 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Protein Language Models for Latent Flow-Based Fitness Optimization
Feb 02, 2026Protein fitness optimization is challenged by a vast combinatorial landscape where high-fitness variants are extremely sparse. Many current methods either underperform or require computationally expensive gradient-based sampling. We present CHASE, a framework that repurposes the evolutionary knowledge of pretrained protein language models by compressing their embeddings into a compact latent space. By training a conditional flow-matching model with classifier-free guidance, we enable the direct generation of high-fitness variants without predictor-based guidance during the ODE sampling steps. CHASE achieves state-of-the-art performance on AAV and GFP protein design benchmarks. Finally, we show that bootstrapping with synthetic data can further enhance performance in data-constrained settings.
Enhancing Radiology Report Generation and Visual Grounding using Reinforcement Learning
Dec 11, 2025Recent advances in vision-language models (VLMs) have improved Chest X-ray (CXR) interpretation in multiple aspects. However, many medical VLMs rely solely on supervised fine-tuning (SFT), which optimizes next-token prediction without evaluating answer quality. In contrast, reinforcement learning (RL) can incorporate task-specific feedback, and its combination with explicit intermediate reasoning ("thinking") has demonstrated substantial gains on verifiable math and coding tasks. To investigate the effects of RL and thinking in a CXR VLM, we perform large-scale SFT on CXR data to build an updated RadVLM based on Qwen3-VL, followed by a cold-start SFT stage that equips the model with basic thinking ability. We then apply Group Relative Policy Optimization (GRPO) with clinically grounded, task-specific rewards for report generation and visual grounding, and run matched RL experiments on both domain-specific and general-domain Qwen3-VL variants, with and without thinking. Across these settings, we find that while strong SFT remains crucial for high base performance, RL provides additional gains on both tasks, whereas explicit thinking does not appear to further improve results. Under a unified evaluation pipeline, the RL-optimized RadVLM models outperform their baseline counterparts and reach state-of-the-art performance on both report generation and grounding, highlighting clinically aligned RL as a powerful complement to SFT for medical VLMs.
Agentic Systems in Radiology: Design, Applications, Evaluation, and Challenges
Oct 10, 2025Building agents, systems that perceive and act upon their environment with a degree of autonomy, has long been a focus of AI research. This pursuit has recently become vastly more practical with the emergence of large language models (LLMs) capable of using natural language to integrate information, follow instructions, and perform forms of "reasoning" and planning across a wide range of tasks. With its multimodal data streams and orchestrated workflows spanning multiple systems, radiology is uniquely suited to benefit from agents that can adapt to context and automate repetitive yet complex tasks. In radiology, LLMs and their multimodal variants have already demonstrated promising performance for individual tasks such as information extraction and report summarization. However, using LLMs in isolation underutilizes their potential to support complex, multi-step workflows where decisions depend on evolving context from multiple information sources. Equipping LLMs with external tools and feedback mechanisms enables them to drive systems that exhibit a spectrum of autonomy, ranging from semi-automated workflows to more adaptive agents capable of managing complex processes. This review examines the design of such LLM-driven agentic systems, highlights key applications, discusses evaluation methods for planning and tool use, and outlines challenges such as error cascades, tool-use efficiency, and health IT integration.
Towards Scalable and Cross-Lingual Specialist Language Models for Oncology
Mar 11, 2025



Clinical oncology generates vast, unstructured data that often contain inconsistencies, missing information, and ambiguities, making it difficult to extract reliable insights for data-driven decision-making. General-purpose large language models (LLMs) struggle with these challenges due to their lack of domain-specific reasoning, including specialized clinical terminology, context-dependent interpretations, and multi-modal data integration. We address these issues with an oncology-specialized, efficient, and adaptable NLP framework that combines instruction tuning, retrieval-augmented generation (RAG), and graph-based knowledge integration. Our lightweight models prove effective at oncology-specific tasks, such as named entity recognition (e.g., identifying cancer diagnoses), entity linking (e.g., linking entities to standardized ontologies), TNM staging, document classification (e.g., cancer subtype classification from pathology reports), and treatment response prediction. Our framework emphasizes adaptability and resource efficiency. We include minimal German instructions, collected at the University Hospital Zurich (USZ), to test whether small amounts of non-English language data can effectively transfer knowledge across languages. This approach mirrors our motivation for lightweight models, which balance strong performance with reduced computational costs, making them suitable for resource-limited healthcare settings. We validated our models on oncology datasets, demonstrating strong results in named entity recognition, relation extraction, and document classification.
Uncertainty Modeling in Multimodal Speech Analysis Across the Psychosis Spectrum
Feb 25, 2025Capturing subtle speech disruptions across the psychosis spectrum is challenging because of the inherent variability in speech patterns. This variability reflects individual differences and the fluctuating nature of symptoms in both clinical and non-clinical populations. Accounting for uncertainty in speech data is essential for predicting symptom severity and improving diagnostic precision. Speech disruptions characteristic of psychosis appear across the spectrum, including in non-clinical individuals. We develop an uncertainty-aware model integrating acoustic and linguistic features to predict symptom severity and psychosis-related traits. Quantifying uncertainty in specific modalities allows the model to address speech variability, improving prediction accuracy. We analyzed speech data from 114 participants, including 32 individuals with early psychosis and 82 with low or high schizotypy, collected through structured interviews, semi-structured autobiographical tasks, and narrative-driven interactions in German. The model improved prediction accuracy, reducing RMSE and achieving an F1-score of 83% with ECE = 4.5e-2, showing robust performance across different interaction contexts. Uncertainty estimation improved model interpretability by identifying reliability differences in speech markers such as pitch variability, fluency disruptions, and spectral instability. The model dynamically adjusted to task structures, weighting acoustic features more in structured settings and linguistic features in unstructured contexts. This approach strengthens early detection, personalized assessment, and clinical decision-making in psychosis-spectrum research.
RadVLM: A Multitask Conversational Vision-Language Model for Radiology
Feb 05, 2025



The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks -- such as report generation, abnormality classification, and visual grounding -- and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.
A Variational Perspective on Generative Protein Fitness Optimization
Jan 31, 2025



The goal of protein fitness optimization is to discover new protein variants with enhanced fitness for a given use. The vast search space and the sparsely populated fitness landscape, along with the discrete nature of protein sequences, pose significant challenges when trying to determine the gradient towards configurations with higher fitness. We introduce Variational Latent Generative Protein Optimization (VLGPO), a variational perspective on fitness optimization. Our method embeds protein sequences in a continuous latent space to enable efficient sampling from the fitness distribution and combines a (learned) flow matching prior over sequence mutations with a fitness predictor to guide optimization towards sequences with high fitness. VLGPO achieves state-of-the-art results on two different protein benchmarks of varying complexity. Moreover, the variational design with explicit prior and likelihood functions offers a flexible plug-and-play framework that can be easily customized to suit various protein design tasks.
TAMER: A Test-Time Adaptive MoE-Driven Framework for EHR Representation Learning
Jan 10, 2025



We propose TAMER, a Test-time Adaptive MoE-driven framework for EHR Representation learning. TAMER combines a Mixture-of-Experts (MoE) with Test-Time Adaptation (TTA) to address two critical challenges in EHR modeling: patient population heterogeneity and distribution shifts. The MoE component handles diverse patient subgroups, while TTA enables real-time adaptation to evolving health status distributions when new patient samples are introduced. Extensive experiments across four real-world EHR datasets demonstrate that TAMER consistently improves predictive performance for both mortality and readmission risk tasks when combined with diverse EHR modeling backbones. TAMER offers a promising approach for dynamic and personalized EHR-based predictions in practical clinical settings. Code is publicly available at https://github.com/yhzhu99/TAMER.
Learning Personalized Treatment Decisions in Precision Medicine: Disentangling Treatment Assignment Bias in Counterfactual Outcome Prediction and Biomarker Identification
Oct 01, 2024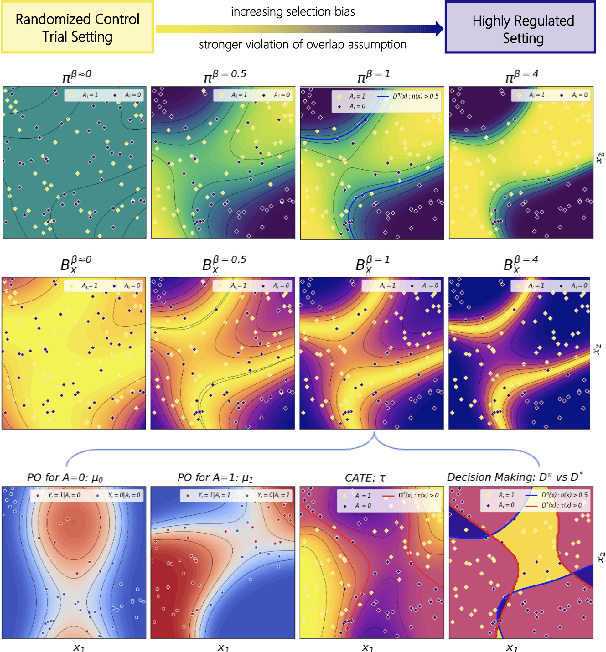
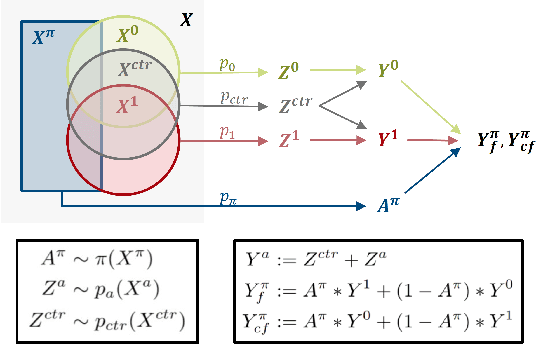
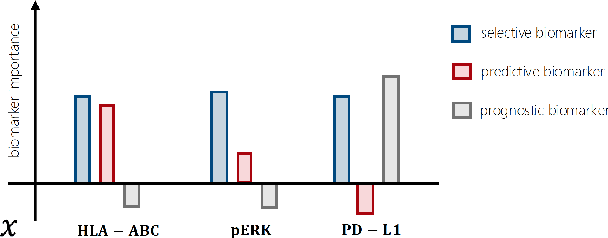
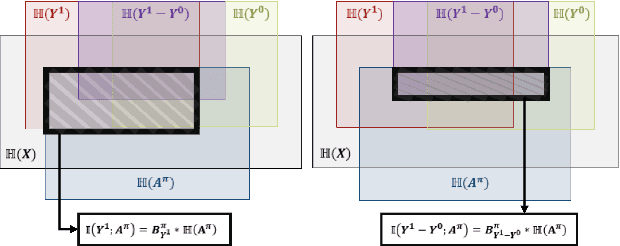
Precision medicine offers the potential to tailor treatment decisions to individual patients, yet it faces significant challenges due to the complex biases in clinical observational data and the high-dimensional nature of biological data. This study models various types of treatment assignment biases using mutual information and investigates their impact on machine learning (ML) models for counterfactual prediction and biomarker identification. Unlike traditional counterfactual benchmarks that rely on fixed treatment policies, our work focuses on modeling different characteristics of the underlying observational treatment policy in distinct clinical settings. We validate our approach through experiments on toy datasets, semi-synthetic tumor cancer genome atlas (TCGA) data, and real-world biological outcomes from drug and CRISPR screens. By incorporating empirical biological mechanisms, we create a more realistic benchmark that reflects the complexities of real-world data. Our analysis reveals that different biases lead to varying model performances, with some biases, especially those unrelated to outcome mechanisms, having minimal effect on prediction accuracy. This highlights the crucial need to account for specific biases in clinical observational data in counterfactual ML model development, ultimately enhancing the personalization of treatment decisions in precision medicine.
Semi-Supervised Generative Models for Disease Trajectories: A Case Study on Systemic Sclerosis
Jul 16, 2024We propose a deep generative approach using latent temporal processes for modeling and holistically analyzing complex disease trajectories, with a particular focus on Systemic Sclerosis (SSc). We aim to learn temporal latent representations of the underlying generative process that explain the observed patient disease trajectories in an interpretable and comprehensive way. To enhance the interpretability of these latent temporal processes, we develop a semi-supervised approach for disentangling the latent space using established medical knowledge. By combining the generative approach with medical definitions of different characteristics of SSc, we facilitate the discovery of new aspects of the disease. We show that the learned temporal latent processes can be utilized for further data analysis and clinical hypothesis testing, including finding similar patients and clustering SSc patient trajectories into novel sub-types. Moreover, our method enables personalized online monitoring and prediction of multivariate time series with uncertainty quantification.