 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate Speech and Offensive Language Detection using an Emotion-aware Shared Encoder
Feb 17, 2023The rise of emergence of social media platforms has fundamentally altered how people communicate, and among the results of these developments is an increase in online use of abusive content. Therefore, automatically detecting this content is essential for banning inappropriate information, and reducing toxicity and violence on social media platforms. The existing works on hate speech and offensive language detection produce promising results based on pre-trained transformer models, however, they considered only the analysis of abusive content features generated through annotated datasets. This paper addresses a multi-task joint learning approach which combines external emotional features extracted from another corpora in dealing with the imbalanced and scarcity of labeled datasets. Our analysis are using two well-known Transformer-based models, BERT and mBERT, where the later is used to address abusive content detection in multi-lingual scenarios. Our model jointly learns abusive content detection with emotional features by sharing representations through transformers' shared encoder. This approach increases data efficiency, reduce overfitting via shared representations, and ensure fast learning by leveraging auxiliary information. Our findings demonstrate that emotional knowledge helps to more reliably identify hate speech and offensive language across datasets. Our hate speech detection Multi-task model exhibited 3% performance improvement over baseline models, but the performance of multi-task models were not significant for offensive language detection task. More interestingly, in both tasks, multi-task models exhibits less false positive errors compared to single task scenario.
BERT-based Ensemble Approaches for Hate Speech Detection
Sep 15, 2022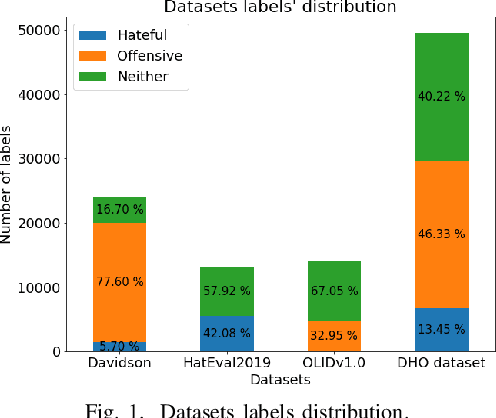
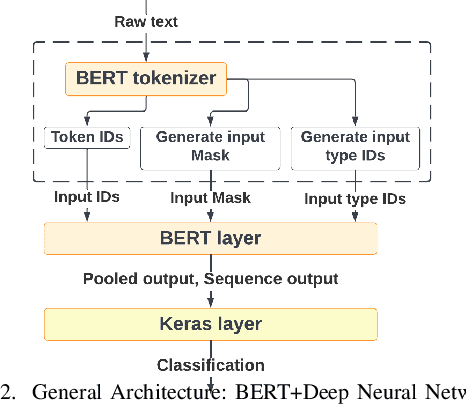
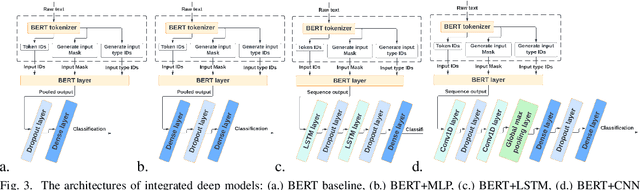
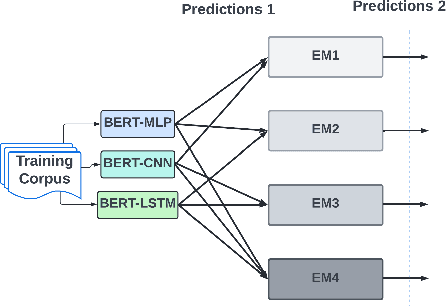
With the freedom of communication provided in online social media, hate speech has increasingly generated. This leads to cyber conflicts affecting social life at the individual and national levels. As a result, hateful content classification is becoming increasingly demanded for filtering hate content before being sent to the social networks. This paper focuses on classifying hate speech in social media using multiple deep models that are implemented by integrating recent transformer-based language models such as BERT, and neural networks. To improve the classification performances, we evaluated with several ensemble techniques, including soft voting, maximum value, hard voting and stacking. We used three publicly available Twitter datasets (Davidson, HatEval2019, OLID) that are generated to identify offensive languages. We fused all these datasets to generate a single dataset (DHO dataset), which is more balanced across different labels, to perform multi-label classification. Our experiments have been held on Davidson dataset and the DHO corpora. The later gave the best overall results, especially F1 macro score, even it required more resources (time execution and memory). The experiments have shown good results especially the ensemble models, where stacking gave F1 score of 97% on Davidson dataset and aggregating ensembles 77% on the DHO dataset.