 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-StepBench: A Hierarchical Reasoning Framework for Evaluating Hallucinations in Medical Vision-Language Models
May 11, 2026Large vision-language models (VLMs) demonstrate strong performance in medical image understanding, but frequently generate clinically plausible yet incorrect statements, raising significant safety concerns. Existing medical hallucination benchmarks primarily focus on 2D imaging with one-shot diagnostic questions, offering limited insight into whether predictions are grounded in correct localization and abnormality identification, allowing critical reasoning errors to remain hidden behind seemingly correct diagnoses. We introduce Med-StepBench, the first large-scale benchmark for step-wise hallucination detection in 3D oncological PET/CT, comprising over 12,000 images and more than 1,000,000 image-statement pairs across volumetric and multi-view 2D data, which decomposes clinical reasoning into four expert-designed diagnostic stages. Using clinician-verified annotations, we perform the first step-level evaluation of general-purpose and medical VLMs, revealing systematic failure modes obscured by aggregate accuracy metrics. Furthermore, we show that current VLMs are highly susceptible to adversarial yet clinically plausible intermediate explanations, which significantly amplify hallucinations despite contradictory visual evidence. Together, our findings highlight fundamental limitations in grounding multi-step clinical reasoning and establish Med-StepBench as a rigorous benchmark for developing safer and more reliable medical VLMs.
Region-Grounded Report Generation for 3D Medical Imaging: A Fine-Grained Dataset and Graph-Enhanced Framework
Apr 20, 2026Automated medical report generation for 3D PET/CT imaging is fundamentally challenged by the high-dimensional nature of volumetric data and a critical scarcity of annotated datasets, particularly for low-resource languages. Current black-box methods map whole volumes to reports, ignoring the clinical workflow of analyzing localized Regions of Interest (RoIs) to derive diagnostic conclusions. In this paper, we bridge this gap by introducing VietPET-RoI, the first large-scale 3D PET/CT dataset with fine-grained RoI annotation for a low-resource language, comprising 600 PET/CT samples and 1,960 manually annotated RoIs, paired with corresponding clinical reports. Furthermore, to demonstrate the utility of this dataset, we propose HiRRA, a novel framework that mimics the professional radiologist diagnostic workflow by employing graph-based relational modules to capture dependencies between RoI attributes. This approach shifts from global pattern matching toward localized clinical findings. Additionally, we introduce new clinical evaluation metrics, namely RoI Coverage and RoI Quality Index, that measure both RoI localization accuracy and attribute description fidelity using LLM-based extraction. Extensive evaluation demonstrates that our framework achieves SOTA performance, surpassing existing models by 19.7% in BLEU and 4.7% in ROUGE-L, while achieving a remarkable 45.8% improvement in clinical metrics, indicating enhanced clinical reliability and reduced hallucination. Our code and dataset are available on GitHub.
Few-Shot Contrastive Adaptation for Audio Abuse Detection in Low-Resource Indic Languages
Apr 10, 2026Abusive speech detection is becoming increasingly important as social media shifts towards voice-based interaction, particularly in multilingual and low-resource settings. Most current systems rely on automatic speech recognition (ASR) followed by text-based hate speech classification, but this pipeline is vulnerable to transcription errors and discards prosodic information carried in speech. We investigate whether Contrastive Language-Audio Pre-training (CLAP) can support abusive speech detection directly from audio. Using the ADIMA dataset, we evaluate CLAP-based representations under few-shot supervised contrastive adaptation in cross-lingual and leave-one-language-out settings, with zero-shot prompting included as an auxiliary analysis. Our results show that CLAP yields strong cross-lingual audio representations across ten Indic languages, and that lightweight projection-only adaptation achieves competitive performance with respect to fully supervised systems trained on complete training data. However, the benefits of few-shot adaptation are language-dependent and not monotonic with shot size. These findings suggest that contrastive audio-text models provide a promising basis for cross-lingual audio abuse detection in low-resource settings, while also indicating that transfer remains incomplete and language-specific in important ways.
Redefining Toxicity: An Objective and Context-Aware Approach for Stress-Level-Based Detection
Mar 20, 2025
The fundamental problem of toxicity detection lies in the fact that the term "toxicity" is ill-defined. Such uncertainty causes researchers to rely on subjective and vague data during model training, which leads to non-robust and inaccurate results, following the 'garbage in - garbage out' paradigm. This study introduces a novel, objective, and context-aware framework for toxicity detection, leveraging stress levels as a key determinant of toxicity. We propose new definition, metric and training approach as a parts of our framework and demonstrate it's effectiveness using a dataset we collected.
The TIP of the Iceberg: Revealing a Hidden Class of Task-In-Prompt Adversarial Attacks on LLMs
Jan 27, 2025We present a novel class of jailbreak adversarial attacks on LLMs, termed Task-in-Prompt (TIP) attacks. Our approach embeds sequence-to-sequence tasks (e.g., cipher decoding, riddles, code execution) into the model's prompt to indirectly generate prohibited inputs. To systematically assess the effectiveness of these attacks, we introduce the PHRYGE benchmark. We demonstrate that our techniques successfully circumvent safeguards in six state-of-the-art language models, including GPT-4o and LLaMA 3.2. Our findings highlight critical weaknesses in current LLM safety alignments and underscore the urgent need for more sophisticated defence strategies. Warning: this paper contains examples of unethical inquiries used solely for research purposes.
Towards Cross-Lingual Audio Abuse Detection in Low-Resource Settings with Few-Shot Learning
Dec 03, 2024Online abusive content detection, particularly in low-resource settings and within the audio modality, remains underexplored. We investigate the potential of pre-trained audio representations for detecting abusive language in low-resource languages, in this case, in Indian languages using Few Shot Learning (FSL). Leveraging powerful representations from models such as Wav2Vec and Whisper, we explore cross-lingual abuse detection using the ADIMA dataset with FSL. Our approach integrates these representations within the Model-Agnostic Meta-Learning (MAML) framework to classify abusive language in 10 languages. We experiment with various shot sizes (50-200) evaluating the impact of limited data on performance. Additionally, a feature visualization study was conducted to better understand model behaviour. This study highlights the generalization ability of pre-trained models in low-resource scenarios and offers valuable insights into detecting abusive language in multilingual contexts.
Read Over the Lines: Attacking LLMs and Toxicity Detection Systems with ASCII Art to Mask Profanity
Sep 27, 2024We introduce a novel family of adversarial attacks that exploit the inability of language models to interpret ASCII art. To evaluate these attacks, we propose the ToxASCII benchmark and develop two custom ASCII art fonts: one leveraging special tokens and another using text-filled letter shapes. Our attacks achieve a perfect 1.0 Attack Success Rate across ten models, including OpenAI's o1-preview and LLaMA 3.1. Warning: this paper contains examples of toxic language used for research purposes.
Adversarial Botometer: Adversarial Analysis for Social Bot Detection
May 03, 2024

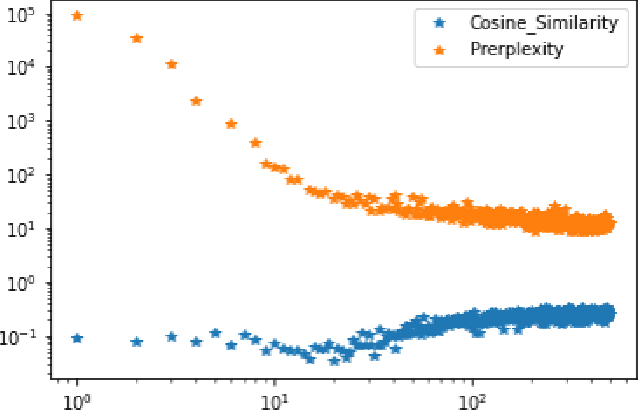
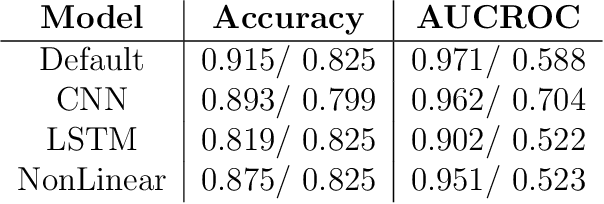
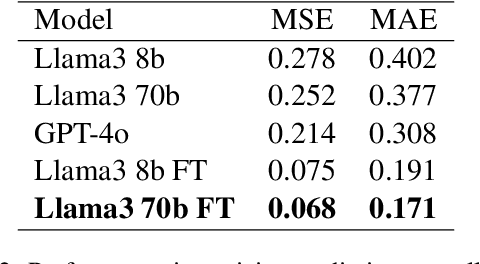
Social bots play a significant role in many online social networks (OSN) as they imitate human behavior. This fact raises difficult questions about their capabilities and potential risks. Given the recent advances in Generative AI (GenAI), social bots are capable of producing highly realistic and complex content that mimics human creativity. As the malicious social bots emerge to deceive people with their unrealistic content, identifying them and distinguishing the content they produce has become an actual challenge for numerous social platforms. Several approaches to this problem have already been proposed in the literature, but the proposed solutions have not been widely evaluated. To address this issue, we evaluate the behavior of a text-based bot detector in a competitive environment where some scenarios are proposed: \textit{First}, the tug-of-war between a bot and a bot detector is examined. It is interesting to analyze which party is more likely to prevail and which circumstances influence these expectations. In this regard, we model the problem as a synthetic adversarial game in which a conversational bot and a bot detector are engaged in strategic online interactions. \textit{Second}, the bot detection model is evaluated under attack examples generated by a social bot; to this end, we poison the dataset with attack examples and evaluate the model performance under this condition. \textit{Finally}, to investigate the impact of the dataset, a cross-domain analysis is performed. Through our comprehensive evaluation of different categories of social bots using two benchmark datasets, we were able to demonstrate some achivement that could be utilized in future works.
No offence, Bert -- I insult only humans! Multiple addressees sentence-level attack on toxicity detection neural network
Oct 19, 2023We introduce a simple yet efficient sentence-level attack on black-box toxicity detector models. By adding several positive words or sentences to the end of a hateful message, we are able to change the prediction of a neural network and pass the toxicity detection system check. This approach is shown to be working on seven languages from three different language families. We also describe the defence mechanism against the aforementioned attack and discuss its limitations.
On the definition of toxicity in NLP
Oct 05, 2023The fundamental problem in toxicity detection task lies in the fact that the toxicity is ill-defined. This causes us to rely on subjective and vague data in models' training, which results in non-robust and non-accurate results: garbage in - garbage out. This work suggests a new, stress-level-based definition of toxicity designed to be objective and context-aware. On par with it, we also describe possible ways of applying this new definition to dataset creation and model training.