 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText To 3D Object Generation For Scalable Room Assembly
Apr 12, 2025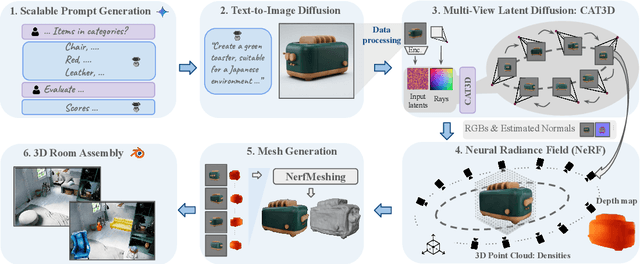



Modern machine learning models for scene understanding, such as depth estimation and object tracking, rely on large, high-quality datasets that mimic real-world deployment scenarios. To address data scarcity, we propose an end-to-end system for synthetic data generation for scalable, high-quality, and customizable 3D indoor scenes. By integrating and adapting text-to-image and multi-view diffusion models with Neural Radiance Field-based meshing, this system generates highfidelity 3D object assets from text prompts and incorporates them into pre-defined floor plans using a rendering tool. By introducing novel loss functions and training strategies into existing methods, the system supports on-demand scene generation, aiming to alleviate the scarcity of current available data, generally manually crafted by artists. This system advances the role of synthetic data in addressing machine learning training limitations, enabling more robust and generalizable models for real-world applications.
UnrealROX+: An Improved Tool for Acquiring Synthetic Data from Virtual 3D Environments
Apr 23, 2021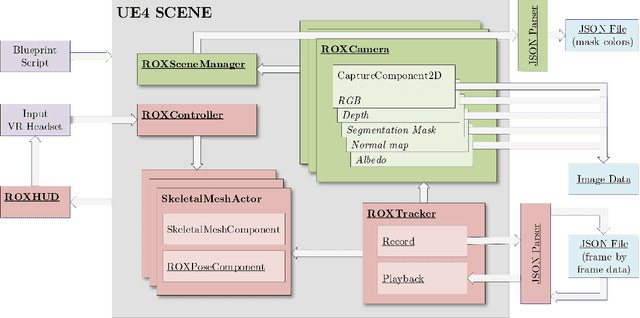



Synthetic data generation has become essential in last years for feeding data-driven algorithms, which surpassed traditional techniques performance in almost every computer vision problem. Gathering and labelling the amount of data needed for these data-hungry models in the real world may become unfeasible and error-prone, while synthetic data give us the possibility of generating huge amounts of data with pixel-perfect annotations. However, most synthetic datasets lack from enough realism in their rendered images. In that context UnrealROX generation tool was presented in 2019, allowing to generate highly realistic data, at high resolutions and framerates, with an efficient pipeline based on Unreal Engine, a cutting-edge videogame engine. UnrealROX enabled robotic vision researchers to generate realistic and visually plausible data with full ground truth for a wide variety of problems such as class and instance semantic segmentation, object detection, depth estimation, visual grasping, and navigation. Nevertheless, its workflow was very tied to generate image sequences from a robotic on-board camera, making hard to generate data for other purposes. In this work, we present UnrealROX+, an improved version of UnrealROX where its decoupled and easy-to-use data acquisition system allows to quickly design and generate data in a much more flexible and customizable way. Moreover, it is packaged as an Unreal plug-in, which makes it more comfortable to use with already existing Unreal projects, and it also includes new features such as generating albedo or a Python API for interacting with the virtual environment from Deep Learning frameworks.
H-GAN: the power of GANs in your Hands
Apr 21, 2021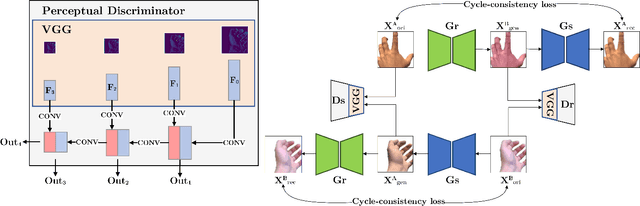
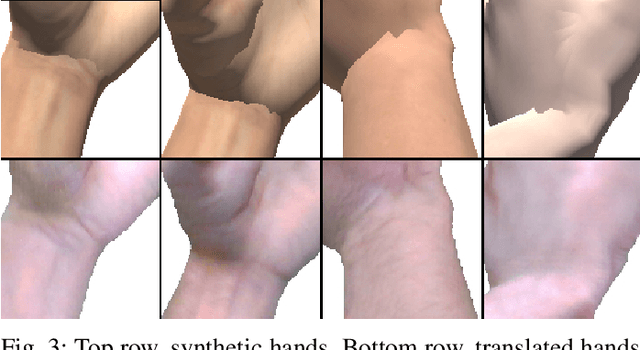
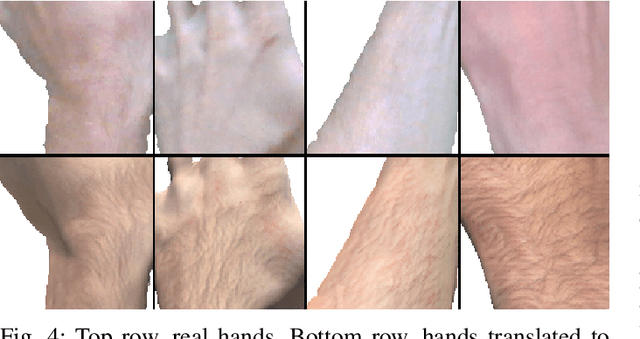
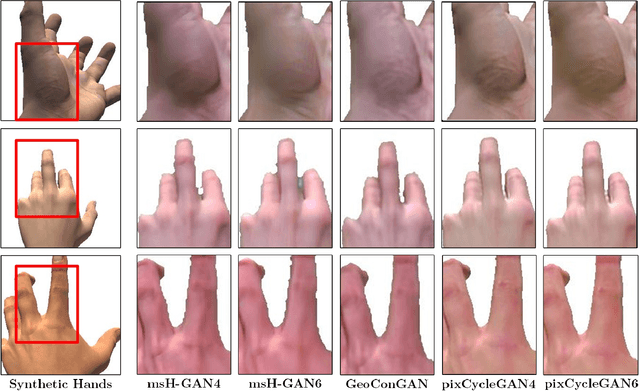
We present HandGAN (H-GAN), a cycle-consistent adversarial learning approach implementing multi-scale perceptual discriminators. It is designed to translate synthetic images of hands to the real domain. Synthetic hands provide complete ground-truth annotations, yet they are not representative of the target distribution of real-world data. We strive to provide the perfect blend of a realistic hand appearance with synthetic annotations. Relying on image-to-image translation, we improve the appearance of synthetic hands to approximate the statistical distribution underlying a collection of real images of hands. H-GAN tackles not only the cross-domain tone mapping but also structural differences in localized areas such as shading discontinuities. Results are evaluated on a qualitative and quantitative basis improving previous works. Furthermore, we relied on the hand classification task to claim our generated hands are statistically similar to the real domain of hands.
A Review on Deep Learning Techniques for Video Prediction
Apr 15, 2020

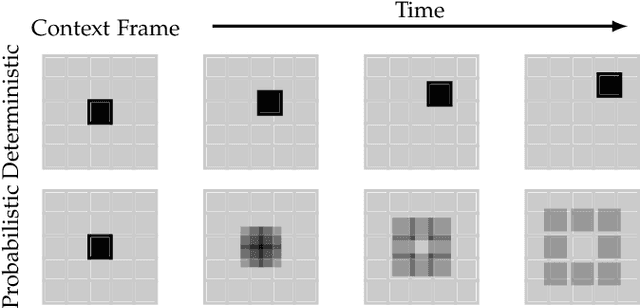
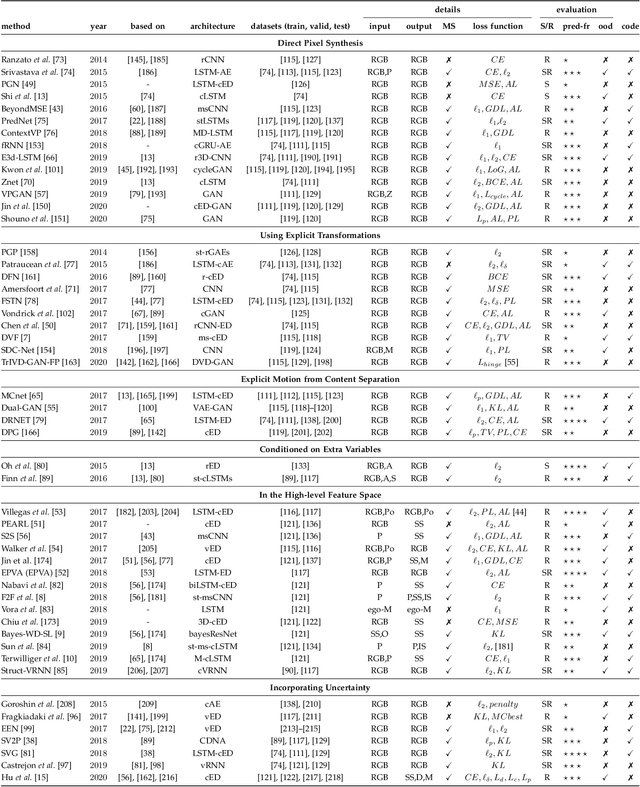
The ability to predict, anticipate and reason about future outcomes is a key component of intelligent decision-making systems. In light of the success of deep learning in computer vision, deep-learning-based video prediction emerged as a promising research direction. Defined as a self-supervised learning task, video prediction represents a suitable framework for representation learning, as it demonstrated potential capabilities for extracting meaningful representations of the underlying patterns in natural videos. Motivated by the increasing interest in this task, we provide a review on the deep learning methods for prediction in video sequences. We firstly define the video prediction fundamentals, as well as mandatory background concepts and the most used datasets. Next, we carefully analyze existing video prediction models organized according to a proposed taxonomy, highlighting their contributions and their significance in the field. The summary of the datasets and methods is accompanied with experimental results that facilitate the assessment of the state of the art on a quantitative basis. The paper is summarized by drawing some general conclusions, identifying open research challenges and by pointing out future research directions.
A Visually Plausible Grasping System for Object Manipulation and Interaction in Virtual Reality Environments
Mar 12, 2019
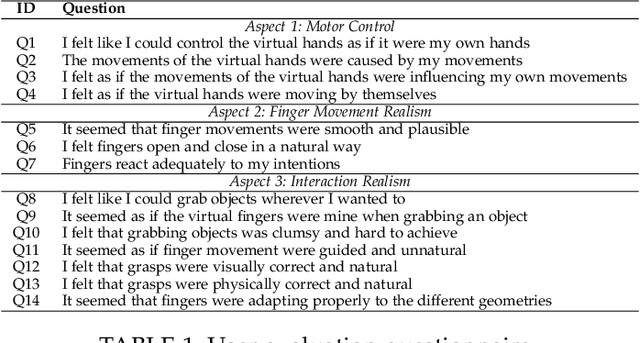


Interaction in virtual reality (VR) environments is essential to achieve a pleasant and immersive experience. Most of the currently existing VR applications, lack of robust object grasping and manipulation, which are the cornerstone of interactive systems. Therefore, we propose a realistic, flexible and robust grasping system that enables rich and real-time interactions in virtual environments. It is visually realistic because it is completely user-controlled, flexible because it can be used for different hand configurations, and robust because it allows the manipulation of objects regardless their geometry, i.e. hand is automatically fitted to the object shape. In order to validate our proposal, an exhaustive qualitative and quantitative performance analysis has been carried out. On the one hand, qualitative evaluation was used in the assessment of the abstract aspects such as: hand movement realism, interaction realism and motor control. On the other hand, for the quantitative evaluation a novel error metric has been proposed to visually analyze the performed grips. This metric is based on the computation of the distance from the finger phalanges to the nearest contact point on the object surface. These contact points can be used with different application purposes, mainly in the field of robotics. As a conclusion, system evaluation reports a similar performance between users with previous experience in virtual reality applications and inexperienced users, referring to a steep learning curve.
The RobotriX: An eXtremely Photorealistic and Very-Large-Scale Indoor Dataset of Sequences with Robot Trajectories and Interactions
Jan 19, 2019



Enter the RobotriX, an extremely photorealistic indoor dataset designed to enable the application of deep learning techniques to a wide variety of robotic vision problems. The RobotriX consists of hyperrealistic indoor scenes which are explored by robot agents which also interact with objects in a visually realistic manner in that simulated world. Photorealistic scenes and robots are rendered by Unreal Engine into a virtual reality headset which captures gaze so that a human operator can move the robot and use controllers for the robotic hands; scene information is dumped on a per-frame basis so that it can be reproduced offline to generate raw data and ground truth labels. By taking this approach, we were able to generate a dataset of 38 semantic classes totaling 8M stills recorded at +60 frames per second with full HD resolution. For each frame, RGB-D and 3D information is provided with full annotations in both spaces. Thanks to the high quality and quantity of both raw information and annotations, the RobotriX will serve as a new milestone for investigating 2D and 3D robotic vision tasks with large-scale data-driven techniques.
TactileGCN: A Graph Convolutional Network for Predicting Grasp Stability with Tactile Sensors
Jan 18, 2019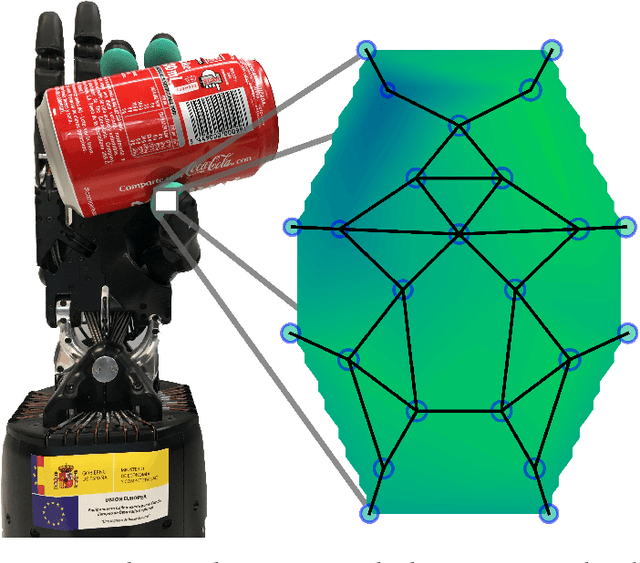
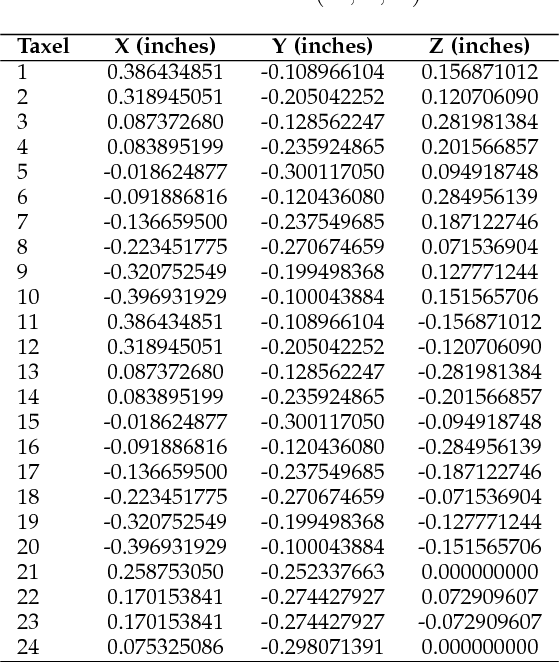

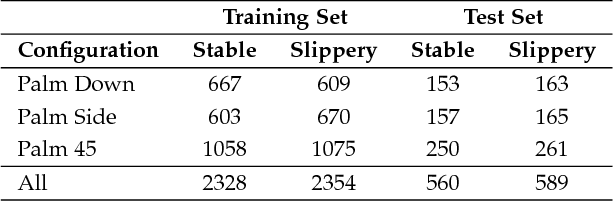
Tactile sensors provide useful contact data during the interaction with an object which can be used to accurately learn to determine the stability of a grasp. Most of the works in the literature represented tactile readings as plain feature vectors or matrix-like tactile images, using them to train machine learning models. In this work, we explore an alternative way of exploiting tactile information to predict grasp stability by leveraging graph-like representations of tactile data, which preserve the actual spatial arrangement of the sensor's taxels and their locality. In experimentation, we trained a Graph Neural Network to binary classify grasps as stable or slippery ones. To train such network and prove its predictive capabilities for the problem at hand, we captured a novel dataset of approximately 5000 three-fingered grasps across 41 objects for training and 1000 grasps with 10 unknown objects for testing. Our experiments prove that this novel approach can be effectively used to predict grasp stability.
UnrealROX: An eXtremely Photorealistic Virtual Reality Environment for Robotics Simulations and Synthetic Data Generation
Oct 16, 2018


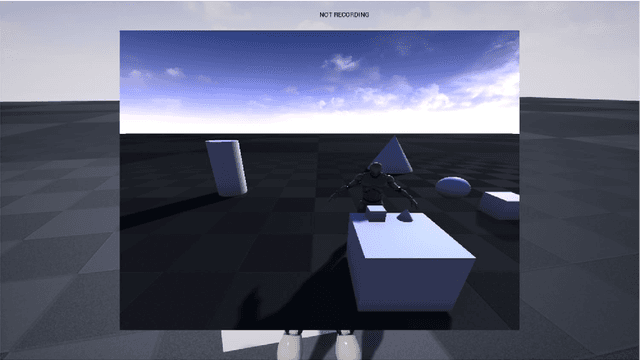
Data-driven algorithms have surpassed traditional techniques in almost every aspect in robotic vision problems. Such algorithms need vast amounts of quality data to be able to work properly after their training process. Gathering and annotating that sheer amount of data in the real world is a time-consuming and error-prone task. Those problems limit scale and quality. Synthetic data generation has become increasingly popular since it is faster to generate and automatic to annotate. However, most of the current datasets and environments lack realism, interactions, and details from the real world. UnrealROX is an environment built over Unreal Engine 4 which aims to reduce that reality gap by leveraging hyperrealistic indoor scenes that are explored by robot agents which also interact with objects in a visually realistic manner in that simulated world. Photorealistic scenes and robots are rendered by Unreal Engine into a virtual reality headset which captures gaze so that a human operator can move the robot and use controllers for the robotic hands; scene information is dumped on a per-frame basis so that it can be reproduced offline to generate raw data and ground truth annotations. This virtual reality environment enables robotic vision researchers to generate realistic and visually plausible data with full ground truth for a wide variety of problems such as class and instance semantic segmentation, object detection, depth estimation, visual grasping, and navigation.
A Review on Deep Learning Techniques Applied to Semantic Segmentation
Apr 22, 2017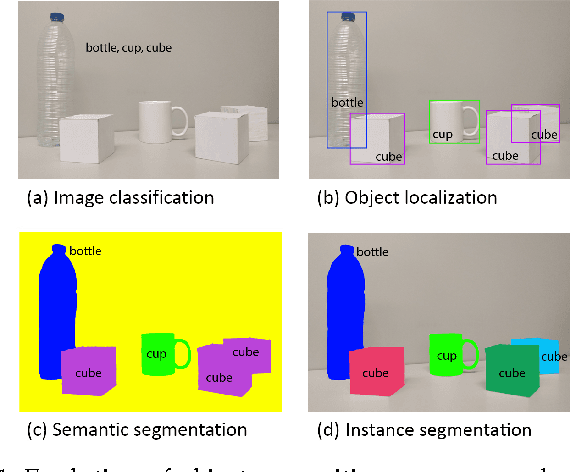
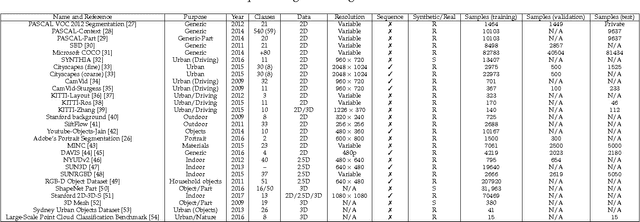
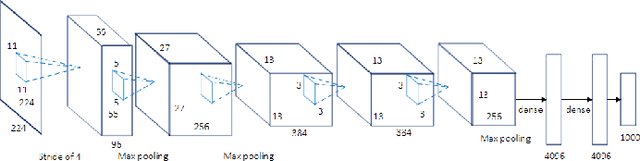
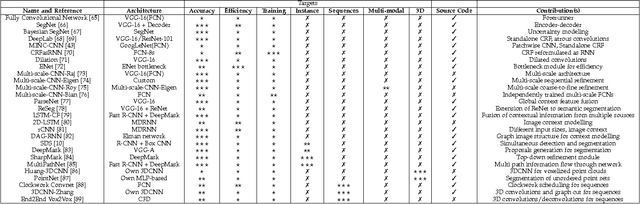
Image semantic segmentation is more and more being of interest for computer vision and machine learning researchers. Many applications on the rise need accurate and efficient segmentation mechanisms: autonomous driving, indoor navigation, and even virtual or augmented reality systems to name a few. This demand coincides with the rise of deep learning approaches in almost every field or application target related to computer vision, including semantic segmentation or scene understanding. This paper provides a review on deep learning methods for semantic segmentation applied to various application areas. Firstly, we describe the terminology of this field as well as mandatory background concepts. Next, the main datasets and challenges are exposed to help researchers decide which are the ones that best suit their needs and their targets. Then, existing methods are reviewed, highlighting their contributions and their significance in the field. Finally, quantitative results are given for the described methods and the datasets in which they were evaluated, following up with a discussion of the results. At last, we point out a set of promising future works and draw our own conclusions about the state of the art of semantic segmentation using deep learning techniques.