 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Graph Representation Learning for Fraudster Group Detection
Jan 07, 2022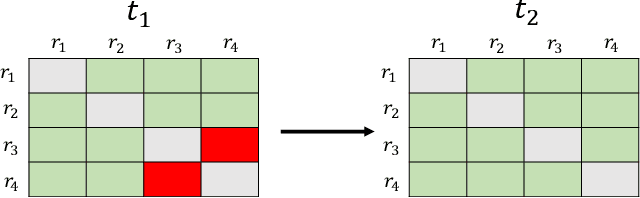

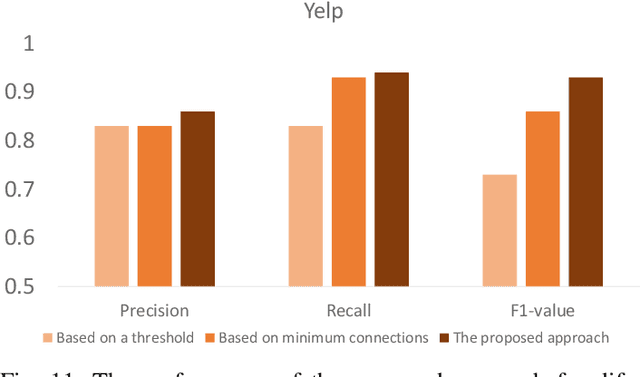
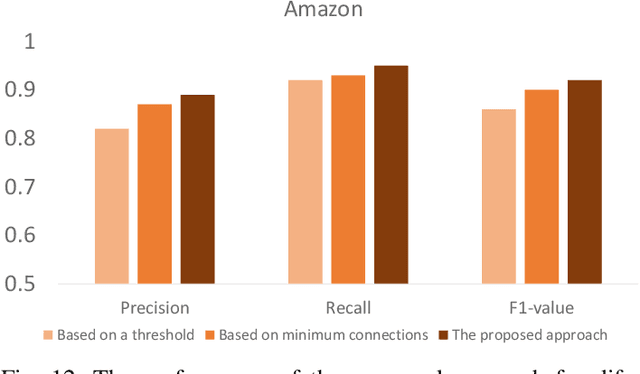
Motivated by potential financial gain, companies may hire fraudster groups to write fake reviews to either demote competitors or promote their own businesses. Such groups are considerably more successful in misleading customers, as people are more likely to be influenced by the opinion of a large group. To detect such groups, a common model is to represent fraudster groups' static networks, consequently overlooking the longitudinal behavior of a reviewer thus the dynamics of co-review relations among reviewers in a group. Hence, these approaches are incapable of excluding outlier reviewers, which are fraudsters intentionally camouflaging themselves in a group and genuine reviewers happen to co-review in fraudster groups. To address this issue, in this work, we propose to first capitalize on the effectiveness of the HIN-RNN in both reviewers' representation learning while capturing the collaboration between reviewers, we first utilize the HIN-RNN to model the co-review relations of reviewers in a group in a fixed time window of 28 days. We refer to this as spatial relation learning representation to signify the generalisability of this work to other networked scenarios. Then we use an RNN on the spatial relations to predict the spatio-temporal relations of reviewers in the group. In the third step, a Graph Convolution Network (GCN) refines the reviewers' vector representations using these predicted relations. These refined representations are then used to remove outlier reviewers. The average of the remaining reviewers' representation is then fed to a simple fully connected layer to predict if the group is a fraudster group or not. Exhaustive experiments of the proposed approach showed a 5% (4%), 12% (5%), 12% (5%) improvement over three of the most recent approaches on precision, recall, and F1-value over the Yelp (Amazon) dataset, respectively.
Social Fraud Detection Review: Methods, Challenges and Analysis
Nov 10, 2021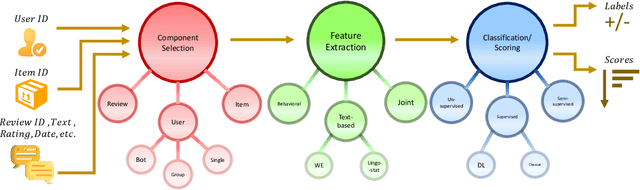
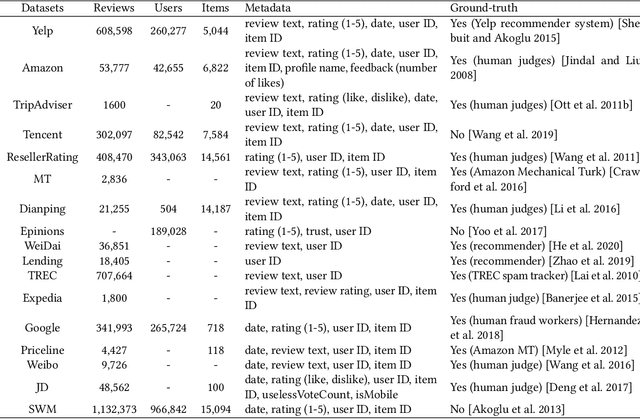
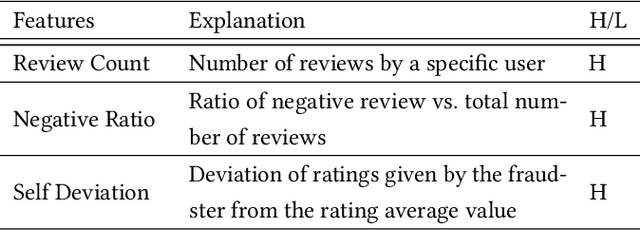
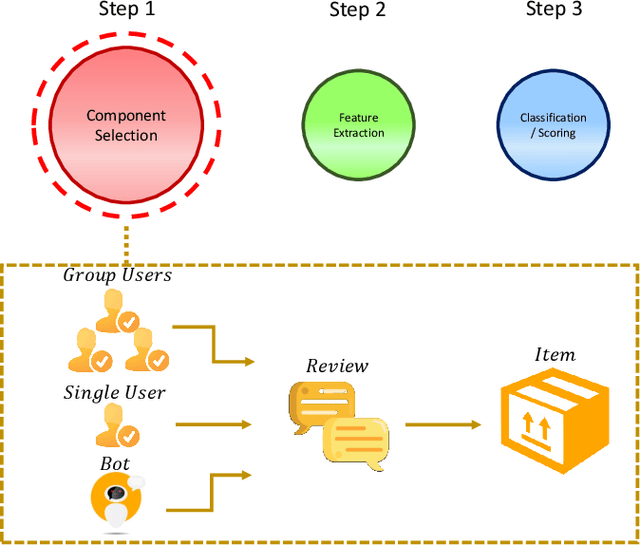
Social reviews have dominated the web and become a plausible source of product information. People and businesses use such information for decision-making. Businesses also make use of social information to spread fake information using a single user, groups of users, or a bot trained to generate fraudulent content. Many studies proposed approaches based on user behaviors and review text to address the challenges of fraud detection. To provide an exhaustive literature review, social fraud detection is reviewed using a framework that considers three key components: the review itself, the user who carries out the review, and the item being reviewed. As features are extracted for the component representation, a feature-wise review is provided based on behavioral, text-based features and their combination. With this framework, a comprehensive overview of approaches is presented including supervised, semi-supervised, and unsupervised learning. The supervised approaches for fraud detection are introduced and categorized into two sub-categories; classical, and deep learning. The lack of labeled datasets is explained and potential solutions are suggested. To help new researchers in the area develop a better understanding, a topic analysis and an overview of future directions is provided in each step of the proposed systematic framework.
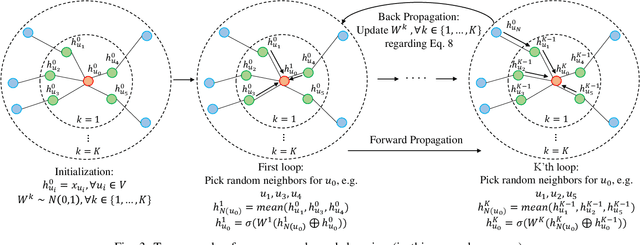
HIN-RNN: A Graph Representation Learning Neural Network for Fraudster Group Detection With No Handcrafted Features
May 25, 2021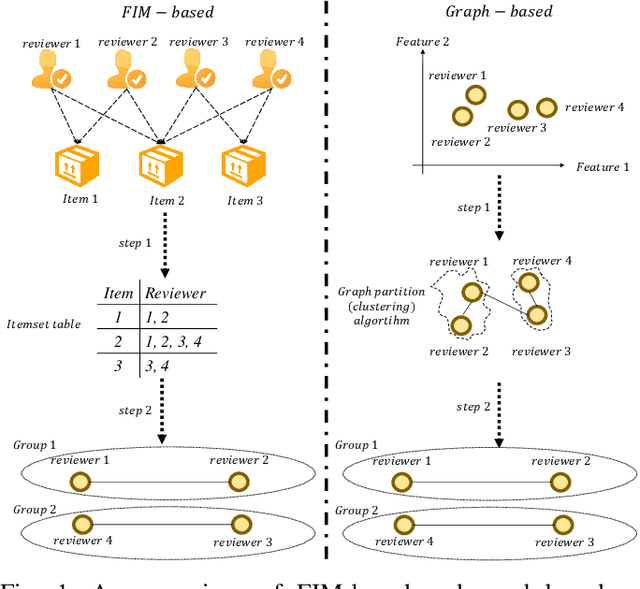

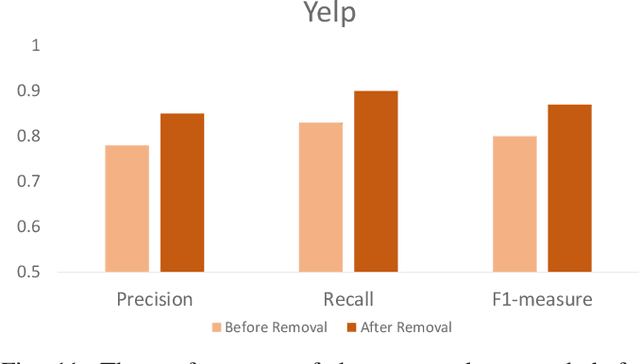
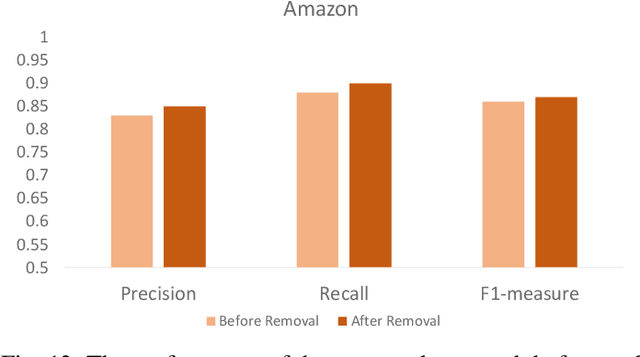
Social reviews are indispensable resources for modern consumers' decision making. For financial gain, companies pay fraudsters preferably in groups to demote or promote products and services since consumers are more likely to be misled by a large number of similar reviews from groups. Recent approaches on fraudster group detection employed handcrafted features of group behaviors without considering the semantic relation between reviews from the reviewers in a group. In this paper, we propose the first neural approach, HIN-RNN, a Heterogeneous Information Network (HIN) Compatible RNN for fraudster group detection that requires no handcrafted features. HIN-RNN provides a unifying architecture for representation learning of each reviewer, with the initial vector as the sum of word embeddings of all review text written by the same reviewer, concatenated by the ratio of negative reviews. Given a co-review network representing reviewers who have reviewed the same items with the same ratings and the reviewers' vector representation, a collaboration matrix is acquired through HIN-RNN training. The proposed approach is confirmed to be effective with marked improvement over state-of-the-art approaches on both the Yelp (22% and 12% in terms of recall and F1-value, respectively) and Amazon (4% and 2% in terms of recall and F1-value, respectively) datasets.
GANgster: A Fraud Review Detector based on Regulated GAN with Data Augmentation
Jun 11, 2020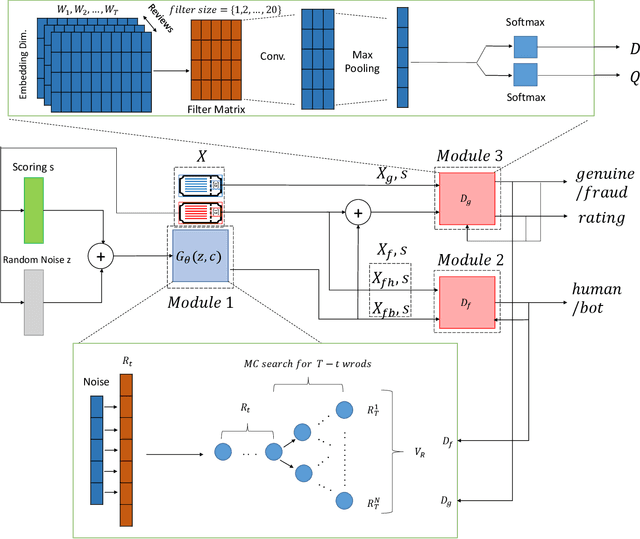
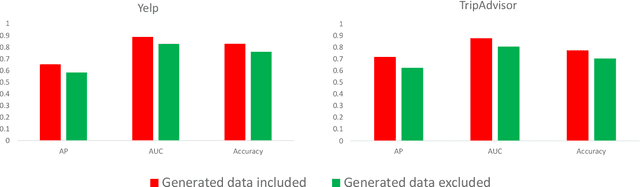
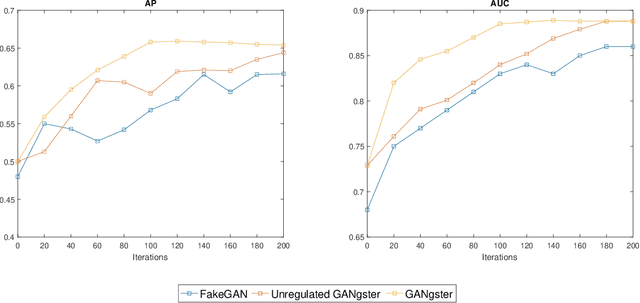
Financial implications of written reviews provide great incentives for businesses to pay fraudsters to write or use bots to generate fraud reviews. The promising performance of Deep Neural Networks (DNNs) in text classification, has attracted research to use them for fraud review detection. However, the lack of trusted labeled data has limited the performance of the current solutions in detecting fraud reviews. Unsupervised and semi-supervised methods are among the most applicable methods to deal with the data scarcity problem. Generative Adversarial Network (GAN) as a semi-supervised method has demonstrated to be effective for data augmentation purposes. The state-of-the-art solution utilizes GAN to overcome the data limitation problem. However, it fails to incorporate the behavioral clues in both fraud generation and detection. Besides, the state-of-the-art approach suffers from a common limitation in the training convergence of the GAN, slowing down the training procedure. In this work, we propose a regularised GAN for fraud review detection that makes use of both review text and review rating scores. Scores are incorporated through Information Gain Maximization in to the loss function for two reasons. One is to generate near-authentic and more human like score-correlated reviews. The other is to improve the stability of the GAN. Experimental results have shown better convergence of the regulated GAN. In addition, the scores are also used in combination with word embeddings of review text as input for the discriminators for better performance. Results show that the proposed framework relatively outperformed existing state-of-the-art framework; namely FakeGAN; in terms of AP by 7%, and 5% on the Yelp and TripAdvisor datasets, respectively.
DFraud3- Multi-Component Fraud Detection freeof Cold-start
Jun 11, 2020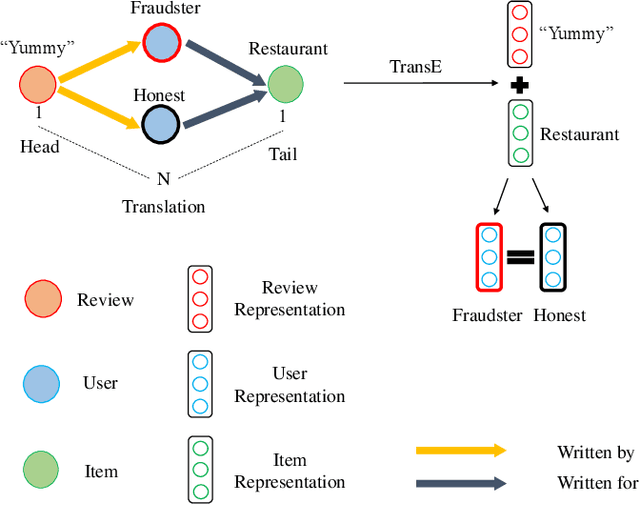
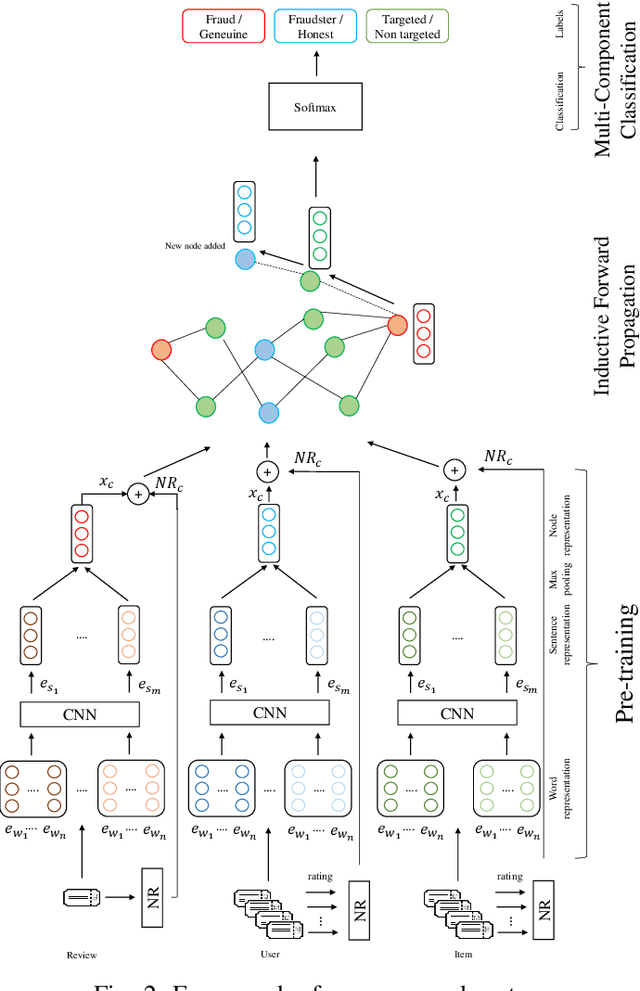
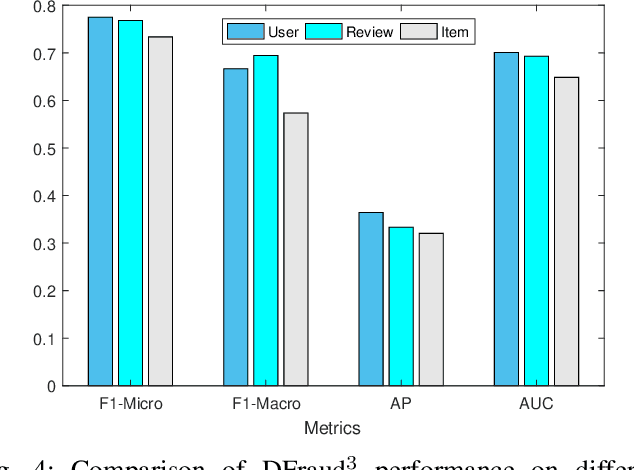
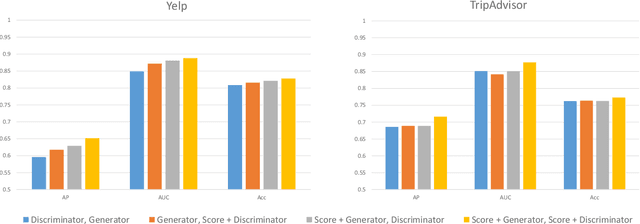
Fraud review detection is a hot research topic inrecent years. The Cold-start is a particularly new but significant problem referring to the failure of a detection system to recognize the authenticity of a new user. State-of-the-art solutions employ a translational knowledge graph embedding approach (TransE) to model the interaction of the components of a review system. However, these approaches suffer from the limitation of TransEin handling N-1 relations and the narrow scope of a single classification task, i.e., detecting fraudsters only. In this paper, we model a review system as a Heterogeneous InformationNetwork (HIN) which enables a unique representation to every component and performs graph inductive learning on the review data through aggregating features of nearby nodes. HIN with graph induction helps to address the camouflage issue (fraudsterswith genuine reviews) which has shown to be more severe when it is coupled with cold-start, i.e., new fraudsters with genuine first reviews. In this research, instead of focusing only on one component, detecting either fraud reviews or fraud users (fraudsters), vector representations are learnt for each component, enabling multi-component classification. In other words, we are able to detect fraud reviews, fraudsters, and fraud-targeted items, thus the name of our approach DFraud3. DFraud3 demonstrates a significant accuracy increase of 13% over the state of the art on Yelp.
I-vector Based Features Embedding for Heart Sound Classification
Apr 26, 2019
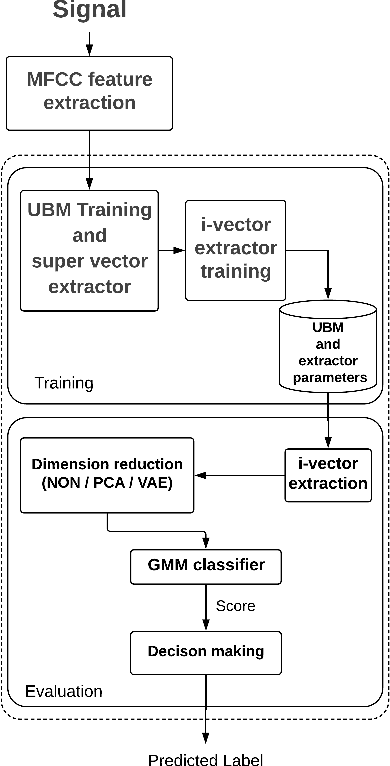


Cardiovascular disease (CVD) is considered as one of the main causes of death in the world. Accordingly, scientists look for methods to recognize normal/abnormal heart patterns. Over recent years, researchers have been interested in to investigate CVDs based on heart sounds. The physionet 2016 corpus is presented to provide a standard database for researchers in this field. In this study we proposed an approach for normal/abnormal heart sound detection, based on i-vector features on phiysionet 2016 corpus. In this method, a fixed length vector, namely i-vector, is extracted from each record, and then Principal Component Analysis (PCA) is applied. Then Variational AuotoEncoders (VAE) is used to reduce dimensions of the obtained i-vector. After that, this i-vector and its transmitted version by PCA and VAE are used for training two Gaussian Mixture Models (GMMs). Finally, test set is scored using these trained GMMs. In the next step we applied a simple global threshold to classify the obtained scores. We reported the results based on Equal Error Rate (EER) and Modified Accuracy (MAcc). Experimental results show the obtained Accuracy by our proposed system could improve the results reported on the baseline system by 16%.
NetSpam: a Network-based Spam Detection Framework for Reviews in Online Social Media
Mar 10, 2017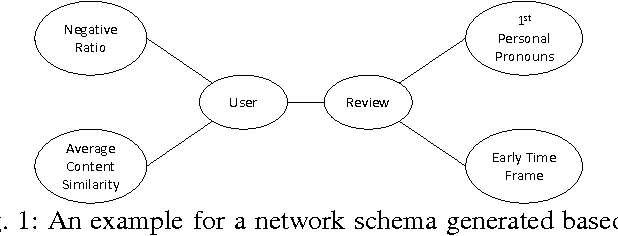
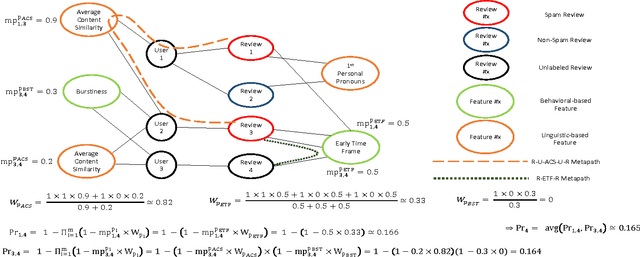


Nowadays, a big part of people rely on available content in social media in their decisions (e.g. reviews and feedback on a topic or product). The possibility that anybody can leave a review provide a golden opportunity for spammers to write spam reviews about products and services for different interests. Identifying these spammers and the spam content is a hot topic of research and although a considerable number of studies have been done recently toward this end, but so far the methodologies put forth still barely detect spam reviews, and none of them show the importance of each extracted feature type. In this study, we propose a novel framework, named NetSpam, which utilizes spam features for modeling review datasets as heterogeneous information networks to map spam detection procedure into a classification problem in such networks. Using the importance of spam features help us to obtain better results in terms of different metrics experimented on real-world review datasets from Yelp and Amazon websites. The results show that NetSpam outperforms the existing methods and among four categories of features; including review-behavioral, user-behavioral, reviewlinguistic, user-linguistic, the first type of features performs better than the other categories.