 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillOrchestra: Learning to Route Agents via Skill Transfer
Feb 23, 2026Compound AI systems promise capabilities beyond those of individual models, yet their success depends critically on effective orchestration. Existing routing approaches face two limitations: (1) input-level routers make coarse query-level decisions that ignore evolving task requirements; (2) RL-trained orchestrators are expensive to adapt and often suffer from routing collapse, repeatedly invoking one strong but costly option in multi-turn scenarios. We introduce SkillOrchestra, a framework for skill-aware orchestration. Instead of directly learning a routing policy end-to-end, SkillOrchestra learns fine-grained skills from execution experience and models agent-specific competence and cost under those skills. At deployment, the orchestrator infers the skill demands of the current interaction and selects agents that best satisfy them under an explicit performance-cost trade-off. Extensive experiments across ten benchmarks demonstrate that SkillOrchestra outperforms SoTA RL-based orchestrators by up to 22.5% with 700x and 300x learning cost reduction compared to Router-R1 and ToolOrchestra, respectively. These results show that explicit skill modeling enables scalable, interpretable, and sample-efficient orchestration, offering a principled alternative to data-intensive RL-based approaches. The code is available at: https://github.com/jiayuww/SkillOrchestra.
MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems
Feb 03, 2026Multi-Agent Systems (MAS) built on Large Language Models (LLMs) often exhibit high variance in their reasoning trajectories. Process verification, which evaluates intermediate steps in trajectories, has shown promise in general reasoning settings, and has been suggested as a potential tool for guiding coordination of MAS; however, its actual effectiveness in MAS remains unclear. To fill this gap, we present MAS-ProVe, a systematic empirical study of process verification for multi-agent systems (MAS). Our study spans three verification paradigms (LLM-as-a-Judge, reward models, and process reward models), evaluated across two levels of verification granularity (agent-level and iteration-level). We further examine five representative verifiers and four context management strategies, and conduct experiments over six diverse MAS frameworks on multiple reasoning benchmarks. We find that process-level verification does not consistently improve performance and frequently exhibits high variance, highlighting the difficulty of reliably evaluating partial multi-agent trajectories. Among the methods studied, LLM-as-a-Judge generally outperforms reward-based approaches, with trained judges surpassing general-purpose LLMs. We further observe a small performance gap between LLMs acting as judges and as single agents, and identify a context-length-performance trade-off in verification. Overall, our results suggest that effective and robust process verification for MAS remains an open challenge, requiring further advances beyond current paradigms. Code is available at https://github.com/Wang-ML-Lab/MAS-ProVe.
MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks
Jan 21, 2026While multi-agent systems (MAS) promise elevated intelligence through coordination of agents, current approaches to automatic MAS design under-deliver. Such shortcomings stem from two key factors: (1) methodological complexity - agent orchestration is performed using sequential, code-level execution that limits global system-level holistic reasoning and scales poorly with agent complexity - and (2) efficacy uncertainty - MAS are deployed without understanding if there are tangible benefits compared to single-agent systems (SAS). We propose MAS-Orchestra, a training-time framework that formulates MAS orchestration as a function-calling reinforcement learning problem with holistic orchestration, generating an entire MAS at once. In MAS-Orchestra, complex, goal-oriented sub-agents are abstracted as callable functions, enabling global reasoning over system structure while hiding internal execution details. To rigorously study when and why MAS are beneficial, we introduce MASBENCH, a controlled benchmark that characterizes tasks along five axes: Depth, Horizon, Breadth, Parallel, and Robustness. Our analysis reveals that MAS gains depend critically on task structure, verification protocols, and the capabilities of both orchestrator and sub-agents, rather than holding universally. Guided by these insights, MAS-Orchestra achieves consistent improvements on public benchmarks including mathematical reasoning, multi-hop QA, and search-based QA. Together, MAS-Orchestra and MASBENCH enable better training and understanding of MAS in the pursuit of multi-agent intelligence.
LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Oct 16, 2025Deep research -- producing comprehensive, citation-grounded reports by searching and synthesizing information from hundreds of live web sources -- marks an important frontier for agentic systems. To rigorously evaluate this ability, four principles are essential: tasks should be (1) user-centric, reflecting realistic information needs, (2) dynamic, requiring up-to-date information beyond parametric knowledge, (3) unambiguous, ensuring consistent interpretation across users, and (4) multi-faceted and search-intensive, requiring search over numerous web sources and in-depth analysis. Existing benchmarks fall short of these principles, often focusing on narrow domains or posing ambiguous questions that hinder fair comparison. Guided by these principles, we introduce LiveResearchBench, a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, each requiring extensive, dynamic, real-time web search and synthesis. Built with over 1,500 hours of human labor, LiveResearchBench provides a rigorous basis for systematic evaluation. To evaluate citation-grounded long-form reports, we introduce DeepEval, a comprehensive suite covering both content- and report-level quality, including coverage, presentation, citation accuracy and association, consistency and depth of analysis. DeepEval integrates four complementary evaluation protocols, each designed to ensure stable assessment and high agreement with human judgments. Using LiveResearchBench and DeepEval, we conduct a comprehensive evaluation of 17 frontier deep research systems, including single-agent web search, single-agent deep research, and multi-agent systems. Our analysis reveals current strengths, recurring failure modes, and key system components needed to advance reliable, insightful deep research.
Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning
Jun 05, 2025Reinforcement learning (RL) has become the dominant paradigm for endowing language models with advanced reasoning capabilities. Despite the substantial empirical gains demonstrated by RL-based training methods like GRPO, a granular understanding of their advantages is still lacking. To address this gap, we introduce a fine-grained analytic framework to dissect the impact of RL on reasoning. Our framework specifically investigates key elements that have been hypothesized to benefit from RL training: (1) plan-following and execution, (2) problem decomposition, and (3) improved reasoning and knowledge utilization. Using this framework, we gain insights beyond mere accuracy. For instance, providing models with explicit step-by-step plans surprisingly degrades performance on the most challenging benchmarks, yet RL-tuned models exhibit greater robustness, experiencing markedly smaller performance drops than their base counterparts. This suggests that RL may not primarily enhance the execution of external plans but rather empower models to formulate and follow internal strategies better suited to their reasoning processes. Conversely, we observe that RL enhances the model's capacity to integrate provided knowledge into its reasoning process, leading to performance improvements across diverse tasks. We also study difficulty, showing improved training by developing new ways to exploit hard problems. Our findings lay a foundation for more principled training and evaluation of reasoning models.
MAS-ZERO: Designing Multi-Agent Systems with Zero Supervision
May 26, 2025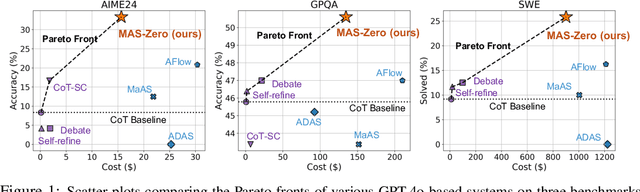

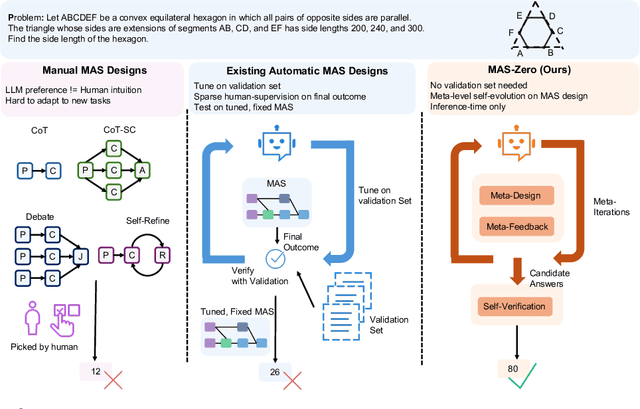

Multi-agent systems (MAS) leveraging the impressive capabilities of Large Language Models (LLMs) hold significant potential for tackling complex tasks. However, most current MAS depend on manually designed agent roles and communication protocols. These manual designs often fail to align with the underlying LLMs' strengths and struggle to adapt to novel tasks. Recent automatic MAS approaches attempt to mitigate these limitations but typically necessitate a validation set for tuning and yield static MAS designs lacking adaptability during inference. We introduce MAS-ZERO, the first self-evolved, inference-time framework for automatic MAS design. MAS-ZERO employs meta-level design to iteratively generate, evaluate, and refine MAS configurations tailored to each problem instance, without requiring a validation set. Critically, it enables dynamic agent composition and problem decomposition through meta-feedback on solvability and completeness. Experiments across math, graduate-level QA, and software engineering benchmarks, using both closed-source and open-source LLM backbones of varying sizes, demonstrate that MAS-ZERO outperforms both manual and automatic MAS baselines, achieving a 7.44% average accuracy improvement over the next strongest baseline while maintaining cost-efficiency. These findings underscore the promise of meta-level self-evolved design for creating effective and adaptive MAS.
Meta-Design Matters: A Self-Design Multi-Agent System
May 21, 2025Multi-agent systems (MAS) leveraging the impressive capabilities of Large Language Models (LLMs) hold significant potential for tackling complex tasks. However, most current MAS depend on manually designed agent roles and communication protocols. These manual designs often fail to align with the underlying LLMs' strengths and struggle to adapt to novel tasks. Recent automatic MAS approaches attempt to mitigate these limitations but typically necessitate a validation-set for tuning and yield static MAS designs lacking adaptability during inference. We introduce SELF-MAS, the first self-supervised, inference-time only framework for automatic MAS design. SELF-MAS employs meta-level design to iteratively generate, evaluate, and refine MAS configurations tailored to each problem instance, without requiring a validation set. Critically, it enables dynamic agent composition and problem decomposition through meta-feedback on solvability and completeness. Experiments across math, graduate-level QA, and software engineering benchmarks, using both closed-source and open-source LLM back-bones of varying sizes, demonstrate that SELF-MAS outperforms both manual and automatic MAS baselines, achieving a 7.44% average accuracy improvement over the next strongest baseline while maintaining cost-efficiency. These findings underscore the promise of meta-level self-supervised design for creating effective and adaptive MAS.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025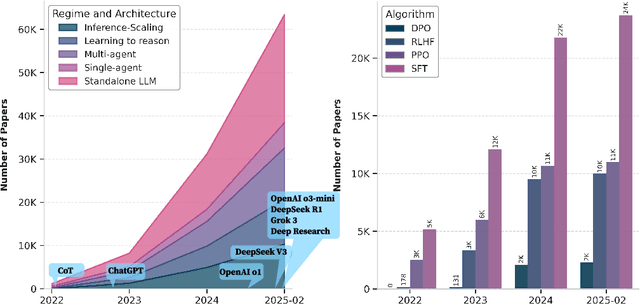

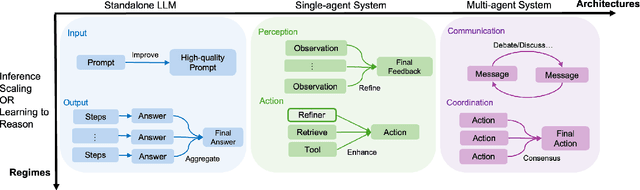

Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
Adaptation of Large Language Models
Apr 04, 2025This tutorial on adaptation of LLMs is designed to address the growing demand for models that go beyond the static capabilities of generic LLMs by providing an overview of dynamic, domain-specific, and task-adaptive LLM adaptation techniques. While general LLMs have demonstrated strong generalization across a variety of tasks, they often struggle to perform well in specialized domains such as finance, healthcare, and code generation for underrepresented languages. Additionally, their static nature limits their ability to evolve with the changing world, and they are often extremely large in size, making them impractical and costly to deploy at scale. As a result, the adaptation of LLMs has drawn much attention since the birth of LLMs and is of core importance, both for industry, which focuses on serving its targeted users, and academia, which can greatly benefit from small but powerful LLMs. To address this gap, this tutorial aims to provide an overview of the LLM adaptation techniques. We start with an introduction to LLM adaptation, from both the data perspective and the model perspective. We then emphasize how the evaluation metrics and benchmarks are different from other techniques. After establishing the problems, we explore various adaptation techniques. We categorize adaptation techniques into two main families. The first is parametric knowledge adaptation, which focuses on updating the parametric knowledge within LLMs. Additionally, we will discuss real-time adaptation techniques, including model editing, which allows LLMs to be updated dynamically in production environments. The second kind of adaptation is semi-parametric knowledge adaptation, where the goal is to update LLM parameters to better leverage external knowledge or tools through techniques like retrieval-augmented generation (RAG) and agent-based systems.
Demystifying Domain-adaptive Post-training for Financial LLMs
Jan 09, 2025



Domain-adaptive post-training of large language models (LLMs) has emerged as a promising approach for specialized domains such as medicine and finance. However, significant challenges remain in identifying optimal adaptation criteria and training strategies across varying data and model configurations. To address these challenges, we introduce FINDAP, a systematic and fine-grained investigation into domain-adaptive post-training of LLMs for the finance domain. Our approach begins by identifying the core capabilities required for the target domain and designing a comprehensive evaluation suite aligned with these needs. We then analyze the effectiveness of key post-training stages, including continual pretraining, instruction tuning, and preference alignment. Building on these insights, we propose an effective training recipe centered on a novel preference data distillation method, which leverages process signals from a generative reward model. The resulting model, Llama-Fin, achieves state-of-the-art performance across a wide range of financial tasks. Our analysis also highlights how each post-training stage contributes to distinct capabilities, uncovering specific challenges and effective solutions, providing valuable insights for domain adaptation of LLMs. Project page: https://github.com/SalesforceAIResearch/FinDap