 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
Jul 13, 2023



We address the video prediction task by putting forth a novel model that combines (i) our recently proposed hierarchical residual vector quantized variational autoencoder (HR-VQVAE), and (ii) a novel spatiotemporal PixelCNN (ST-PixelCNN). We refer to this approach as a sequential hierarchical residual learning vector quantized variational autoencoder (S-HR-VQVAE). By leveraging the intrinsic capabilities of HR-VQVAE at modeling still images with a parsimonious representation, combined with the ST-PixelCNN's ability at handling spatiotemporal information, S-HR-VQVAE can better deal with chief challenges in video prediction. These include learning spatiotemporal information, handling high dimensional data, combating blurry prediction, and implicit modeling of physical characteristics. Extensive experimental results on the KTH Human Action and Moving-MNIST tasks demonstrate that our model compares favorably against top video prediction techniques both in quantitative and qualitative evaluations despite a much smaller model size. Finally, we boost S-HR-VQVAE by proposing a novel training method to jointly estimate the HR-VQVAE and ST-PixelCNN parameters.
Hierarchical Residual Learning Based Vector Quantized Variational Autoencoder for Image Reconstruction and Generation
Aug 09, 2022

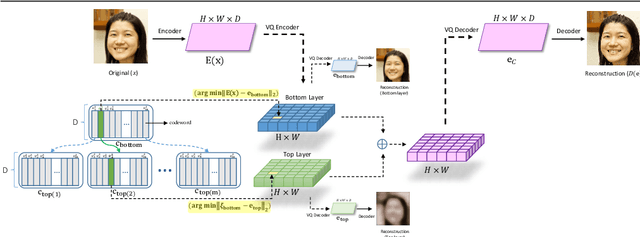
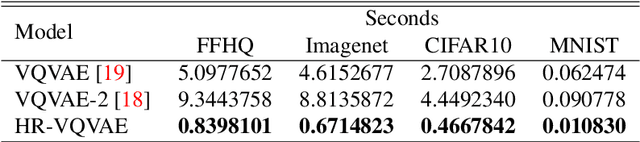
We propose a multi-layer variational autoencoder method, we call HR-VQVAE, that learns hierarchical discrete representations of the data. By utilizing a novel objective function, each layer in HR-VQVAE learns a discrete representation of the residual from previous layers through a vector quantized encoder. Furthermore, the representations at each layer are hierarchically linked to those at previous layers. We evaluate our method on the tasks of image reconstruction and generation. Experimental results demonstrate that the discrete representations learned by HR-VQVAE enable the decoder to reconstruct high-quality images with less distortion than the baseline methods, namely VQVAE and VQVAE-2. HR-VQVAE can also generate high-quality and diverse images that outperform state-of-the-art generative models, providing further verification of the efficiency of the learned representations. The hierarchical nature of HR-VQVAE i) reduces the decoding search time, making the method particularly suitable for high-load tasks and ii) allows to increase the codebook size without incurring the codebook collapse problem.
I-vector Based Features Embedding for Heart Sound Classification
Apr 26, 2019
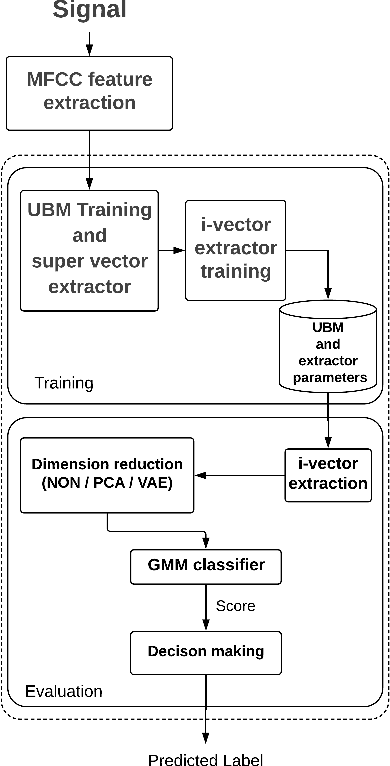


Cardiovascular disease (CVD) is considered as one of the main causes of death in the world. Accordingly, scientists look for methods to recognize normal/abnormal heart patterns. Over recent years, researchers have been interested in to investigate CVDs based on heart sounds. The physionet 2016 corpus is presented to provide a standard database for researchers in this field. In this study we proposed an approach for normal/abnormal heart sound detection, based on i-vector features on phiysionet 2016 corpus. In this method, a fixed length vector, namely i-vector, is extracted from each record, and then Principal Component Analysis (PCA) is applied. Then Variational AuotoEncoders (VAE) is used to reduce dimensions of the obtained i-vector. After that, this i-vector and its transmitted version by PCA and VAE are used for training two Gaussian Mixture Models (GMMs). Finally, test set is scored using these trained GMMs. In the next step we applied a simple global threshold to classify the obtained scores. We reported the results based on Equal Error Rate (EER) and Modified Accuracy (MAcc). Experimental results show the obtained Accuracy by our proposed system could improve the results reported on the baseline system by 16%.