 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Mind World Model Inspired Network Digital Twin for Access Scheduling
Feb 04, 2026Emerging networked systems such as industrial IoT and real-time cyber-physical infrastructures demand intelligent scheduling strategies capable of adapting to dynamic traffic, deadlines, and interference constraints. In this work, we present a novel Digital Twin-enabled scheduling framework inspired by Dual Mind World Model (DMWM) architecture, for learning-informed and imagination-driven network control. Unlike conventional rule-based or purely data-driven policies, the proposed DMWM combines short-horizon predictive planning with symbolic model-based rollout, enabling the scheduler to anticipate future network states and adjust transmission decisions accordingly. We implement the framework in a configurable simulation testbed and benchmark its performance against traditional heuristics and reinforcement learning baselines under varied traffic conditions. Our results show that DMWM achieves superior performance in bursty, interference-limited, and deadline-sensitive environments, while maintaining interpretability and sample efficiency. The proposed design bridges the gap between network-level reasoning and low-overhead learning, marking a step toward scalable and adaptive NDT-based network optimization.
Redefining Toxicity: An Objective and Context-Aware Approach for Stress-Level-Based Detection
Mar 20, 2025
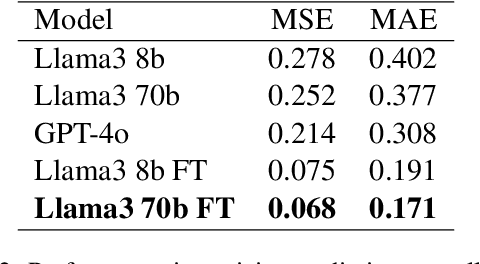
The fundamental problem of toxicity detection lies in the fact that the term "toxicity" is ill-defined. Such uncertainty causes researchers to rely on subjective and vague data during model training, which leads to non-robust and inaccurate results, following the 'garbage in - garbage out' paradigm. This study introduces a novel, objective, and context-aware framework for toxicity detection, leveraging stress levels as a key determinant of toxicity. We propose new definition, metric and training approach as a parts of our framework and demonstrate it's effectiveness using a dataset we collected.
Aligning Sentence Simplification with ESL Learner's Proficiency for Language Acquisition
Feb 17, 2025
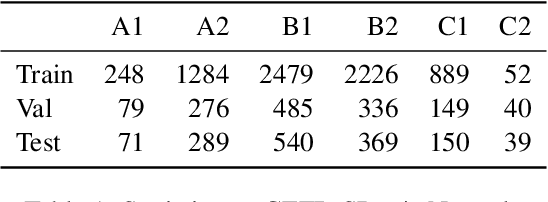
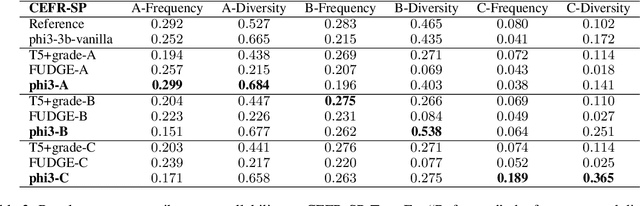
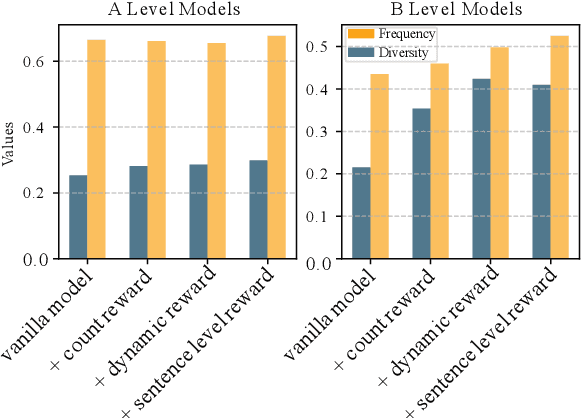
Text simplification is crucial for improving accessibility and comprehension for English as a Second Language (ESL) learners. This study goes a step further and aims to facilitate ESL learners' language acquisition by simplification. Specifically, we propose simplifying complex sentences to appropriate levels for learners while also increasing vocabulary coverage of the target level in the simplifications. We achieve this without a parallel corpus by conducting reinforcement learning on a large language model. Our method employs token-level and sentence-level rewards, and iteratively trains the model on its self-generated outputs to guide the model to search for simplification hypotheses that satisfy the target attributes. Experiment results on CEFR-SP and TurkCorpus datasets show that the proposed method can effectively increase the frequency and diversity of vocabulary of the target level by more than $20\%$ compared to baseline models, while maintaining high simplification quality.
Data-driven Modality Fusion: An AI-enabled Framework for Large-Scale Sensor Network Management
Feb 07, 2025



The development and operation of smart cities relyheavily on large-scale Internet-of-Things (IoT) networks and sensor infrastructures that continuously monitor various aspects of urban environments. These networks generate vast amounts of data, posing challenges related to bandwidth usage, energy consumption, and system scalability. This paper introduces a novel sensing paradigm called Data-driven Modality Fusion (DMF), designed to enhance the efficiency of smart city IoT network management. By leveraging correlations between timeseries data from different sensing modalities, the proposed DMF approach reduces the number of physical sensors required for monitoring, thereby minimizing energy expenditure, communication bandwidth, and overall deployment costs. The framework relocates computational complexity from the edge devices to the core, ensuring that resource-constrained IoT devices are not burdened with intensive processing tasks. DMF is validated using data from a real-world IoT deployment in Madrid, demonstrating the effectiveness of the proposed system in accurately estimating traffic, environmental, and pollution metrics from a reduced set of sensors. The proposed solution offers a scalable, efficient mechanism for managing urban IoT networks, while addressing issues of sensor failure and privacy concerns.
The TIP of the Iceberg: Revealing a Hidden Class of Task-In-Prompt Adversarial Attacks on LLMs
Jan 27, 2025We present a novel class of jailbreak adversarial attacks on LLMs, termed Task-in-Prompt (TIP) attacks. Our approach embeds sequence-to-sequence tasks (e.g., cipher decoding, riddles, code execution) into the model's prompt to indirectly generate prohibited inputs. To systematically assess the effectiveness of these attacks, we introduce the PHRYGE benchmark. We demonstrate that our techniques successfully circumvent safeguards in six state-of-the-art language models, including GPT-4o and LLaMA 3.2. Our findings highlight critical weaknesses in current LLM safety alignments and underscore the urgent need for more sophisticated defence strategies. Warning: this paper contains examples of unethical inquiries used solely for research purposes.
Towards Cross-Lingual Audio Abuse Detection in Low-Resource Settings with Few-Shot Learning
Dec 03, 2024Online abusive content detection, particularly in low-resource settings and within the audio modality, remains underexplored. We investigate the potential of pre-trained audio representations for detecting abusive language in low-resource languages, in this case, in Indian languages using Few Shot Learning (FSL). Leveraging powerful representations from models such as Wav2Vec and Whisper, we explore cross-lingual abuse detection using the ADIMA dataset with FSL. Our approach integrates these representations within the Model-Agnostic Meta-Learning (MAML) framework to classify abusive language in 10 languages. We experiment with various shot sizes (50-200) evaluating the impact of limited data on performance. Additionally, a feature visualization study was conducted to better understand model behaviour. This study highlights the generalization ability of pre-trained models in low-resource scenarios and offers valuable insights into detecting abusive language in multilingual contexts.
Read Over the Lines: Attacking LLMs and Toxicity Detection Systems with ASCII Art to Mask Profanity
Sep 27, 2024We introduce a novel family of adversarial attacks that exploit the inability of language models to interpret ASCII art. To evaluate these attacks, we propose the ToxASCII benchmark and develop two custom ASCII art fonts: one leveraging special tokens and another using text-filled letter shapes. Our attacks achieve a perfect 1.0 Attack Success Rate across ten models, including OpenAI's o1-preview and LLaMA 3.1. Warning: this paper contains examples of toxic language used for research purposes.
No offence, Bert -- I insult only humans! Multiple addressees sentence-level attack on toxicity detection neural network
Oct 19, 2023We introduce a simple yet efficient sentence-level attack on black-box toxicity detector models. By adding several positive words or sentences to the end of a hateful message, we are able to change the prediction of a neural network and pass the toxicity detection system check. This approach is shown to be working on seven languages from three different language families. We also describe the defence mechanism against the aforementioned attack and discuss its limitations.
On the definition of toxicity in NLP
Oct 05, 2023The fundamental problem in toxicity detection task lies in the fact that the toxicity is ill-defined. This causes us to rely on subjective and vague data in models' training, which results in non-robust and non-accurate results: garbage in - garbage out. This work suggests a new, stress-level-based definition of toxicity designed to be objective and context-aware. On par with it, we also describe possible ways of applying this new definition to dataset creation and model training.
Hate Speech and Offensive Language Detection using an Emotion-aware Shared Encoder
Feb 17, 2023The rise of emergence of social media platforms has fundamentally altered how people communicate, and among the results of these developments is an increase in online use of abusive content. Therefore, automatically detecting this content is essential for banning inappropriate information, and reducing toxicity and violence on social media platforms. The existing works on hate speech and offensive language detection produce promising results based on pre-trained transformer models, however, they considered only the analysis of abusive content features generated through annotated datasets. This paper addresses a multi-task joint learning approach which combines external emotional features extracted from another corpora in dealing with the imbalanced and scarcity of labeled datasets. Our analysis are using two well-known Transformer-based models, BERT and mBERT, where the later is used to address abusive content detection in multi-lingual scenarios. Our model jointly learns abusive content detection with emotional features by sharing representations through transformers' shared encoder. This approach increases data efficiency, reduce overfitting via shared representations, and ensure fast learning by leveraging auxiliary information. Our findings demonstrate that emotional knowledge helps to more reliably identify hate speech and offensive language across datasets. Our hate speech detection Multi-task model exhibited 3% performance improvement over baseline models, but the performance of multi-task models were not significant for offensive language detection task. More interestingly, in both tasks, multi-task models exhibits less false positive errors compared to single task scenario.