 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation for Trust Attribution to Speed-of-Sound Reconstruction with Variational Networks
Apr 15, 2025Speed-of-sound (SoS) is a biomechanical characteristic of tissue, and its imaging can provide a promising biomarker for diagnosis. Reconstructing SoS images from ultrasound acquisitions can be cast as a limited-angle computed-tomography problem, with Variational Networks being a promising model-based deep learning solution. Some acquired data frames may, however, get corrupted by noise due to, e.g., motion, lack of contact, and acoustic shadows, which in turn negatively affects the resulting SoS reconstructions. We propose to use the uncertainty in SoS reconstructions to attribute trust to each individual acquired frame. Given multiple acquisitions, we then use an uncertainty based automatic selection among these retrospectively, to improve diagnostic decisions. We investigate uncertainty estimation based on Monte Carlo Dropout and Bayesian Variational Inference. We assess our automatic frame selection method for differential diagnosis of breast cancer, distinguishing between benign fibroadenoma and malignant carcinoma. We evaluate 21 lesions classified as BI-RADS~4, which represents suspicious cases for probable malignancy. The most trustworthy frame among four acquisitions of each lesion was identified using uncertainty based criteria. Selecting a frame informed by uncertainty achieved an area under curve of 76% and 80% for Monte Carlo Dropout and Bayesian Variational Inference, respectively, superior to any uncertainty-uninformed baselines with the best one achieving 64%. A novel use of uncertainty estimation is proposed for selecting one of multiple data acquisitions for further processing and decision making.
Measuring Leakage in Concept-Based Methods: An Information Theoretic Approach
Apr 13, 2025Concept Bottleneck Models (CBMs) aim to enhance interpretability by structuring predictions around human-understandable concepts. However, unintended information leakage, where predictive signals bypass the concept bottleneck, compromises their transparency. This paper introduces an information-theoretic measure to quantify leakage in CBMs, capturing the extent to which concept embeddings encode additional, unintended information beyond the specified concepts. We validate the measure through controlled synthetic experiments, demonstrating its effectiveness in detecting leakage trends across various configurations. Our findings highlight that feature and concept dimensionality significantly influence leakage, and that classifier choice impacts measurement stability, with XGBoost emerging as the most reliable estimator. Additionally, preliminary investigations indicate that the measure exhibits the anticipated behavior when applied to soft joint CBMs, suggesting its reliability in leakage quantification beyond fully synthetic settings. While this study rigorously evaluates the measure in controlled synthetic experiments, future work can extend its application to real-world datasets.
Text To 3D Object Generation For Scalable Room Assembly
Apr 12, 2025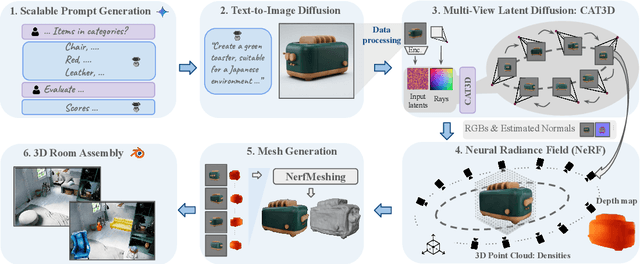



Modern machine learning models for scene understanding, such as depth estimation and object tracking, rely on large, high-quality datasets that mimic real-world deployment scenarios. To address data scarcity, we propose an end-to-end system for synthetic data generation for scalable, high-quality, and customizable 3D indoor scenes. By integrating and adapting text-to-image and multi-view diffusion models with Neural Radiance Field-based meshing, this system generates highfidelity 3D object assets from text prompts and incorporates them into pre-defined floor plans using a rendering tool. By introducing novel loss functions and training strategies into existing methods, the system supports on-demand scene generation, aiming to alleviate the scarcity of current available data, generally manually crafted by artists. This system advances the role of synthetic data in addressing machine learning training limitations, enabling more robust and generalizable models for real-world applications.
Beyond Glucose-Only Assessment: Advancing Nocturnal Hypoglycemia Prediction in Children with Type 1 Diabetes
Apr 12, 2025The dead-in-bed syndrome describes the sudden and unexplained death of young individuals with Type 1 Diabetes (T1D) without prior long-term complications. One leading hypothesis attributes this phenomenon to nocturnal hypoglycemia (NH), a dangerous drop in blood glucose during sleep. This study aims to improve NH prediction in children with T1D by leveraging physiological data and machine learning (ML) techniques. We analyze an in-house dataset collected from 16 children with T1D, integrating physiological metrics from wearable sensors. We explore predictive performance through feature engineering, model selection, architectures, and oversampling. To address data limitations, we apply transfer learning from a publicly available adult dataset. Our results achieve an AUROC of 0.75 +- 0.21 on the in-house dataset, further improving to 0.78 +- 0.05 with transfer learning. This research moves beyond glucose-only predictions by incorporating physiological parameters, showcasing the potential of ML to enhance NH detection and improve clinical decision-making for pediatric diabetes management.
RadVLM: A Multitask Conversational Vision-Language Model for Radiology
Feb 05, 2025



The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks -- such as report generation, abnormality classification, and visual grounding -- and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.
Automatic Classification of General Movements in Newborns
Nov 14, 2024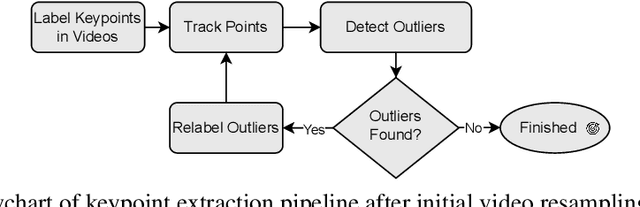
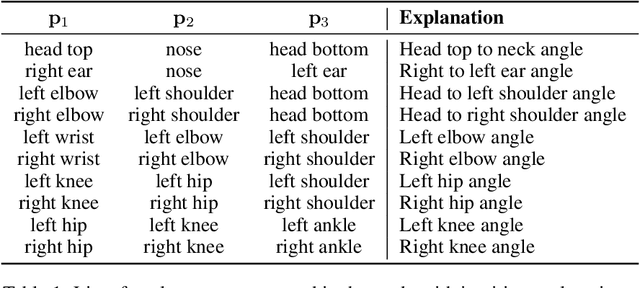

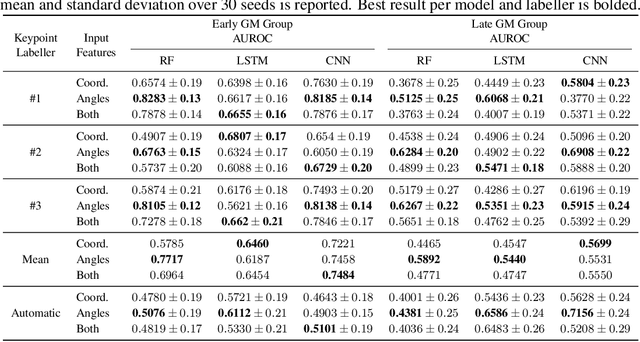
General movements (GMs) are spontaneous, coordinated body movements in infants that offer valuable insights into the developing nervous system. Assessed through the Prechtl GM Assessment (GMA), GMs are reliable predictors for neurodevelopmental disorders. However, GMA requires specifically trained clinicians, who are limited in number. To scale up newborn screening, there is a need for an algorithm that can automatically classify GMs from infant video recordings. This data poses challenges, including variability in recording length, device type, and setting, with each video coarsely annotated for overall movement quality. In this work, we introduce a tool for extracting features from these recordings and explore various machine learning techniques for automated GM classification.
Exploiting Interpretable Capabilities with Concept-Enhanced Diffusion and Prototype Networks
Oct 24, 2024Concept-based machine learning methods have increasingly gained importance due to the growing interest in making neural networks interpretable. However, concept annotations are generally challenging to obtain, making it crucial to leverage all their prior knowledge. By creating concept-enriched models that incorporate concept information into existing architectures, we exploit their interpretable capabilities to the fullest extent. In particular, we propose Concept-Guided Conditional Diffusion, which can generate visual representations of concepts, and Concept-Guided Prototype Networks, which can create a concept prototype dataset and leverage it to perform interpretable concept prediction. These results open up new lines of research by exploiting pre-existing information in the quest for rendering machine learning more human-understandable.
Stochastic Concept Bottleneck Models
Jun 27, 2024



Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Beyond Concept Bottleneck Models: How to Make Black Boxes Intervenable?
Jan 24, 2024Recently, interpretable machine learning has re-explored concept bottleneck models (CBM), comprising step-by-step prediction of the high-level concepts from the raw features and the target variable from the predicted concepts. A compelling advantage of this model class is the user's ability to intervene on the predicted concept values, affecting the model's downstream output. In this work, we introduce a method to perform such concept-based interventions on already-trained neural networks, which are not interpretable by design, given an annotated validation set. Furthermore, we formalise the model's intervenability as a measure of the effectiveness of concept-based interventions and leverage this definition to fine-tune black-box models. Empirically, we explore the intervenability of black-box classifiers on synthetic tabular and natural image benchmarks. We demonstrate that fine-tuning improves intervention effectiveness and often yields better-calibrated predictions. To showcase the practical utility of the proposed techniques, we apply them to deep chest X-ray classifiers and show that fine-tuned black boxes can be as intervenable and more performant than CBMs.
Accurate super-resolution low-field brain MRI
Feb 07, 2022The recent introduction of portable, low-field MRI (LF-MRI) into the clinical setting has the potential to transform neuroimaging. However, LF-MRI is limited by lower resolution and signal-to-noise ratio, leading to incomplete characterization of brain regions. To address this challenge, recent advances in machine learning facilitate the synthesis of higher resolution images derived from one or multiple lower resolution scans. Here, we report the extension of a machine learning super-resolution (SR) algorithm to synthesize 1 mm isotropic MPRAGE-like scans from LF-MRI T1-weighted and T2-weighted sequences. Our initial results on a paired dataset of LF and high-field (HF, 1.5T-3T) clinical scans show that: (i) application of available automated segmentation tools directly to LF-MRI images falters; but (ii) segmentation tools succeed when applied to SR images with high correlation to gold standard measurements from HF-MRI (e.g., r = 0.85 for hippocampal volume, r = 0.84 for the thalamus, r = 0.92 for the whole cerebrum). This work demonstrates proof-of-principle post-processing image enhancement from lower resolution LF-MRI sequences. These results lay the foundation for future work to enhance the detection of normal and abnormal image findings at LF and ultimately improve the diagnostic performance of LF-MRI. Our tools are publicly available on FreeSurfer (surfer.nmr.mgh.harvard.edu/).