 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Toxicity: An Objective and Context-Aware Approach for Stress-Level-Based Detection
Mar 20, 2025
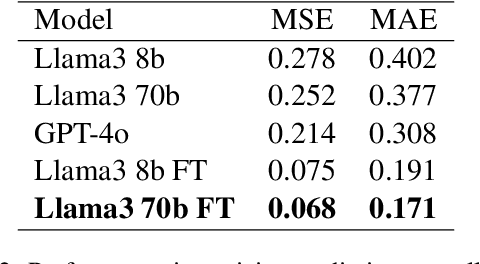
The fundamental problem of toxicity detection lies in the fact that the term "toxicity" is ill-defined. Such uncertainty causes researchers to rely on subjective and vague data during model training, which leads to non-robust and inaccurate results, following the 'garbage in - garbage out' paradigm. This study introduces a novel, objective, and context-aware framework for toxicity detection, leveraging stress levels as a key determinant of toxicity. We propose new definition, metric and training approach as a parts of our framework and demonstrate it's effectiveness using a dataset we collected.
The TIP of the Iceberg: Revealing a Hidden Class of Task-In-Prompt Adversarial Attacks on LLMs
Jan 27, 2025We present a novel class of jailbreak adversarial attacks on LLMs, termed Task-in-Prompt (TIP) attacks. Our approach embeds sequence-to-sequence tasks (e.g., cipher decoding, riddles, code execution) into the model's prompt to indirectly generate prohibited inputs. To systematically assess the effectiveness of these attacks, we introduce the PHRYGE benchmark. We demonstrate that our techniques successfully circumvent safeguards in six state-of-the-art language models, including GPT-4o and LLaMA 3.2. Our findings highlight critical weaknesses in current LLM safety alignments and underscore the urgent need for more sophisticated defence strategies. Warning: this paper contains examples of unethical inquiries used solely for research purposes.
Read Over the Lines: Attacking LLMs and Toxicity Detection Systems with ASCII Art to Mask Profanity
Sep 27, 2024We introduce a novel family of adversarial attacks that exploit the inability of language models to interpret ASCII art. To evaluate these attacks, we propose the ToxASCII benchmark and develop two custom ASCII art fonts: one leveraging special tokens and another using text-filled letter shapes. Our attacks achieve a perfect 1.0 Attack Success Rate across ten models, including OpenAI's o1-preview and LLaMA 3.1. Warning: this paper contains examples of toxic language used for research purposes.
No offence, Bert -- I insult only humans! Multiple addressees sentence-level attack on toxicity detection neural network
Oct 19, 2023We introduce a simple yet efficient sentence-level attack on black-box toxicity detector models. By adding several positive words or sentences to the end of a hateful message, we are able to change the prediction of a neural network and pass the toxicity detection system check. This approach is shown to be working on seven languages from three different language families. We also describe the defence mechanism against the aforementioned attack and discuss its limitations.
On the definition of toxicity in NLP
Oct 05, 2023The fundamental problem in toxicity detection task lies in the fact that the toxicity is ill-defined. This causes us to rely on subjective and vague data in models' training, which results in non-robust and non-accurate results: garbage in - garbage out. This work suggests a new, stress-level-based definition of toxicity designed to be objective and context-aware. On par with it, we also describe possible ways of applying this new definition to dataset creation and model training.
Named Entity Inclusion in Abstractive Text Summarization
Jul 05, 2023We address the named entity omission - the drawback of many current abstractive text summarizers. We suggest a custom pretraining objective to enhance the model's attention on the named entities in a text. At first, the named entity recognition model RoBERTa is trained to determine named entities in the text. After that, this model is used to mask named entities in the text and the BART model is trained to reconstruct them. Next, the BART model is fine-tuned on the summarization task. Our experiments showed that this pretraining approach improves named entity inclusion precision and recall metrics.
* https://aclanthology.org/2022.sdp-1.17/