 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model
Aug 28, 2020


Disparate biases associated with datasets and trained classifiers in hateful and abusive content identification tasks have raised many concerns recently. Although the problem of biased datasets on abusive language detection has been addressed more frequently, biases arising from trained classifiers have not yet been a matter of concern. Here, we first introduce a transfer learning approach for hate speech detection based on an existing pre-trained language model called BERT and evaluate the proposed model on two publicly available datasets annotated for racism, sexism, hate or offensive content on Twitter. Next, we introduce a bias alleviation mechanism in hate speech detection task to mitigate the effect of bias in training set during the fine-tuning of our pre-trained BERT-based model. Toward that end, we use an existing regularization method to reweight input samples, thereby decreasing the effects of high correlated training set' s n-grams with class labels, and then fine-tune our pre-trained BERT-based model with the new re-weighted samples. To evaluate our bias alleviation mechanism, we employ a cross-domain approach in which we use the trained classifiers on the aforementioned datasets to predict the labels of two new datasets from Twitter, AAE-aligned and White-aligned groups, which indicate tweets written in African-American English (AAE) and Standard American English (SAE) respectively. The results show the existence of systematic racial bias in trained classifiers as they tend to assign tweets written in AAE from AAE-aligned group to negative classes such as racism, sexism, hate, and offensive more often than tweets written in SAE from White-aligned. However, the racial bias in our classifiers reduces significantly after our bias alleviation mechanism is incorporated. This work could institute the first step towards debiasing hate speech and abusive language detection systems.
A BERT-Based Transfer Learning Approach for Hate Speech Detection in Online Social Media
Oct 28, 2019


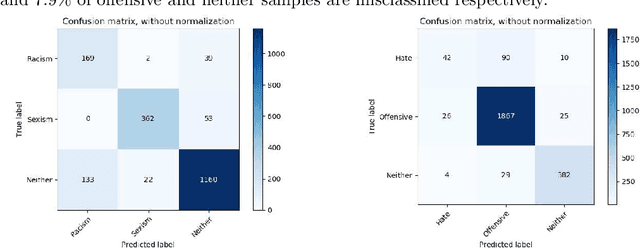
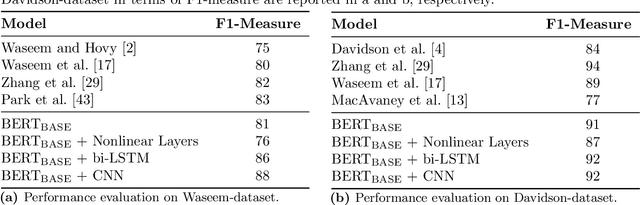
Generated hateful and toxic content by a portion of users in social media is a rising phenomenon that motivated researchers to dedicate substantial efforts to the challenging direction of hateful content identification. We not only need an efficient automatic hate speech detection model based on advanced machine learning and natural language processing, but also a sufficiently large amount of annotated data to train a model. The lack of a sufficient amount of labelled hate speech data, along with the existing biases, has been the main issue in this domain of research. To address these needs, in this study we introduce a novel transfer learning approach based on an existing pre-trained language model called BERT (Bidirectional Encoder Representations from Transformers). More specifically, we investigate the ability of BERT at capturing hateful context within social media content by using new fine-tuning methods based on transfer learning. To evaluate our proposed approach, we use two publicly available datasets that have been annotated for racism, sexism, hate, or offensive content on Twitter. The results show that our solution obtains considerable performance on these datasets in terms of precision and recall in comparison to existing approaches. Consequently, our model can capture some biases in data annotation and collection process and can potentially lead us to a more accurate model.