 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-text Keystroke Authentication using Transformers: A Comparative Study of Architectures and Loss Functions
Oct 18, 2023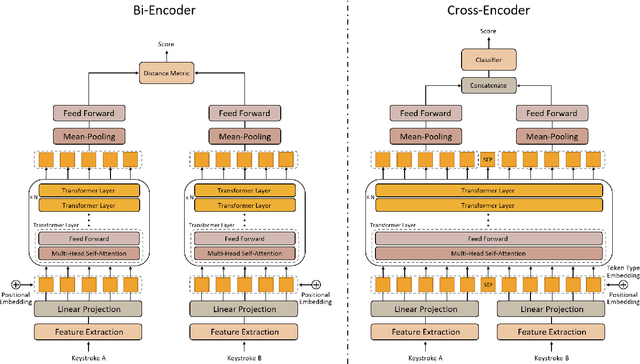
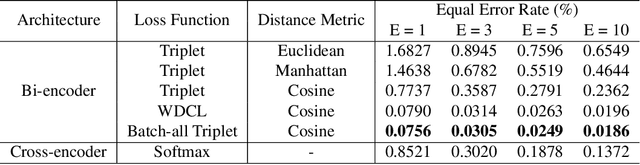
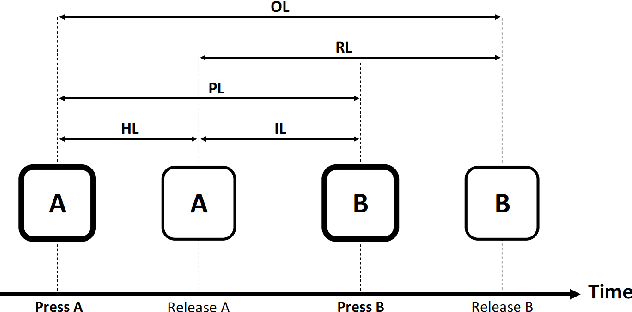

Keystroke biometrics is a promising approach for user identification and verification, leveraging the unique patterns in individuals' typing behavior. In this paper, we propose a Transformer-based network that employs self-attention to extract informative features from keystroke sequences, surpassing the performance of traditional Recurrent Neural Networks. We explore two distinct architectures, namely bi-encoder and cross-encoder, and compare their effectiveness in keystroke authentication. Furthermore, we investigate different loss functions, including triplet, batch-all triplet, and WDCL loss, along with various distance metrics such as Euclidean, Manhattan, and cosine distances. These experiments allow us to optimize the training process and enhance the performance of our model. To evaluate our proposed model, we employ the Aalto desktop keystroke dataset. The results demonstrate that the bi-encoder architecture with batch-all triplet loss and cosine distance achieves the best performance, yielding an exceptional Equal Error Rate of 0.0186%. Furthermore, alternative algorithms for calculating similarity scores are explored to enhance accuracy. Notably, the utilization of a one-class Support Vector Machine reduces the Equal Error Rate to an impressive 0.0163%. The outcomes of this study indicate that our model surpasses the previous state-of-the-art in free-text keystroke authentication. These findings contribute to advancing the field of keystroke authentication and offer practical implications for secure user verification systems.
Self-Supervised Representation Learning for Online Handwriting Text Classification
Oct 10, 2023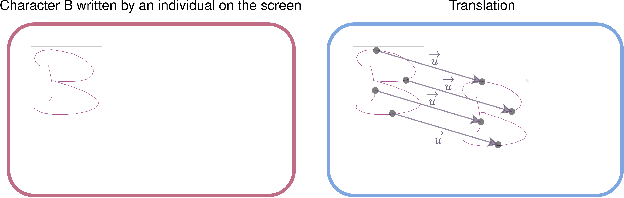
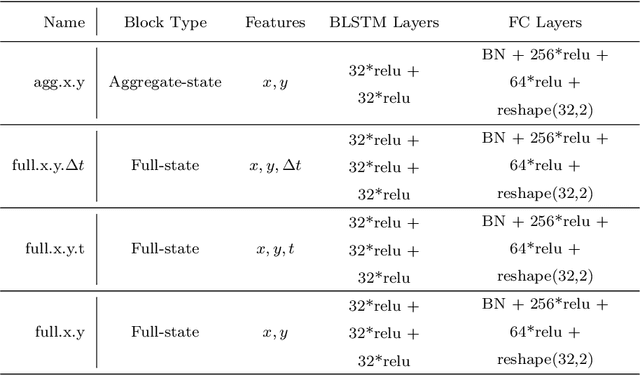
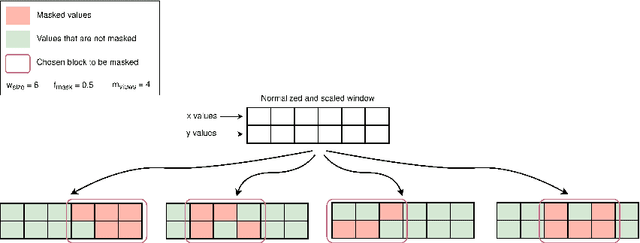
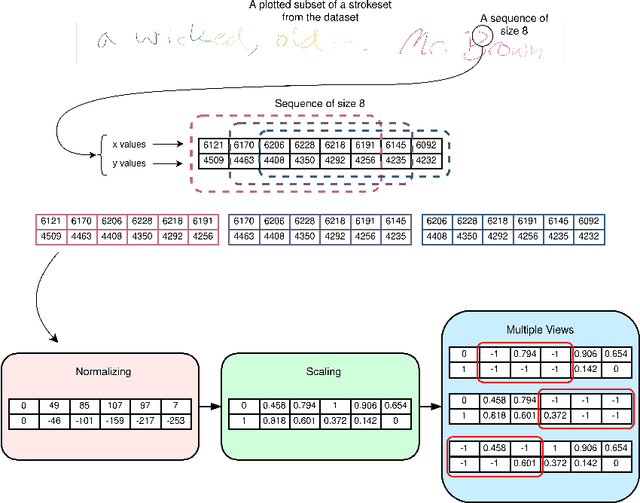
Self-supervised learning offers an efficient way of extracting rich representations from various types of unlabeled data while avoiding the cost of annotating large-scale datasets. This is achievable by designing a pretext task to form pseudo labels with respect to the modality and domain of the data. Given the evolving applications of online handwritten texts, in this study, we propose the novel Part of Stroke Masking (POSM) as a pretext task for pretraining models to extract informative representations from the online handwriting of individuals in English and Chinese languages, along with two suggested pipelines for fine-tuning the pretrained models. To evaluate the quality of the extracted representations, we use both intrinsic and extrinsic evaluation methods. The pretrained models are fine-tuned to achieve state-of-the-art results in tasks such as writer identification, gender classification, and handedness classification, also highlighting the superiority of utilizing the pretrained models over the models trained from scratch.
A Transformer-based Approach for Arabic Offline Handwritten Text Recognition
Jul 27, 2023



Handwriting recognition is a challenging and critical problem in the fields of pattern recognition and machine learning, with applications spanning a wide range of domains. In this paper, we focus on the specific issue of recognizing offline Arabic handwritten text. Existing approaches typically utilize a combination of convolutional neural networks for image feature extraction and recurrent neural networks for temporal modeling, with connectionist temporal classification used for text generation. However, these methods suffer from a lack of parallelization due to the sequential nature of recurrent neural networks. Furthermore, these models cannot account for linguistic rules, necessitating the use of an external language model in the post-processing stage to boost accuracy. To overcome these issues, we introduce two alternative architectures, namely the Transformer Transducer and the standard sequence-to-sequence Transformer, and compare their performance in terms of accuracy and speed. Our approach can model language dependencies and relies only on the attention mechanism, thereby making it more parallelizable and less complex. We employ pre-trained Transformers for both image understanding and language modeling. Our evaluation on the Arabic KHATT dataset demonstrates that our proposed method outperforms the current state-of-the-art approaches for recognizing offline Arabic handwritten text.
A Study into Pre-training Strategies for Spoken Language Understanding on Dysarthric Speech
Jun 15, 2021
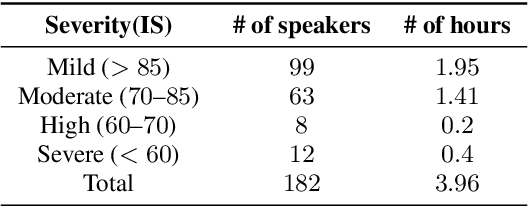

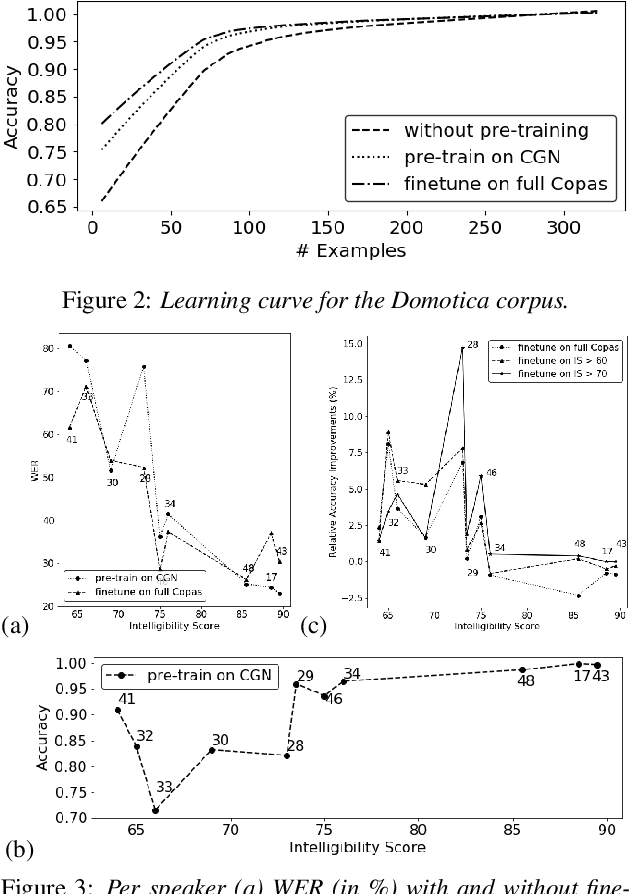
End-to-end (E2E) spoken language understanding (SLU) systems avoid an intermediate textual representation by mapping speech directly into intents with slot values. This approach requires considerable domain-specific training data. In low-resource scenarios this is a major concern, e.g., in the present study dealing with SLU for dysarthric speech. Pretraining part of the SLU model for automatic speech recognition targets helps but no research has shown to which extent SLU on dysarthric speech benefits from knowledge transferred from other dysarthric speech tasks. This paper investigates the efficiency of pre-training strategies for SLU tasks on dysarthric speech. The designed SLU system consists of a TDNN acoustic model for feature encoding and a capsule network for intent and slot decoding. The acoustic model is pre-trained in two stages: initialization with a corpus of normal speech and finetuning on a mixture of dysarthric and normal speech. By introducing the intelligibility score as a metric of the impairment severity, this paper quantitatively analyzes the relation between generalization and pathology severity for dysarthric speech.
I-vector Based Features Embedding for Heart Sound Classification
Apr 26, 2019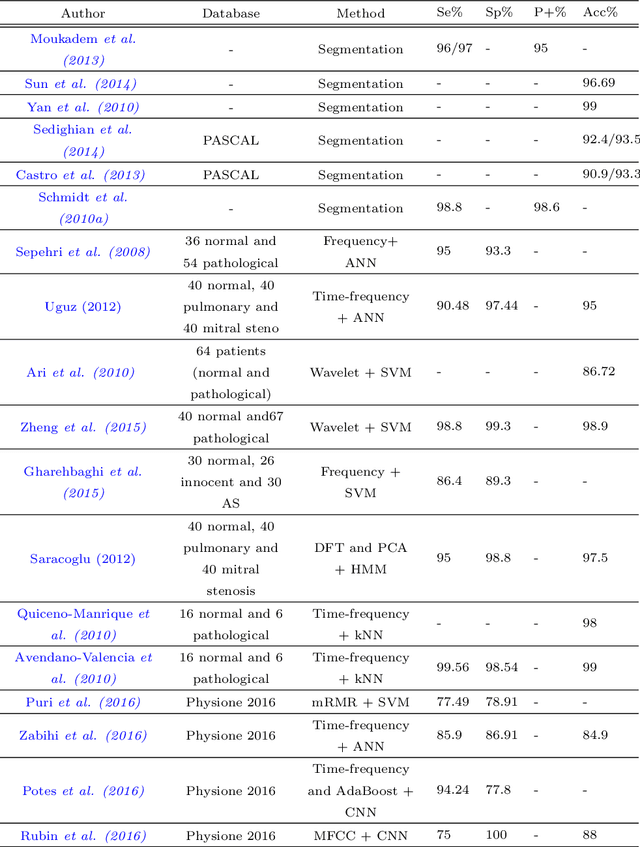
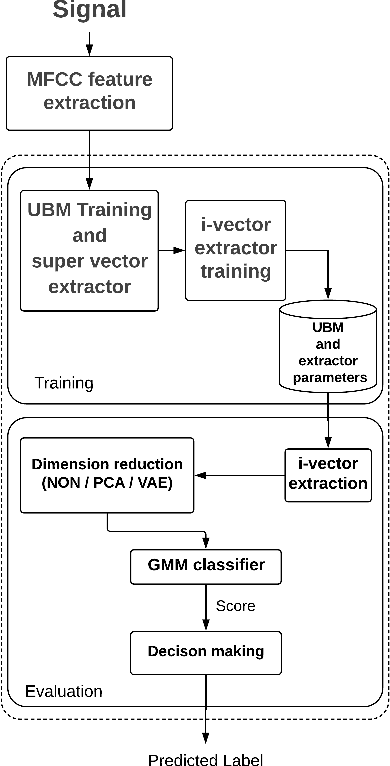


Cardiovascular disease (CVD) is considered as one of the main causes of death in the world. Accordingly, scientists look for methods to recognize normal/abnormal heart patterns. Over recent years, researchers have been interested in to investigate CVDs based on heart sounds. The physionet 2016 corpus is presented to provide a standard database for researchers in this field. In this study we proposed an approach for normal/abnormal heart sound detection, based on i-vector features on phiysionet 2016 corpus. In this method, a fixed length vector, namely i-vector, is extracted from each record, and then Principal Component Analysis (PCA) is applied. Then Variational AuotoEncoders (VAE) is used to reduce dimensions of the obtained i-vector. After that, this i-vector and its transmitted version by PCA and VAE are used for training two Gaussian Mixture Models (GMMs). Finally, test set is scored using these trained GMMs. In the next step we applied a simple global threshold to classify the obtained scores. We reported the results based on Equal Error Rate (EER) and Modified Accuracy (MAcc). Experimental results show the obtained Accuracy by our proposed system could improve the results reported on the baseline system by 16%.