple importance sampling for stochastic gradient estimation
Jul 22, 2024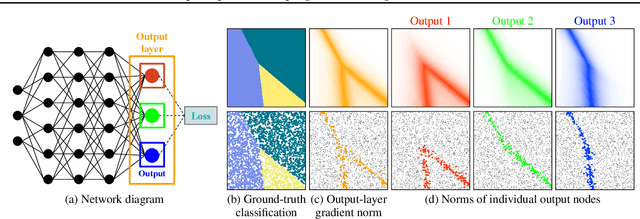
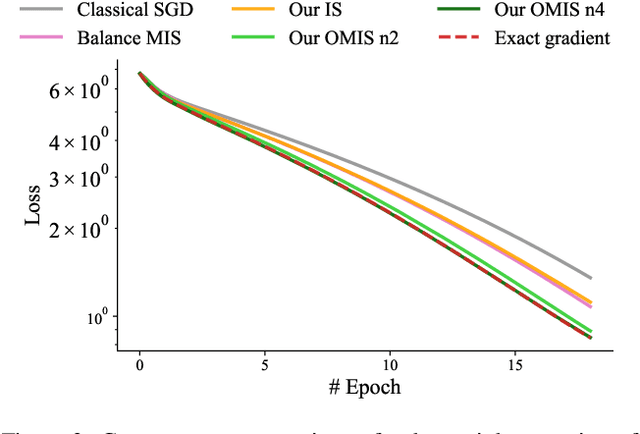
We introduce a theoretical and practical framework for efficient importance sampling of mini-batch samples for gradient estimation from single and multiple probability distributions. To handle noisy gradients, our framework dynamically evolves the importance distribution during training by utilizing a self-adaptive metric. Our framework combines multiple, diverse sampling distributions, each tailored to specific parameter gradients. This approach facilitates the importance sampling of vector-valued gradient estimation. Rather than naively combining multiple distributions, our framework involves optimally weighting data contribution across multiple distributions. This adapted combination of multiple importance yields superior gradient estimates, leading to faster training convergence. We demonstrate the effectiveness of our approach through empirical evaluations across a range of optimization tasks like classification and regression on both image and point cloud datasets.
Blue noise for diffusion models
Feb 07, 2024



Most of the existing diffusion models use Gaussian noise for training and sampling across all time steps, which may not optimally account for the frequency contents reconstructed by the denoising network. Despite the diverse applications of correlated noise in computer graphics, its potential for improving the training process has been underexplored. In this paper, we introduce a novel and general class of diffusion models taking correlated noise within and across images into account. More specifically, we propose a time-varying noise model to incorporate correlated noise into the training process, as well as a method for fast generation of correlated noise mask. Our model is built upon deterministic diffusion models and utilizes blue noise to help improve the generation quality compared to using Gaussian white (random) noise only. Further, our framework allows introducing correlation across images within a single mini-batch to improve gradient flow. We perform both qualitative and quantitative evaluations on a variety of datasets using our method, achieving improvements on different tasks over existing deterministic diffusion models in terms of FID metric.
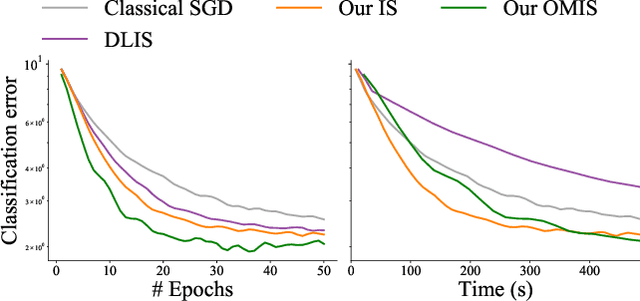
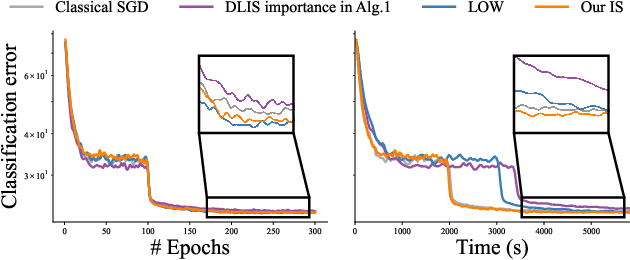
Efficient Gradient Estimation via Adaptive Sampling and Importance Sampling
Nov 27, 2023
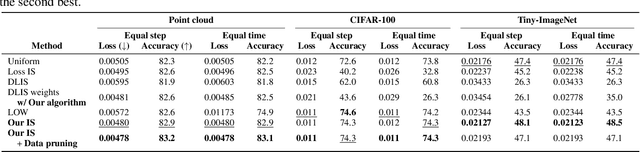
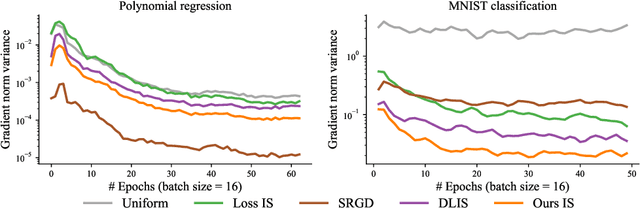

Machine learning problems rely heavily on stochastic gradient descent (SGD) for optimization. The effectiveness of SGD is contingent upon accurately estimating gradients from a mini-batch of data samples. Instead of the commonly used uniform sampling, adaptive or importance sampling reduces noise in gradient estimation by forming mini-batches that prioritize crucial data points. Previous research has suggested that data points should be selected with probabilities proportional to their gradient norm. Nevertheless, existing algorithms have struggled to efficiently integrate importance sampling into machine learning frameworks. In this work, we make two contributions. First, we present an algorithm that can incorporate existing importance functions into our framework. Second, we propose a simplified importance function that relies solely on the loss gradient of the output layer. By leveraging our proposed gradient estimation techniques, we observe improved convergence in classification and regression tasks with minimal computational overhead. We validate the effectiveness of our adaptive and importance-sampling approach on image and point-cloud datasets.
Continual Learning of a Mixed Sequence of Similar and Dissimilar Tasks
Dec 18, 2021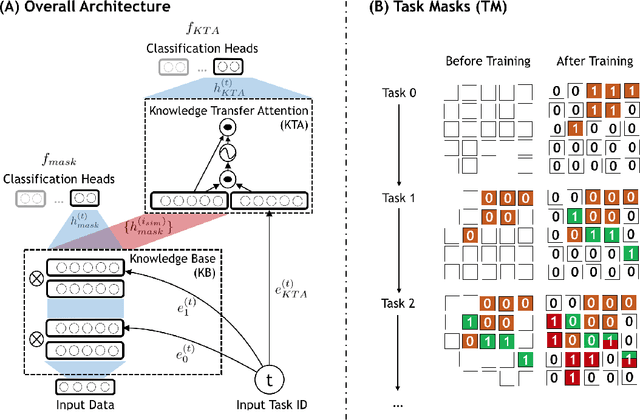
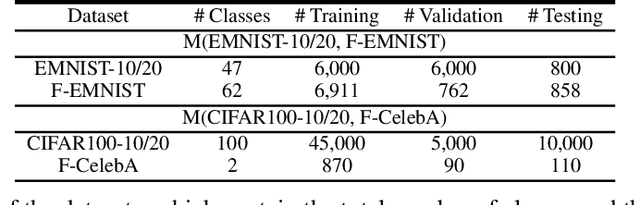
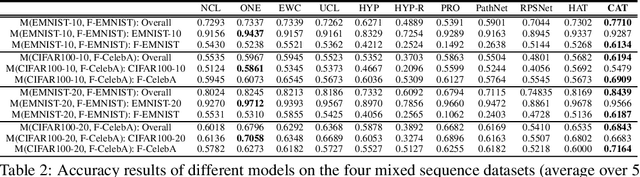
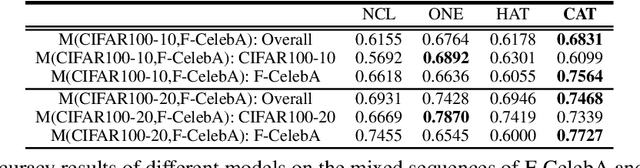
Existing research on continual learning of a sequence of tasks focused on dealing with catastrophic forgetting, where the tasks are assumed to be dissimilar and have little shared knowledge. Some work has also been done to transfer previously learned knowledge to the new task when the tasks are similar and have shared knowledge. To the best of our knowledge, no technique has been proposed to learn a sequence of mixed similar and dissimilar tasks that can deal with forgetting and also transfer knowledge forward and backward. This paper proposes such a technique to learn both types of tasks in the same network. For dissimilar tasks, the algorithm focuses on dealing with forgetting, and for similar tasks, the algorithm focuses on selectively transferring the knowledge learned from some similar previous tasks to improve the new task learning. Additionally, the algorithm automatically detects whether a new task is similar to any previous tasks. Empirical evaluation using sequences of mixed tasks demonstrates the effectiveness of the proposed model.