 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Recursive Transformers with Mixture of LoRAs
Dec 17, 2025



Parameter sharing in recursive transformers reduces model size but collapses layer-wise expressivity. We propose Mixture of LoRAs (MoL), a lightweight conditional-computation mechanism that inserts Low-Rank Adaptation (LoRA) experts inside a shared feed-forward network (FFN). MoL enables token-conditional weight-space modulation of the shared FFN without untying backbone parameters, unlike prior approaches that add fixed or externally attached adapters. We pretrain a modernised recursive architecture, ModernALBERT, integrating rotary embeddings, GeGLU, FlashAttention, and a distillation-based initialisation. Across GLUE, SQuAD-v2, and BEIR, ModernALBERT (50M--120M) achieves state-of-the-art performance among compact models and surpasses larger fully parameterised baselines. We also propose an expert-merging procedure that compresses MoL into a single adapter at inference while preserving accuracy, enabling efficient deployment. Our results show that conditional weight-space modulation effectively restores the expressivity lost under aggressive parameter sharing in recursive transformers.
Towards Scalable and Cross-Lingual Specialist Language Models for Oncology
Mar 11, 2025



Clinical oncology generates vast, unstructured data that often contain inconsistencies, missing information, and ambiguities, making it difficult to extract reliable insights for data-driven decision-making. General-purpose large language models (LLMs) struggle with these challenges due to their lack of domain-specific reasoning, including specialized clinical terminology, context-dependent interpretations, and multi-modal data integration. We address these issues with an oncology-specialized, efficient, and adaptable NLP framework that combines instruction tuning, retrieval-augmented generation (RAG), and graph-based knowledge integration. Our lightweight models prove effective at oncology-specific tasks, such as named entity recognition (e.g., identifying cancer diagnoses), entity linking (e.g., linking entities to standardized ontologies), TNM staging, document classification (e.g., cancer subtype classification from pathology reports), and treatment response prediction. Our framework emphasizes adaptability and resource efficiency. We include minimal German instructions, collected at the University Hospital Zurich (USZ), to test whether small amounts of non-English language data can effectively transfer knowledge across languages. This approach mirrors our motivation for lightweight models, which balance strong performance with reduced computational costs, making them suitable for resource-limited healthcare settings. We validated our models on oncology datasets, demonstrating strong results in named entity recognition, relation extraction, and document classification.
Uncertainty Modeling in Multimodal Speech Analysis Across the Psychosis Spectrum
Feb 25, 2025Capturing subtle speech disruptions across the psychosis spectrum is challenging because of the inherent variability in speech patterns. This variability reflects individual differences and the fluctuating nature of symptoms in both clinical and non-clinical populations. Accounting for uncertainty in speech data is essential for predicting symptom severity and improving diagnostic precision. Speech disruptions characteristic of psychosis appear across the spectrum, including in non-clinical individuals. We develop an uncertainty-aware model integrating acoustic and linguistic features to predict symptom severity and psychosis-related traits. Quantifying uncertainty in specific modalities allows the model to address speech variability, improving prediction accuracy. We analyzed speech data from 114 participants, including 32 individuals with early psychosis and 82 with low or high schizotypy, collected through structured interviews, semi-structured autobiographical tasks, and narrative-driven interactions in German. The model improved prediction accuracy, reducing RMSE and achieving an F1-score of 83% with ECE = 4.5e-2, showing robust performance across different interaction contexts. Uncertainty estimation improved model interpretability by identifying reliability differences in speech markers such as pitch variability, fluency disruptions, and spectral instability. The model dynamically adjusted to task structures, weighting acoustic features more in structured settings and linguistic features in unstructured contexts. This approach strengthens early detection, personalized assessment, and clinical decision-making in psychosis-spectrum research.
Radiology-Aware Model-Based Evaluation Metric for Report Generation
Nov 28, 2023We propose a new automated evaluation metric for machine-generated radiology reports using the successful COMET architecture adapted for the radiology domain. We train and publish four medically-oriented model checkpoints, including one trained on RadGraph, a radiology knowledge graph. Our results show that our metric correlates moderately to high with established metrics such as BERTscore, BLEU, and CheXbert scores. Furthermore, we demonstrate that one of our checkpoints exhibits a high correlation with human judgment, as assessed using the publicly available annotations of six board-certified radiologists, using a set of 200 reports. We also performed our own analysis gathering annotations with two radiologists on a collection of 100 reports. The results indicate the potential effectiveness of our method as a radiology-specific evaluation metric. The code, data, and model checkpoints to reproduce our findings will be publicly available.
Boosting Radiology Report Generation by Infusing Comparison Prior
May 08, 2023



Current transformer-based models achieved great success in generating radiology reports from chest X-ray images. Nonetheless, one of the major issues is the model's lack of prior knowledge, which frequently leads to false references to non-existent prior exams in synthetic reports. This is mainly due to the knowledge gap between radiologists and the generation models: radiologists are aware of the prior information of patients to write a medical report, while models only receive X-ray images at a specific time. To address this issue, we propose a novel approach that employs a labeler to extract comparison prior information from radiology reports in the IU X-ray and MIMIC-CXR datasets. This comparison prior is then incorporated into state-of-the-art transformer-based models, allowing them to generate more realistic and comprehensive reports. We test our method on the IU X-ray and MIMIC-CXR datasets and find that it outperforms previous state-of-the-art models in terms of both automatic and human evaluation metrics. In addition, unlike previous models, our model generates reports that do not contain false references to non-existent prior exams. Our approach provides a promising direction for bridging the gap between radiologists and generation models in medical report generation.
Privacy-aware Early Detection of COVID-19 through Adversarial Training
Jan 09, 2022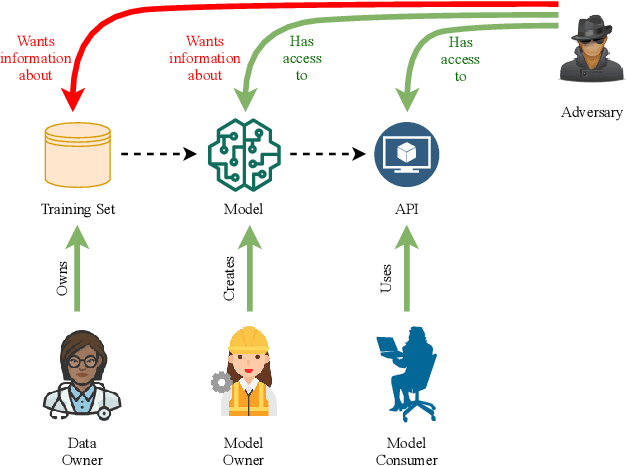
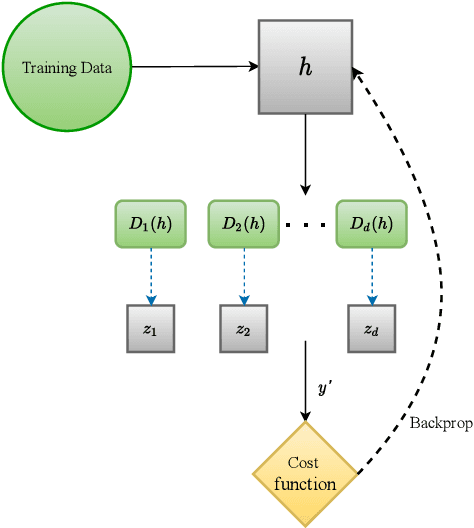

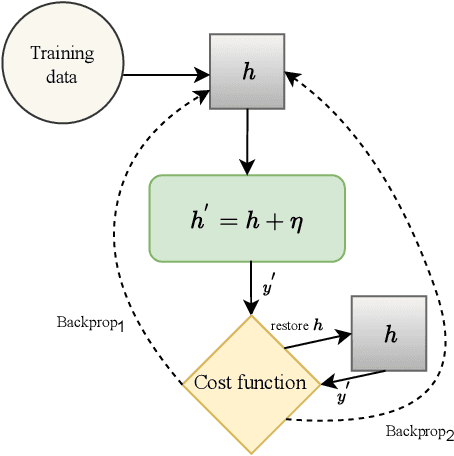
Early detection of COVID-19 is an ongoing area of research that can help with triage, monitoring and general health assessment of potential patients and may reduce operational strain on hospitals that cope with the coronavirus pandemic. Different machine learning techniques have been used in the literature to detect coronavirus using routine clinical data (blood tests, and vital signs). Data breaches and information leakage when using these models can bring reputational damage and cause legal issues for hospitals. In spite of this, protecting healthcare models against leakage of potentially sensitive information is an understudied research area. In this work, we examine two machine learning approaches, intended to predict a patient's COVID-19 status using routinely collected and readily available clinical data. We employ adversarial training to explore robust deep learning architectures that protect attributes related to demographic information about the patients. The two models we examine in this work are intended to preserve sensitive information against adversarial attacks and information leakage. In a series of experiments using datasets from the Oxford University Hospitals, Bedfordshire Hospitals NHS Foundation Trust, University Hospitals Birmingham NHS Foundation Trust, and Portsmouth Hospitals University NHS Trust we train and test two neural networks that predict PCR test results using information from basic laboratory blood tests, and vital signs performed on a patients' arrival to hospital. We assess the level of privacy each one of the models can provide and show the efficacy and robustness of our proposed architectures against a comparable baseline. One of our main contributions is that we specifically target the development of effective COVID-19 detection models with built-in mechanisms in order to selectively protect sensitive attributes against adversarial attacks.
Alzheimer's Dementia Recognition Using Acoustic, Lexical, Disfluency and Speech Pause Features Robust to Noisy Inputs
Jun 29, 2021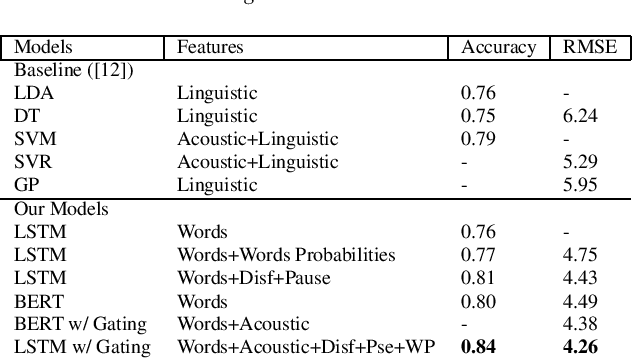

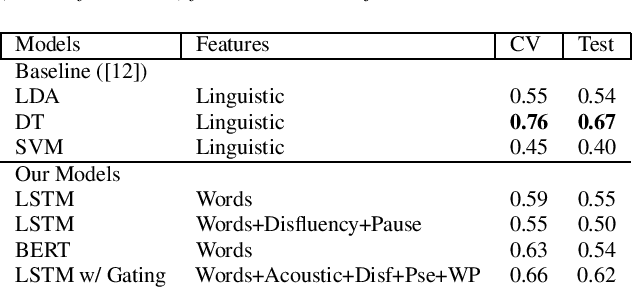
We present two multimodal fusion-based deep learning models that consume ASR transcribed speech and acoustic data simultaneously to classify whether a speaker in a structured diagnostic task has Alzheimer's Disease and to what degree, evaluating the ADReSSo challenge 2021 data. Our best model, a BiLSTM with highway layers using words, word probabilities, disfluency features, pause information, and a variety of acoustic features, achieves an accuracy of 84% and RSME error prediction of 4.26 on MMSE cognitive scores. While predicting cognitive decline is more challenging, our models show improvement using the multimodal approach and word probabilities, disfluency and pause information over word-only models. We show considerable gains for AD classification using multimodal fusion and gating, which can effectively deal with noisy inputs from acoustic features and ASR hypotheses.
Multi-modal fusion with gating using audio, lexical and disfluency features for Alzheimer's Dementia recognition from spontaneous speech
Jun 17, 2021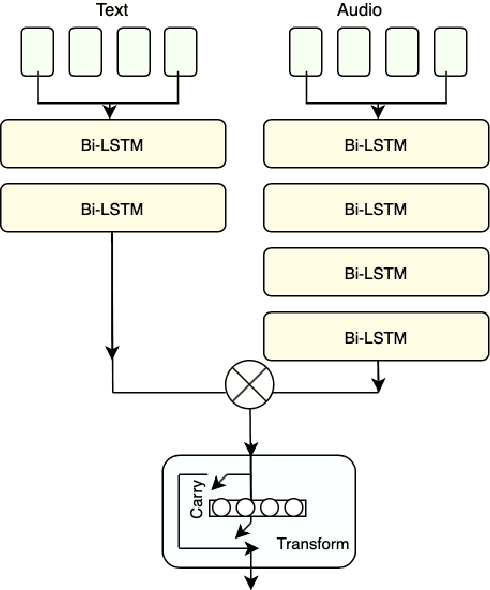

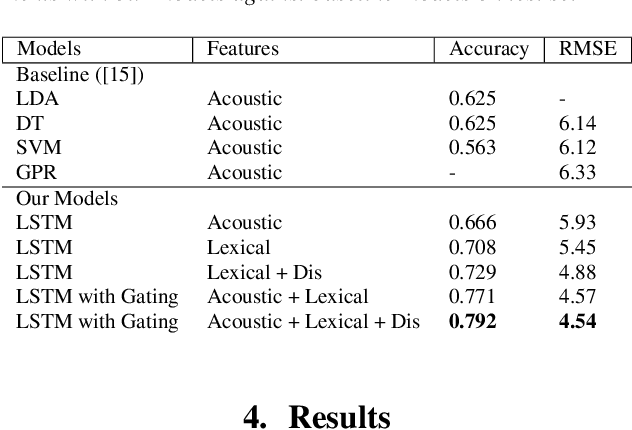
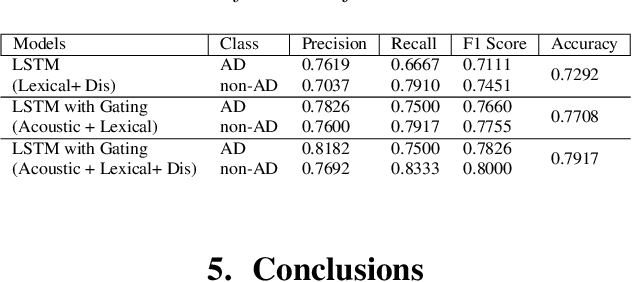
This paper is a submission to the Alzheimer's Dementia Recognition through Spontaneous Speech (ADReSS) challenge, which aims to develop methods that can assist in the automated prediction of severity of Alzheimer's Disease from speech data. We focus on acoustic and natural language features for cognitive impairment detection in spontaneous speech in the context of Alzheimer's Disease Diagnosis and the mini-mental state examination (MMSE) score prediction. We proposed a model that obtains unimodal decisions from different LSTMs, one for each modality of text and audio, and then combines them using a gating mechanism for the final prediction. We focused on sequential modelling of text and audio and investigated whether the disfluencies present in individuals' speech relate to the extent of their cognitive impairment. Our results show that the proposed classification and regression schemes obtain very promising results on both development and test sets. This suggests Alzheimer's Disease can be detected successfully with sequence modeling of the speech data of medical sessions.
Re-framing Incremental Deep Language Models for Dialogue Processing with Multi-task Learning
Nov 13, 2020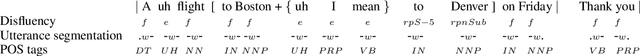
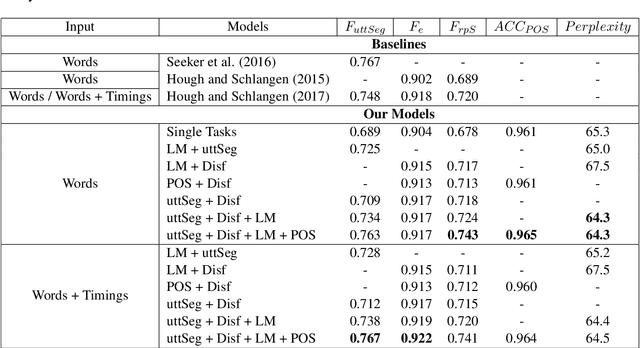
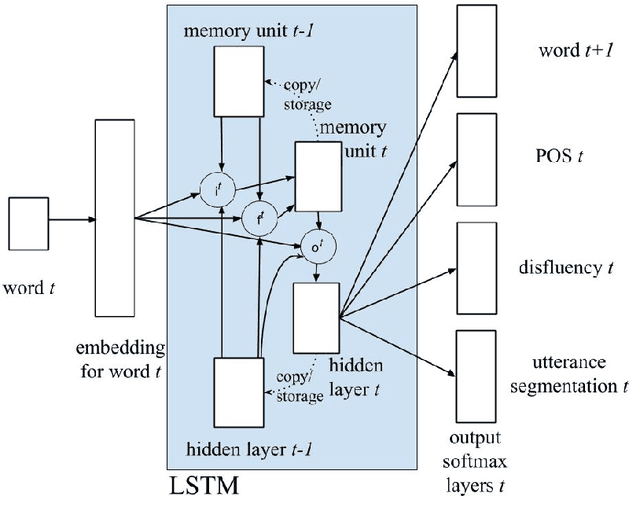
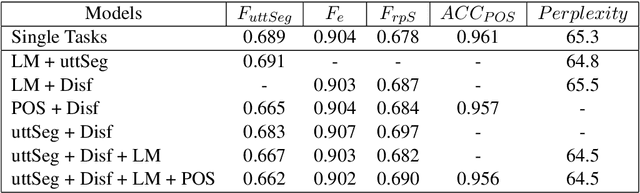
We present a multi-task learning framework to enable the training of one universal incremental dialogue processing model with four tasks of disfluency detection, language modelling, part-of-speech tagging, and utterance segmentation in a simple deep recurrent setting. We show that these tasks provide positive inductive biases to each other with the optimal contribution of each one relying on the severity of the noise from the task. Our live multi-task model outperforms similar individual tasks, delivers competitive performance, and is beneficial for future use in conversational agents in psychiatric treatment.
Convolutional Neural Networks for Sentiment Analysis in Persian Social Media
Feb 14, 2020With the social media engagement on the rise, the resulting data can be used as a rich resource for analyzing and understanding different phenomena around us. A sentiment analysis system employs these data to find the attitude of social media users towards certain entities in a given document. In this paper we propose a sentiment analysis method for Persian text using Convolutional Neural Network (CNN), a feedforward Artificial Neural Network, that categorize sentences into two and five classes (considering their intensity) by applying a layer of convolution over input data through different filters. We evaluated the method on three different datasets of Persian social media texts using Area under Curve metric. The final results show the advantage of using CNN over earlier attempts at developing traditional machine learning methods for Persian texts sentiment classification especially for short texts.