 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs AI currently capable of identifying wild oysters? A comparison of human annotators against the AI model, ODYSSEE
May 06, 2025Oysters are ecologically and commercially important species that require frequent monitoring to track population demographics (e.g. abundance, growth, mortality). Current methods of monitoring oyster reefs often require destructive sampling methods and extensive manual effort. Therefore, they are suboptimal for small-scale or sensitive environments. A recent alternative, the ODYSSEE model, was developed to use deep learning techniques to identify live oysters using video or images taken in the field of oyster reefs to assess abundance. The validity of this model in identifying live oysters on a reef was compared to expert and non-expert annotators. In addition, we identified potential sources of prediction error. Although the model can make inferences significantly faster than expert and non-expert annotators (39.6 s, $2.34 \pm 0.61$ h, $4.50 \pm 1.46$ h, respectively), the model overpredicted the number of live oysters, achieving lower accuracy (63\%) in identifying live oysters compared to experts (74\%) and non-experts (75\%) alike. Image quality was an important factor in determining the accuracy of the model and the annotators. Better quality images improved human accuracy and worsened model accuracy. Although ODYSSEE was not sufficiently accurate, we anticipate that future training on higher-quality images, utilizing additional live imagery, and incorporating additional annotation training classes will greatly improve the model's predictive power based on the results of this analysis. Future research should address methods that improve the detection of living vs. dead oysters.
ViT-VS: On the Applicability of Pretrained Vision Transformer Features for Generalizable Visual Servoing
Mar 06, 2025



Visual servoing enables robots to precisely position their end-effector relative to a target object. While classical methods rely on hand-crafted features and thus are universally applicable without task-specific training, they often struggle with occlusions and environmental variations, whereas learning-based approaches improve robustness but typically require extensive training. We present a visual servoing approach that leverages pretrained vision transformers for semantic feature extraction, combining the advantages of both paradigms while also being able to generalize beyond the provided sample. Our approach achieves full convergence in unperturbed scenarios and surpasses classical image-based visual servoing by up to 31.2\% relative improvement in perturbed scenarios. Even the convergence rates of learning-based methods are matched despite requiring no task- or object-specific training. Real-world evaluations confirm robust performance in end-effector positioning, industrial box manipulation, and grasping of unseen objects using only a reference from the same category. Our code and simulation environment are available at: https://alessandroscherl.github.io/ViT-VS/
ODYSSEE: Oyster Detection Yielded by Sensor Systems on Edge Electronics
Sep 11, 2024
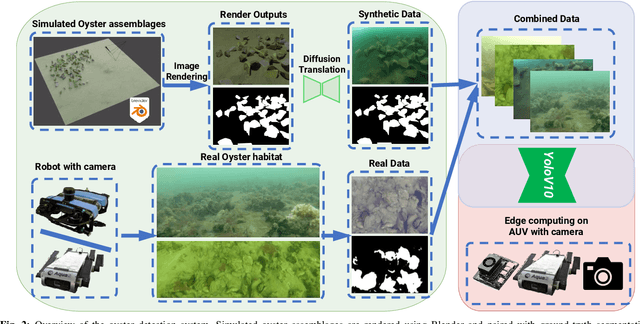

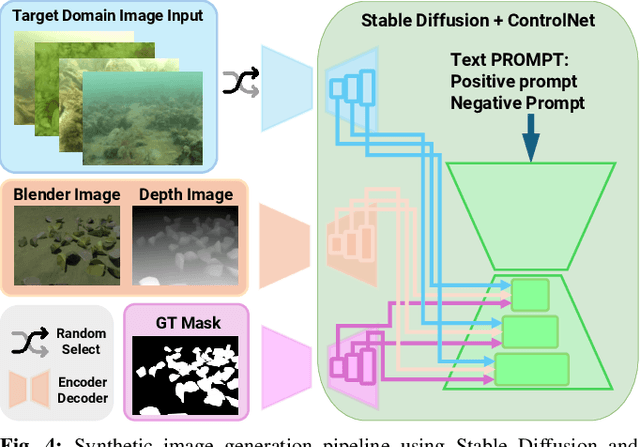
Oysters are a keystone species in coastal ecosystems, offering significant economic, environmental, and cultural benefits. However, current monitoring systems are often destructive, typically involving dredging to physically collect and count oysters. A nondestructive alternative is manual identification from video footage collected by divers, which is time-consuming and labor-intensive with expert input. An alternative to human monitoring is the deployment of a system with trained object detection models that performs real-time, on edge oyster detection in the field. One such platform is the Aqua2 robot. Effective training of these models requires extensive high-quality data, which is difficult to obtain in marine settings. To address these complications, we introduce a novel method that leverages stable diffusion to generate high-quality synthetic data for the marine domain. We exploit diffusion models to create photorealistic marine imagery, using ControlNet inputs to ensure consistency with the segmentation ground-truth mask, the geometry of the scene, and the target domain of real underwater images for oysters. The resulting dataset is used to train a YOLOv10-based vision model, achieving a state-of-the-art 0.657 mAP@50 for oyster detection on the Aqua2 platform. The system we introduce not only improves oyster habitat monitoring, but also paves the way to autonomous surveillance for various tasks in marine contexts, improving aquaculture and conservation efforts.