 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnaCP: Toward Upper-Bound Continual Learning via Analytic Contrastive Projection
Nov 17, 2025



This paper studies the problem of class-incremental learning (CIL), a core setting within continual learning where a model learns a sequence of tasks, each containing a distinct set of classes. Traditional CIL methods, which do not leverage pre-trained models (PTMs), suffer from catastrophic forgetting (CF) due to the need to incrementally learn both feature representations and the classifier. The integration of PTMs into CIL has recently led to efficient approaches that treat the PTM as a fixed feature extractor combined with analytic classifiers, achieving state-of-the-art performance. However, they still face a major limitation: the inability to continually adapt feature representations to best suit the CIL tasks, leading to suboptimal performance. To address this, we propose AnaCP (Analytic Contrastive Projection), a novel method that preserves the efficiency of analytic classifiers while enabling incremental feature adaptation without gradient-based training, thereby eliminating the CF caused by gradient updates. Our experiments show that AnaCP not only outperforms existing baselines but also achieves the accuracy level of joint training, which is regarded as the upper bound of CIL.
Achieving Upper Bound Accuracy of Joint Training in Continual Learning
Feb 17, 2025Continual learning has been an active research area in machine learning, focusing on incrementally learning a sequence of tasks. A key challenge is catastrophic forgetting (CF), and most research efforts have been directed toward mitigating this issue. However, a significant gap remains between the accuracy achieved by state-of-the-art continual learning algorithms and the ideal or upper-bound accuracy achieved by training all tasks together jointly. This gap has hindered or even prevented the adoption of continual learning in applications, as accuracy is often of paramount importance. Recently, another challenge, termed inter-task class separation (ICS), was also identified, which spurred a theoretical study into principled approaches for solving continual learning. Further research has shown that by leveraging the theory and the power of large foundation models, it is now possible to achieve upper-bound accuracy, which has been empirically validated using both text and image classification datasets. Continual learning is now ready for real-life applications. This paper surveys the main research leading to this achievement, justifies the approach both intuitively and from neuroscience research, and discusses insights gained.
In-context Continual Learning Assisted by an External Continual Learner
Dec 20, 2024Existing continual learning (CL) methods mainly rely on fine-tuning or adapting large language models (LLMs). They still suffer from catastrophic forgetting (CF). Little work has been done to exploit in-context learning (ICL) to leverage the extensive knowledge within LLMs for CL without updating any parameters. However, incrementally learning each new task in ICL necessitates adding training examples from each class of the task to the prompt, which hampers scalability as the prompt length increases. This issue not only leads to excessively long prompts that exceed the input token limit of the underlying LLM but also degrades the model's performance due to the overextended context. To address this, we introduce InCA, a novel approach that integrates an external continual learner (ECL) with ICL to enable scalable CL without CF. The ECL is built incrementally to pre-select a small subset of likely classes for each test instance. By restricting the ICL prompt to only these selected classes, InCA prevents prompt lengths from becoming excessively long, while maintaining high performance. Experimental results demonstrate that InCA significantly outperforms existing CL baselines, achieving substantial performance gains.
Continual Learning Using a Kernel-Based Method Over Foundation Models
Dec 20, 2024Continual learning (CL) learns a sequence of tasks incrementally. This paper studies the challenging CL setting of class-incremental learning (CIL). CIL has two key challenges: catastrophic forgetting (CF) and inter-task class separation (ICS). Despite numerous proposed methods, these issues remain persistent obstacles. This paper proposes a novel CIL method, called Kernel Linear Discriminant Analysis (KLDA), that can effectively avoid CF and ICS problems. It leverages only the powerful features learned in a foundation model (FM). However, directly using these features proves suboptimal. To address this, KLDA incorporates the Radial Basis Function (RBF) kernel and its Random Fourier Features (RFF) to enhance the feature representations from the FM, leading to improved performance. When a new task arrives, KLDA computes only the mean for each class in the task and updates a shared covariance matrix for all learned classes based on the kernelized features. Classification is performed using Linear Discriminant Analysis. Our empirical evaluation using text and image classification datasets demonstrates that KLDA significantly outperforms baselines. Remarkably, without relying on replay data, KLDA achieves accuracy comparable to joint training of all classes, which is considered the upper bound for CIL performance. The KLDA code is available at https://github.com/salehmomeni/klda.
Free-text Keystroke Authentication using Transformers: A Comparative Study of Architectures and Loss Functions
Oct 18, 2023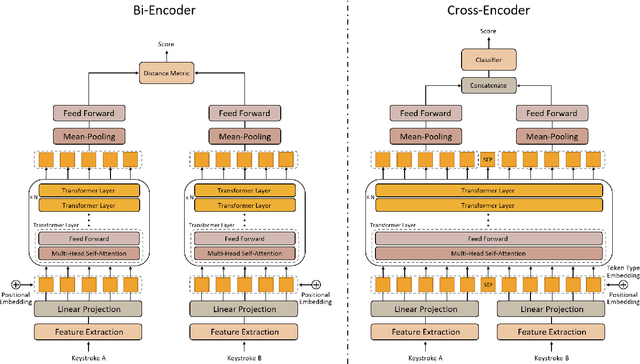
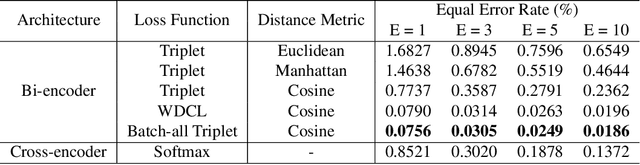
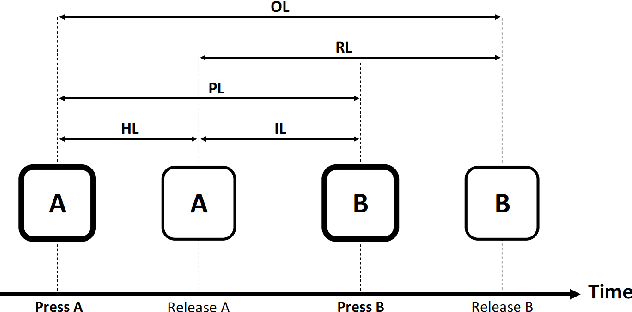

Keystroke biometrics is a promising approach for user identification and verification, leveraging the unique patterns in individuals' typing behavior. In this paper, we propose a Transformer-based network that employs self-attention to extract informative features from keystroke sequences, surpassing the performance of traditional Recurrent Neural Networks. We explore two distinct architectures, namely bi-encoder and cross-encoder, and compare their effectiveness in keystroke authentication. Furthermore, we investigate different loss functions, including triplet, batch-all triplet, and WDCL loss, along with various distance metrics such as Euclidean, Manhattan, and cosine distances. These experiments allow us to optimize the training process and enhance the performance of our model. To evaluate our proposed model, we employ the Aalto desktop keystroke dataset. The results demonstrate that the bi-encoder architecture with batch-all triplet loss and cosine distance achieves the best performance, yielding an exceptional Equal Error Rate of 0.0186%. Furthermore, alternative algorithms for calculating similarity scores are explored to enhance accuracy. Notably, the utilization of a one-class Support Vector Machine reduces the Equal Error Rate to an impressive 0.0163%. The outcomes of this study indicate that our model surpasses the previous state-of-the-art in free-text keystroke authentication. These findings contribute to advancing the field of keystroke authentication and offer practical implications for secure user verification systems.
A Transformer-based Approach for Arabic Offline Handwritten Text Recognition
Jul 27, 2023



Handwriting recognition is a challenging and critical problem in the fields of pattern recognition and machine learning, with applications spanning a wide range of domains. In this paper, we focus on the specific issue of recognizing offline Arabic handwritten text. Existing approaches typically utilize a combination of convolutional neural networks for image feature extraction and recurrent neural networks for temporal modeling, with connectionist temporal classification used for text generation. However, these methods suffer from a lack of parallelization due to the sequential nature of recurrent neural networks. Furthermore, these models cannot account for linguistic rules, necessitating the use of an external language model in the post-processing stage to boost accuracy. To overcome these issues, we introduce two alternative architectures, namely the Transformer Transducer and the standard sequence-to-sequence Transformer, and compare their performance in terms of accuracy and speed. Our approach can model language dependencies and relies only on the attention mechanism, thereby making it more parallelizable and less complex. We employ pre-trained Transformers for both image understanding and language modeling. Our evaluation on the Arabic KHATT dataset demonstrates that our proposed method outperforms the current state-of-the-art approaches for recognizing offline Arabic handwritten text.