 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Personalized Treatment Decisions in Precision Medicine: Disentangling Treatment Assignment Bias in Counterfactual Outcome Prediction and Biomarker Identification
Paper and Code
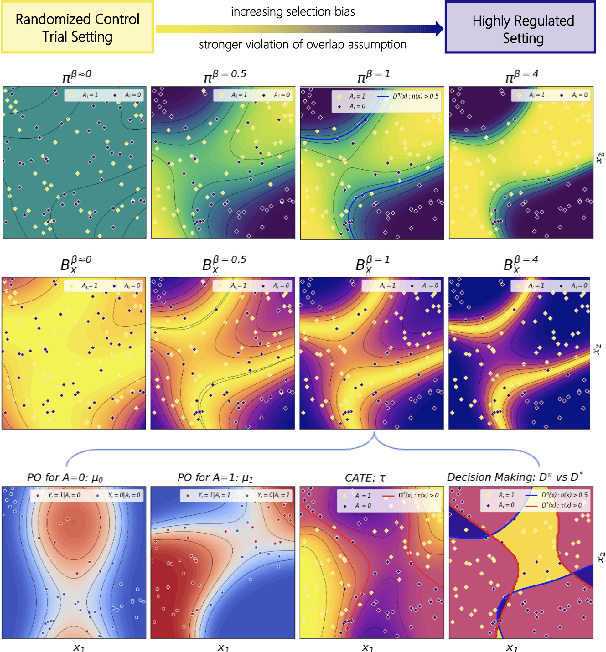
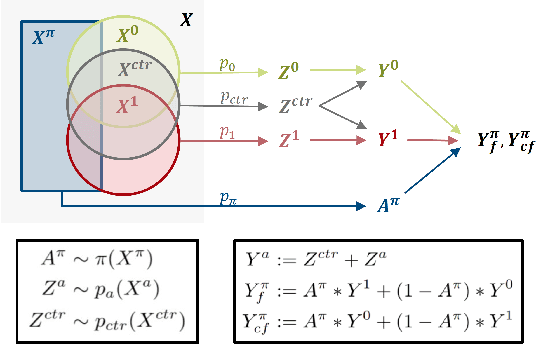
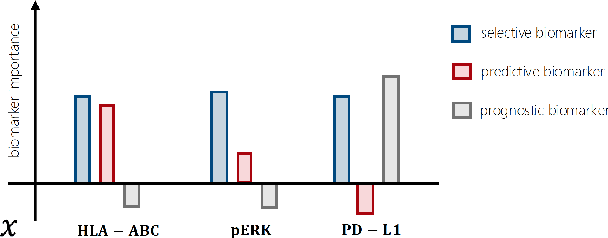
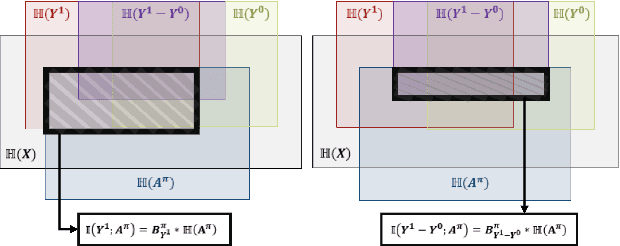
Precision medicine offers the potential to tailor treatment decisions to individual patients, yet it faces significant challenges due to the complex biases in clinical observational data and the high-dimensional nature of biological data. This study models various types of treatment assignment biases using mutual information and investigates their impact on machine learning (ML) models for counterfactual prediction and biomarker identification. Unlike traditional counterfactual benchmarks that rely on fixed treatment policies, our work focuses on modeling different characteristics of the underlying observational treatment policy in distinct clinical settings. We validate our approach through experiments on toy datasets, semi-synthetic tumor cancer genome atlas (TCGA) data, and real-world biological outcomes from drug and CRISPR screens. By incorporating empirical biological mechanisms, we create a more realistic benchmark that reflects the complexities of real-world data. Our analysis reveals that different biases lead to varying model performances, with some biases, especially those unrelated to outcome mechanisms, having minimal effect on prediction accuracy. This highlights the crucial need to account for specific biases in clinical observational data in counterfactual ML model development, ultimately enhancing the personalization of treatment decisions in precision medicine.