 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Emotion Recognition Leveraging OpenAI's Whisper Representations and Attentive Pooling Methods
Feb 05, 2026Speech Emotion Recognition (SER) research has faced limitations due to the lack of standard and sufficiently large datasets. Recent studies have leveraged pre-trained models to extract features for downstream tasks such as SER. This work explores the capabilities of Whisper, a pre-trained ASR system, in speech emotion recognition by proposing two attention-based pooling methods, Multi-head Attentive Average Pooling and QKV Pooling, designed to efficiently reduce the dimensionality of Whisper representations while preserving emotional features. We experiment on English and Persian, using the IEMOCAP and ShEMO datasets respectively, with Whisper Tiny and Small. Our multi-head QKV architecture achieves state-of-the-art results on the ShEMO dataset, with a 2.47% improvement in unweighted accuracy. We further compare the performance of different Whisper encoder layers and find that intermediate layers often perform better for SER on the Persian dataset, providing a lightweight and efficient alternative to much larger models such as HuBERT X-Large. Our findings highlight the potential of Whisper as a representation extractor for SER and demonstrate the effectiveness of attention-based pooling for dimension reduction.
Adversarial Botometer: Adversarial Analysis for Social Bot Detection
May 03, 2024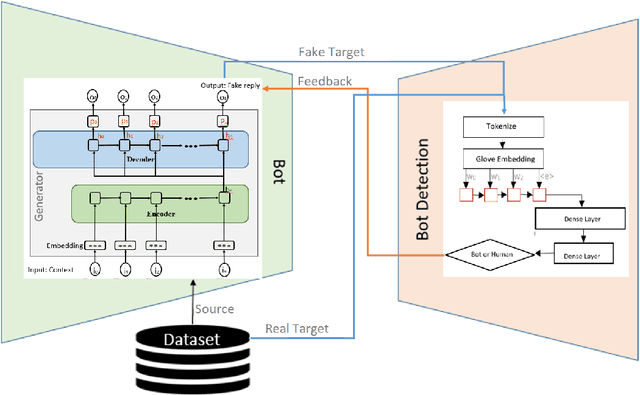

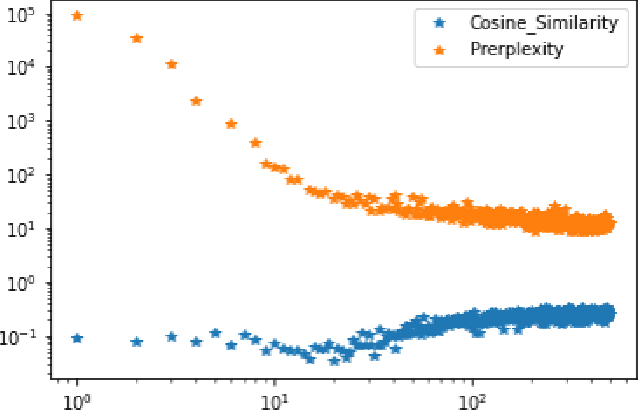
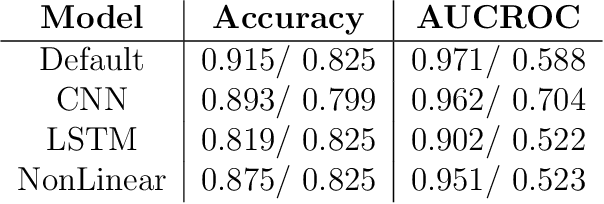
Social bots play a significant role in many online social networks (OSN) as they imitate human behavior. This fact raises difficult questions about their capabilities and potential risks. Given the recent advances in Generative AI (GenAI), social bots are capable of producing highly realistic and complex content that mimics human creativity. As the malicious social bots emerge to deceive people with their unrealistic content, identifying them and distinguishing the content they produce has become an actual challenge for numerous social platforms. Several approaches to this problem have already been proposed in the literature, but the proposed solutions have not been widely evaluated. To address this issue, we evaluate the behavior of a text-based bot detector in a competitive environment where some scenarios are proposed: \textit{First}, the tug-of-war between a bot and a bot detector is examined. It is interesting to analyze which party is more likely to prevail and which circumstances influence these expectations. In this regard, we model the problem as a synthetic adversarial game in which a conversational bot and a bot detector are engaged in strategic online interactions. \textit{Second}, the bot detection model is evaluated under attack examples generated by a social bot; to this end, we poison the dataset with attack examples and evaluate the model performance under this condition. \textit{Finally}, to investigate the impact of the dataset, a cross-domain analysis is performed. Through our comprehensive evaluation of different categories of social bots using two benchmark datasets, we were able to demonstrate some achivement that could be utilized in future works.
A Meta Path-based Approach for Rumor Detection on Social Media
Jan 11, 2023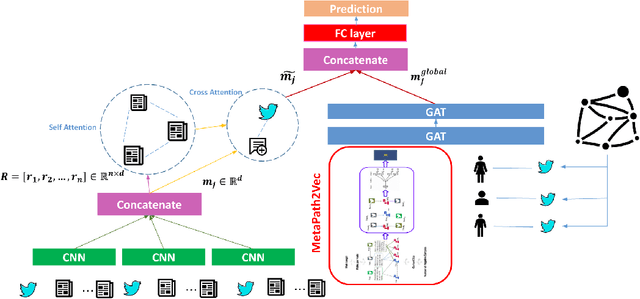
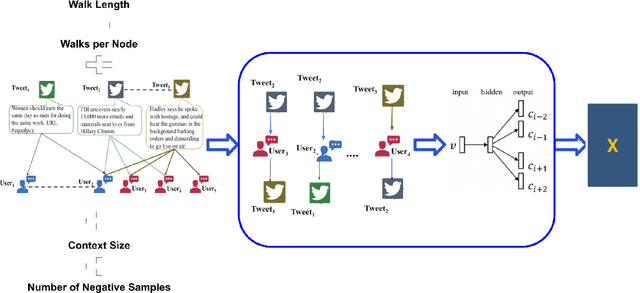
The prominent role of social media in people's daily lives has made them more inclined to receive news through social networks than traditional sources. This shift in public behavior has opened doors for some to diffuse fake news on social media; and subsequently cause negative economic, political, and social consequences as well as distrust among the public. There are many proposed methods to solve the rumor detection problem, most of which do not take full advantage of the heterogeneous nature of news propagation networks. With this intention, we considered a previously proposed architecture as our baseline and performed the idea of structural feature extraction from the heterogeneous rumor propagation over its architecture using the concept of meta path-based embeddings. We named our model Meta Path-based Global Local Attention Network (MGLAN). Extensive experimental analysis on three state-of-the-art datasets has demonstrated that MGLAN outperforms other models by capturing node-level discrimination to different node types.
Convolutional Neural Networks for Sentiment Analysis in Persian Social Media
Feb 14, 2020With the social media engagement on the rise, the resulting data can be used as a rich resource for analyzing and understanding different phenomena around us. A sentiment analysis system employs these data to find the attitude of social media users towards certain entities in a given document. In this paper we propose a sentiment analysis method for Persian text using Convolutional Neural Network (CNN), a feedforward Artificial Neural Network, that categorize sentences into two and five classes (considering their intensity) by applying a layer of convolution over input data through different filters. We evaluated the method on three different datasets of Persian social media texts using Area under Curve metric. The final results show the advantage of using CNN over earlier attempts at developing traditional machine learning methods for Persian texts sentiment classification especially for short texts.
NetSpam: a Network-based Spam Detection Framework for Reviews in Online Social Media
Mar 10, 2017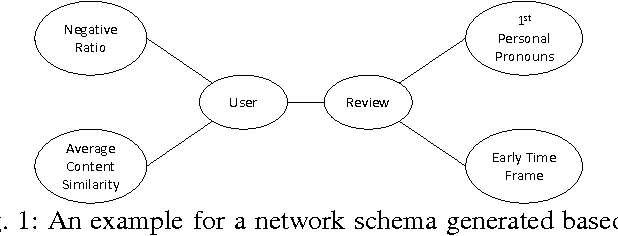
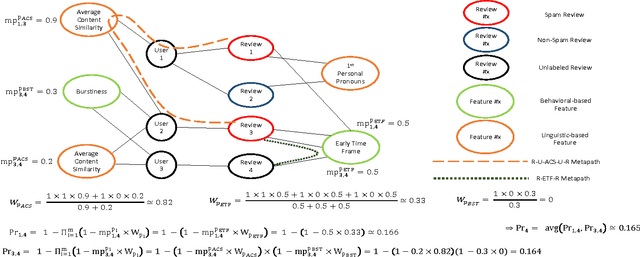


Nowadays, a big part of people rely on available content in social media in their decisions (e.g. reviews and feedback on a topic or product). The possibility that anybody can leave a review provide a golden opportunity for spammers to write spam reviews about products and services for different interests. Identifying these spammers and the spam content is a hot topic of research and although a considerable number of studies have been done recently toward this end, but so far the methodologies put forth still barely detect spam reviews, and none of them show the importance of each extracted feature type. In this study, we propose a novel framework, named NetSpam, which utilizes spam features for modeling review datasets as heterogeneous information networks to map spam detection procedure into a classification problem in such networks. Using the importance of spam features help us to obtain better results in terms of different metrics experimented on real-world review datasets from Yelp and Amazon websites. The results show that NetSpam outperforms the existing methods and among four categories of features; including review-behavioral, user-behavioral, reviewlinguistic, user-linguistic, the first type of features performs better than the other categories.