 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherence in the brain unfolds across separable temporal regimes
Dec 24, 2025Coherence in language requires the brain to satisfy two competing temporal demands: gradual accumulation of meaning across extended context and rapid reconfiguration of representations at event boundaries. Despite their centrality to language and thought, how these processes are implemented in the human brain during naturalistic listening remains unclear. Here, we tested whether these two processes can be captured by annotation-free drift and shift signals and whether their neural expression dissociates across large-scale cortical systems. These signals were derived from a large language model (LLM) and formalized contextual drift and event shifts directly from the narrative input. To enable high-precision voxelwise encoding models with stable parameter estimates, we densely sampled one healthy adult across more than 7 hours of listening to thirteen crime stories while collecting ultra high-field (7T) BOLD data. We then modeled the feature-informed hemodynamic response using a regularized encoding framework validated on independent stories. Drift predictions were prevalent in default-mode network hubs, whereas shift predictions were evident bilaterally in the primary auditory cortex and language association cortex. Furthermore, activity in default-mode and parietal networks was best explained by a signal capturing how meaning accumulates and gradually fades over the course of the narrative. Together, these findings show that coherence during language comprehension is implemented through dissociable neural regimes of slow contextual integration and rapid event-driven reconfiguration, offering a mechanistic entry point for understanding disturbances of language coherence in psychiatric disorders.
Standardising the NLP Workflow: A Framework for Reproducible Linguistic Analysis
Nov 19, 2025The introduction of large language models and other influential developments in AI-based language processing have led to an evolution in the methods available to quantitatively analyse language data. With the resultant growth of attention on language processing, significant challenges have emerged, including the lack of standardisation in organising and sharing linguistic data and the absence of standardised and reproducible processing methodologies. Striving for future standardisation, we first propose the Language Processing Data Structure (LPDS), a data structure inspired by the Brain Imaging Data Structure (BIDS), a widely adopted standard for handling neuroscience data. It provides a folder structure and file naming conventions for linguistic research. Second, we introduce pelican nlp, a modular and extensible Python package designed to enable streamlined language processing, from initial data cleaning and task-specific preprocessing to the extraction of sophisticated linguistic and acoustic features, such as semantic embeddings and prosodic metrics. The entire processing workflow can be specified within a single, shareable configuration file, which pelican nlp then executes on LPDS-formatted data. Depending on the specifications, the reproducible output can consist of preprocessed language data or standardised extraction of both linguistic and acoustic features and corresponding result aggregations. LPDS and pelican nlp collectively offer an end-to-end processing pipeline for linguistic data, designed to ensure methodological transparency and enhance reproducibility.
Uncertainty Modeling in Multimodal Speech Analysis Across the Psychosis Spectrum
Feb 25, 2025Capturing subtle speech disruptions across the psychosis spectrum is challenging because of the inherent variability in speech patterns. This variability reflects individual differences and the fluctuating nature of symptoms in both clinical and non-clinical populations. Accounting for uncertainty in speech data is essential for predicting symptom severity and improving diagnostic precision. Speech disruptions characteristic of psychosis appear across the spectrum, including in non-clinical individuals. We develop an uncertainty-aware model integrating acoustic and linguistic features to predict symptom severity and psychosis-related traits. Quantifying uncertainty in specific modalities allows the model to address speech variability, improving prediction accuracy. We analyzed speech data from 114 participants, including 32 individuals with early psychosis and 82 with low or high schizotypy, collected through structured interviews, semi-structured autobiographical tasks, and narrative-driven interactions in German. The model improved prediction accuracy, reducing RMSE and achieving an F1-score of 83% with ECE = 4.5e-2, showing robust performance across different interaction contexts. Uncertainty estimation improved model interpretability by identifying reliability differences in speech markers such as pitch variability, fluency disruptions, and spectral instability. The model dynamically adjusted to task structures, weighting acoustic features more in structured settings and linguistic features in unstructured contexts. This approach strengthens early detection, personalized assessment, and clinical decision-making in psychosis-spectrum research.
belabBERT: a Dutch RoBERTa-based language model applied to psychiatric classification
Jun 02, 2021


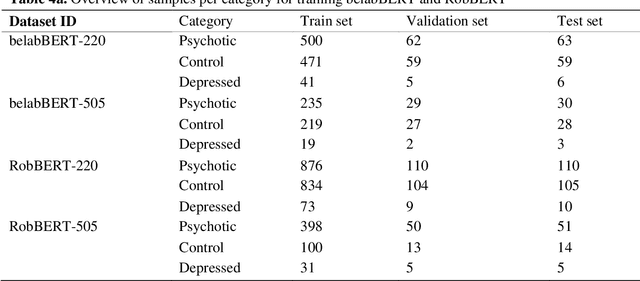
Natural language processing (NLP) is becoming an important means for automatic recognition of human traits and states, such as intoxication, presence of psychiatric disorders, presence of airway disorders and states of stress. Such applications have the potential to be an important pillar for online help lines, and may gradually be introduced into eHealth modules. However, NLP is language specific and for languages such as Dutch, NLP models are scarce. As a result, recent Dutch NLP models have a low capture of long range semantic dependencies over sentences. To overcome this, here we present belabBERT, a new Dutch language model extending the RoBERTa architecture. belabBERT is trained on a large Dutch corpus (+32 GB) of web crawled texts. We applied belabBERT to the classification of psychiatric illnesses. First, we evaluated the strength of text-based classification using belabBERT, and compared the results to the existing RobBERT model. Then, we compared the performance of belabBERT to audio classification for psychiatric disorders. Finally, a brief exploration was performed, extending the framework to a hybrid text- and audio-based classification. Our results show that belabBERT outperformed the current best text classification network for Dutch, RobBERT. belabBERT also outperformed classification based on audio alone.