 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePer-Group Error, Not Total MSE: Fine-Tuning Vision-Language-Action Models for 11-DoF Mobile Manipulation
May 29, 2026Fine-tuning Vision-Language-Action (VLA) models for mobile manipulators with heterogeneous joint spaces can produce a counterintuitive result: the checkpoint with the lowest aggregate MSE is not the one that performs best on the real robot. We argue this is a predictable consequence of collapsing heterogeneous joint groups (arm, gripper, head, wheeled base) into a single metric, where easy-to-predict joints can mask joints that still fail. We fine-tune SmolVLA (450M, action-expert only) on the 11-DoF Toyota HSR and compare it against $π_{0.5}$ (3.3B), a stronger pretrained baseline. Per-group analysis exposes two patterns: in SmolVLA, the mobile base converges slowest and limits overall performance. In expert-only fine-tuning of $π_{0.5}$ (training only the action head, backbone frozen), total MSE drops below the baseline but arm accuracy degrades. On 60 real-robot trials (20 per model), $π_{0.5}$ 80k (4.0/4) significantly outperforms both fine-tuned variants (expert-only 3k: 3.75/4; HSR-SmolVLA: 3.5/4; Mann-Whitney $p \leq 0.010$), despite expert-only 3k having the lowest total MSE. This separation is most consistent with the offline arm-group error, not total MSE or base-group error. We conclude that per-group error is a more reliable signal than total MSE for checkpoint selection on robots with heterogeneous action spaces. Code: https://github.com/paumontagut/per-group-mse-vla
OSCAR: Open-Set CAD Retrieval from a Language Prompt and a Single Image
Jan 12, 20266D object pose estimation plays a crucial role in scene understanding for applications such as robotics and augmented reality. To support the needs of ever-changing object sets in such context, modern zero-shot object pose estimators were developed to not require object-specific training but only rely on CAD models. Such models are hard to obtain once deployed, and a continuously changing and growing set of objects makes it harder to reliably identify the instance model of interest. To address this challenge, we introduce an Open-Set CAD Retrieval from a Language Prompt and a Single Image (OSCAR), a novel training-free method that retrieves a matching object model from an unlabeled 3D object database. During onboarding, OSCAR generates multi-view renderings of database models and annotates them with descriptive captions using an image captioning model. At inference, GroundedSAM detects the queried object in the input image, and multi-modal embeddings are computed for both the Region-of-Interest and the database captions. OSCAR employs a two-stage retrieval: text-based filtering using CLIP identifies candidate models, followed by image-based refinement using DINOv2 to select the most visually similar object. In our experiments we demonstrate that OSCAR outperforms all state-of-the-art methods on the cross-domain 3D model retrieval benchmark MI3DOR. Furthermore, we demonstrate OSCAR's direct applicability in automating object model sourcing for 6D object pose estimation. We propose using the most similar object model for pose estimation if the exact instance is not available and show that OSCAR achieves an average precision of 90.48\% during object retrieval on the YCB-V object dataset. Moreover, we demonstrate that the most similar object model can be utilized for pose estimation using Megapose achieving better results than a reconstruction-based approach.
Sim2Real Transfer for Vision-Based Grasp Verification
May 05, 2025The verification of successful grasps is a crucial aspect of robot manipulation, particularly when handling deformable objects. Traditional methods relying on force and tactile sensors often struggle with deformable and non-rigid objects. In this work, we present a vision-based approach for grasp verification to determine whether the robotic gripper has successfully grasped an object. Our method employs a two-stage architecture; first YOLO-based object detection model to detect and locate the robot's gripper and then a ResNet-based classifier determines the presence of an object. To address the limitations of real-world data capture, we introduce HSR-GraspSynth, a synthetic dataset designed to simulate diverse grasping scenarios. Furthermore, we explore the use of Visual Question Answering capabilities as a zero-shot baseline to which we compare our model. Experimental results demonstrate that our approach achieves high accuracy in real-world environments, with potential for integration into grasping pipelines. Code and datasets are publicly available at https://github.com/pauamargant/HSR-GraspSynth .
LLM-Empowered Embodied Agent for Memory-Augmented Task Planning in Household Robotics
Apr 30, 2025
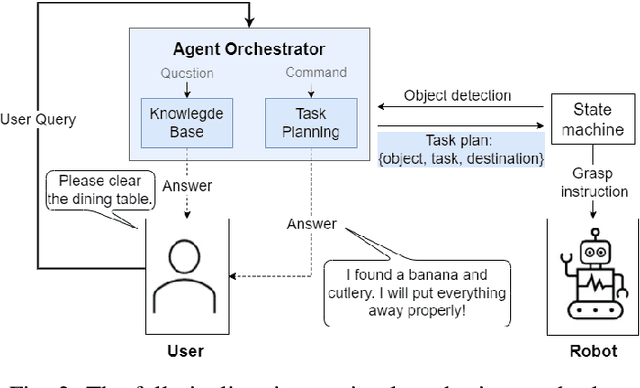
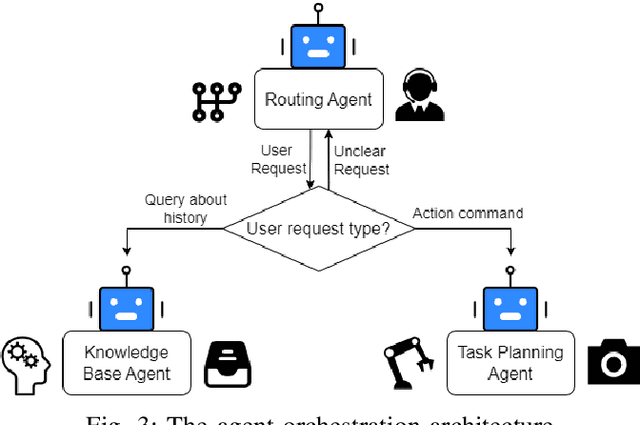
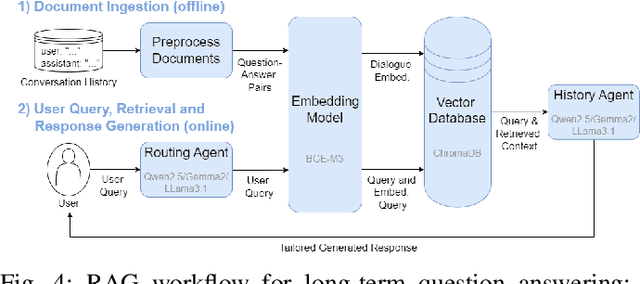
We present an embodied robotic system with an LLM-driven agent-orchestration architecture for autonomous household object management. The system integrates memory-augmented task planning, enabling robots to execute high-level user commands while tracking past actions. It employs three specialized agents: a routing agent, a task planning agent, and a knowledge base agent, each powered by task-specific LLMs. By leveraging in-context learning, our system avoids the need for explicit model training. RAG enables the system to retrieve context from past interactions, enhancing long-term object tracking. A combination of Grounded SAM and LLaMa3.2-Vision provides robust object detection, facilitating semantic scene understanding for task planning. Evaluation across three household scenarios demonstrates high task planning accuracy and an improvement in memory recall due to RAG. Specifically, Qwen2.5 yields best performance for specialized agents, while LLaMA3.1 excels in routing tasks. The source code is available at: https://github.com/marc1198/chat-hsr.
Category-Level and Open-Set Object Pose Estimation for Robotics
Apr 28, 2025Object pose estimation enables a variety of tasks in computer vision and robotics, including scene understanding and robotic grasping. The complexity of a pose estimation task depends on the unknown variables related to the target object. While instance-level methods already excel for opaque and Lambertian objects, category-level and open-set methods, where texture, shape, and size are partially or entirely unknown, still struggle with these basic material properties. Since texture is unknown in these scenarios, it cannot be used for disambiguating object symmetries, another core challenge of 6D object pose estimation. The complexity of estimating 6D poses with such a manifold of unknowns led to various datasets, accuracy metrics, and algorithmic solutions. This paper compares datasets, accuracy metrics, and algorithms for solving 6D pose estimation on the category-level. Based on this comparison, we analyze how to bridge category-level and open-set object pose estimation to reach generalization and provide actionable recommendations.
Multi-Modal 3D Mesh Reconstruction from Images and Text
Mar 10, 20256D object pose estimation for unseen objects is essential in robotics but traditionally relies on trained models that require large datasets, high computational costs, and struggle to generalize. Zero-shot approaches eliminate the need for training but depend on pre-existing 3D object models, which are often impractical to obtain. To address this, we propose a language-guided few-shot 3D reconstruction method, reconstructing a 3D mesh from few input images. In the proposed pipeline, receives a set of input images and a language query. A combination of GroundingDINO and Segment Anything Model outputs segmented masks from which a sparse point cloud is reconstructed with VGGSfM. Subsequently, the mesh is reconstructed with the Gaussian Splatting method SuGAR. In a final cleaning step, artifacts are removed, resulting in the final 3D mesh of the queried object. We evaluate the method in terms of accuracy and quality of the geometry and texture. Furthermore, we study the impact of imaging conditions such as viewing angle, number of input images, and image overlap on 3D object reconstruction quality, efficiency, and computational scalability.
Enhancing Transparent Object Pose Estimation: A Fusion of GDR-Net and Edge Detection
Feb 17, 2025
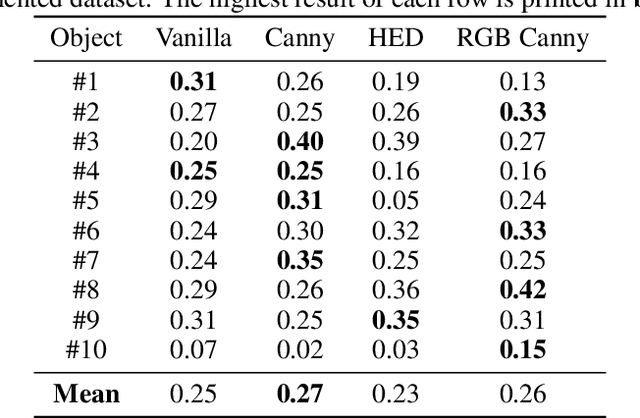
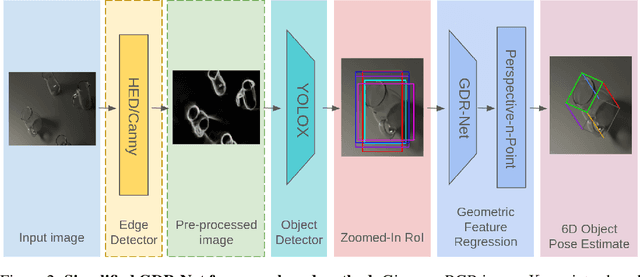
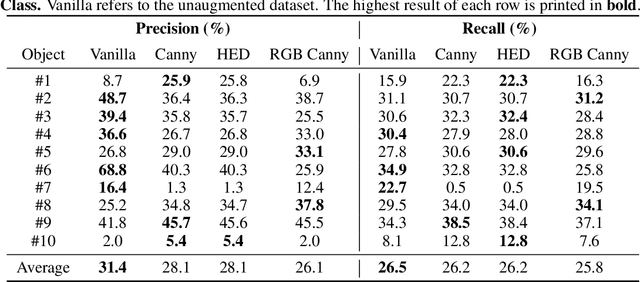
Object pose estimation of transparent objects remains a challenging task in the field of robot vision due to the immense influence of lighting, background, and reflections. However, the edges of clear objects have the highest contrast, which leads to stable and prominent features. We propose a novel approach by incorporating edge detection in a pre-processing step for the tasks of object detection and object pose estimation. We conducted experiments to investigate the effect of edge detectors on transparent objects. We examine the performance of the state-of-the-art 6D object pose estimation pipeline GDR-Net and the object detector YOLOX when applying different edge detectors as pre-processing steps (i.e., Canny edge detection with and without color information, and holistically-nested edges (HED)). We evaluate the physically-based rendered dataset Trans6D-32 K of transparent objects with parameters proposed by the BOP Challenge. Our results indicate that applying edge detection as a pre-processing enhances performance for certain objects.
* accepted at First Austrian Symposium on AI, Robotics, and Vision (AIROV 2024)
ReFlow6D: Refraction-Guided Transparent Object 6D Pose Estimation via Intermediate Representation Learning
Dec 30, 2024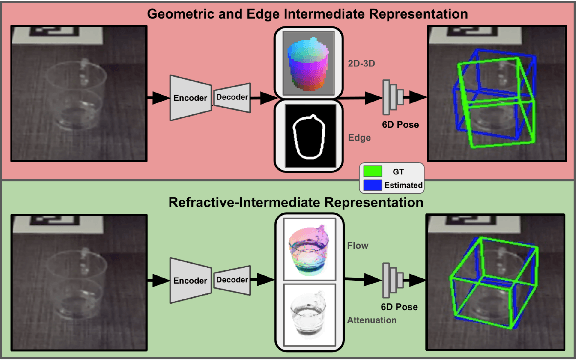
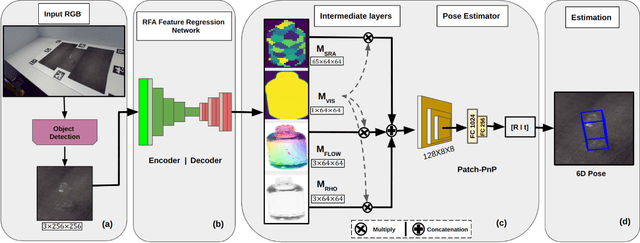


Transparent objects are ubiquitous in daily life, making their perception and robotics manipulation important. However, they present a major challenge due to their distinct refractive and reflective properties when it comes to accurately estimating the 6D pose. To solve this, we present ReFlow6D, a novel method for transparent object 6D pose estimation that harnesses the refractive-intermediate representation. Unlike conventional approaches, our method leverages a feature space impervious to changes in RGB image space and independent of depth information. Drawing inspiration from image matting, we model the deformation of the light path through transparent objects, yielding a unique object-specific intermediate representation guided by light refraction that is independent of the environment in which objects are observed. By integrating these intermediate features into the pose estimation network, we show that ReFlow6D achieves precise 6D pose estimation of transparent objects, using only RGB images as input. Our method further introduces a novel transparent object compositing loss, fostering the generation of superior refractive-intermediate features. Empirical evaluations show that our approach significantly outperforms state-of-the-art methods on TOD and Trans32K-6D datasets. Robot grasping experiments further demonstrate that ReFlow6D's pose estimation accuracy effectively translates to real-world robotics task. The source code is available at: https://github.com/StoicGilgamesh/ReFlow6D and https://github.com/StoicGilgamesh/matting_rendering.
Diffusion Features for Zero-Shot 6DoF Object Pose Estimation
Nov 25, 2024



Zero-shot object pose estimation enables the retrieval of object poses from images without necessitating object-specific training. In recent approaches this is facilitated by vision foundation models (VFM), which are pre-trained models that are effectively general-purpose feature extractors. The characteristics exhibited by these VFMs vary depending on the training data, network architecture, and training paradigm. The prevailing choice in this field are self-supervised Vision Transformers (ViT). This study assesses the influence of Latent Diffusion Model (LDM) backbones on zero-shot pose estimation. In order to facilitate a comparison between the two families of models on a common ground we adopt and modify a recent approach. Therefore, a template-based multi-staged method for estimating poses in a zero-shot fashion using LDMs is presented. The efficacy of the proposed approach is empirically evaluated on three standard datasets for object-specific 6DoF pose estimation. The experiments demonstrate an Average Recall improvement of up to 27% over the ViT baseline. The source code is available at: https://github.com/BvG1993/DZOP.
ODYSSEE: Oyster Detection Yielded by Sensor Systems on Edge Electronics
Sep 11, 2024
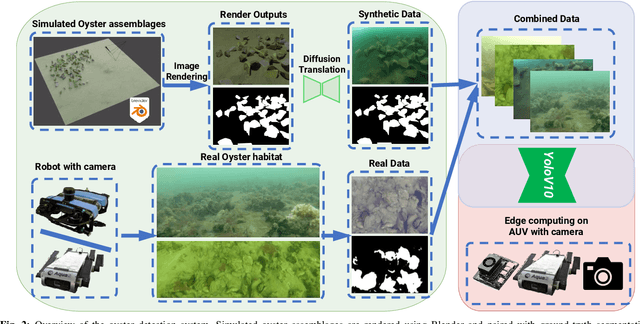

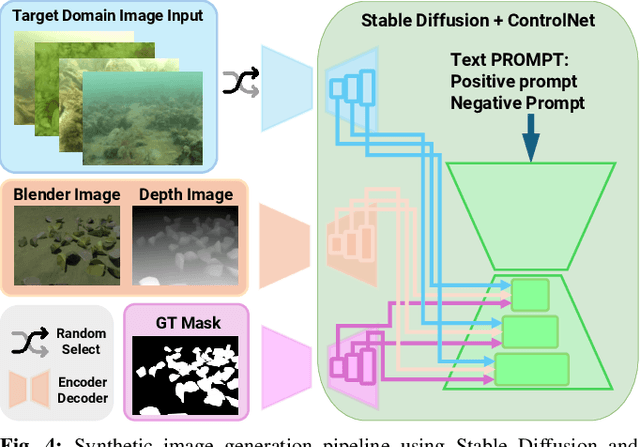
Oysters are a keystone species in coastal ecosystems, offering significant economic, environmental, and cultural benefits. However, current monitoring systems are often destructive, typically involving dredging to physically collect and count oysters. A nondestructive alternative is manual identification from video footage collected by divers, which is time-consuming and labor-intensive with expert input. An alternative to human monitoring is the deployment of a system with trained object detection models that performs real-time, on edge oyster detection in the field. One such platform is the Aqua2 robot. Effective training of these models requires extensive high-quality data, which is difficult to obtain in marine settings. To address these complications, we introduce a novel method that leverages stable diffusion to generate high-quality synthetic data for the marine domain. We exploit diffusion models to create photorealistic marine imagery, using ControlNet inputs to ensure consistency with the segmentation ground-truth mask, the geometry of the scene, and the target domain of real underwater images for oysters. The resulting dataset is used to train a YOLOv10-based vision model, achieving a state-of-the-art 0.657 mAP@50 for oyster detection on the Aqua2 platform. The system we introduce not only improves oyster habitat monitoring, but also paves the way to autonomous surveillance for various tasks in marine contexts, improving aquaculture and conservation efforts.