 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-VS: On the Applicability of Pretrained Vision Transformer Features for Generalizable Visual Servoing
Mar 06, 2025



Visual servoing enables robots to precisely position their end-effector relative to a target object. While classical methods rely on hand-crafted features and thus are universally applicable without task-specific training, they often struggle with occlusions and environmental variations, whereas learning-based approaches improve robustness but typically require extensive training. We present a visual servoing approach that leverages pretrained vision transformers for semantic feature extraction, combining the advantages of both paradigms while also being able to generalize beyond the provided sample. Our approach achieves full convergence in unperturbed scenarios and surpasses classical image-based visual servoing by up to 31.2\% relative improvement in perturbed scenarios. Even the convergence rates of learning-based methods are matched despite requiring no task- or object-specific training. Real-world evaluations confirm robust performance in end-effector positioning, industrial box manipulation, and grasping of unseen objects using only a reference from the same category. Our code and simulation environment are available at: https://alessandroscherl.github.io/ViT-VS/
Enhancing Transparent Object Pose Estimation: A Fusion of GDR-Net and Edge Detection
Feb 17, 2025
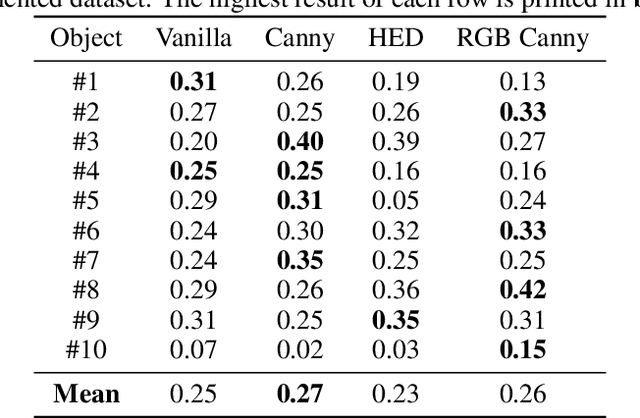
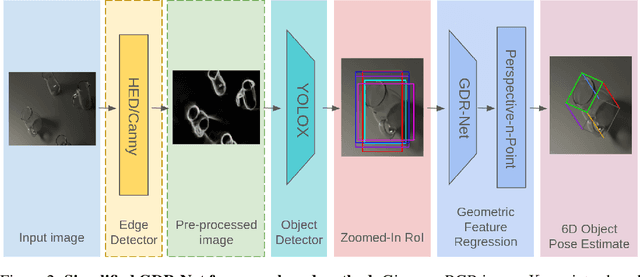
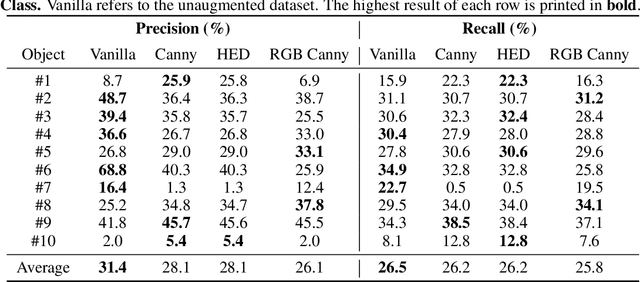
Object pose estimation of transparent objects remains a challenging task in the field of robot vision due to the immense influence of lighting, background, and reflections. However, the edges of clear objects have the highest contrast, which leads to stable and prominent features. We propose a novel approach by incorporating edge detection in a pre-processing step for the tasks of object detection and object pose estimation. We conducted experiments to investigate the effect of edge detectors on transparent objects. We examine the performance of the state-of-the-art 6D object pose estimation pipeline GDR-Net and the object detector YOLOX when applying different edge detectors as pre-processing steps (i.e., Canny edge detection with and without color information, and holistically-nested edges (HED)). We evaluate the physically-based rendered dataset Trans6D-32 K of transparent objects with parameters proposed by the BOP Challenge. Our results indicate that applying edge detection as a pre-processing enhances performance for certain objects.
* accepted at First Austrian Symposium on AI, Robotics, and Vision (AIROV 2024)
ReFlow6D: Refraction-Guided Transparent Object 6D Pose Estimation via Intermediate Representation Learning
Dec 30, 2024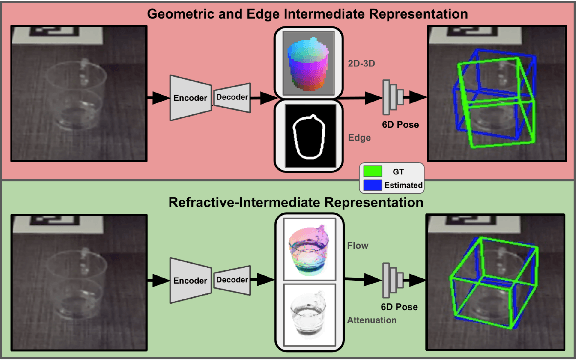
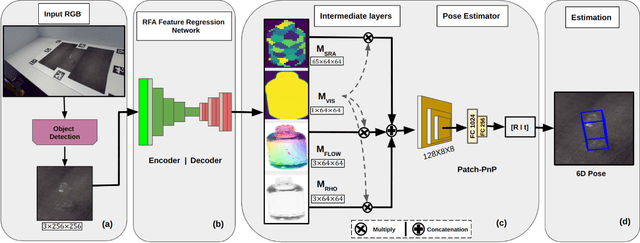


Transparent objects are ubiquitous in daily life, making their perception and robotics manipulation important. However, they present a major challenge due to their distinct refractive and reflective properties when it comes to accurately estimating the 6D pose. To solve this, we present ReFlow6D, a novel method for transparent object 6D pose estimation that harnesses the refractive-intermediate representation. Unlike conventional approaches, our method leverages a feature space impervious to changes in RGB image space and independent of depth information. Drawing inspiration from image matting, we model the deformation of the light path through transparent objects, yielding a unique object-specific intermediate representation guided by light refraction that is independent of the environment in which objects are observed. By integrating these intermediate features into the pose estimation network, we show that ReFlow6D achieves precise 6D pose estimation of transparent objects, using only RGB images as input. Our method further introduces a novel transparent object compositing loss, fostering the generation of superior refractive-intermediate features. Empirical evaluations show that our approach significantly outperforms state-of-the-art methods on TOD and Trans32K-6D datasets. Robot grasping experiments further demonstrate that ReFlow6D's pose estimation accuracy effectively translates to real-world robotics task. The source code is available at: https://github.com/StoicGilgamesh/ReFlow6D and https://github.com/StoicGilgamesh/matting_rendering.
Diffusion Features for Zero-Shot 6DoF Object Pose Estimation
Nov 25, 2024



Zero-shot object pose estimation enables the retrieval of object poses from images without necessitating object-specific training. In recent approaches this is facilitated by vision foundation models (VFM), which are pre-trained models that are effectively general-purpose feature extractors. The characteristics exhibited by these VFMs vary depending on the training data, network architecture, and training paradigm. The prevailing choice in this field are self-supervised Vision Transformers (ViT). This study assesses the influence of Latent Diffusion Model (LDM) backbones on zero-shot pose estimation. In order to facilitate a comparison between the two families of models on a common ground we adopt and modify a recent approach. Therefore, a template-based multi-staged method for estimating poses in a zero-shot fashion using LDMs is presented. The efficacy of the proposed approach is empirically evaluated on three standard datasets for object-specific 6DoF pose estimation. The experiments demonstrate an Average Recall improvement of up to 27% over the ViT baseline. The source code is available at: https://github.com/BvG1993/DZOP.
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Sep 09, 2024

Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Semi-Autonomous Mobile Search and Rescue Robot for Radiation Disaster Scenarios
Jun 20, 2024This paper describes a novel semi-autonomous mobile robot system designed to assist search and rescue (SAR) first responders in disaster scenarios. While robots offer significant potential in SAR missions, current solutions are limited in their ability to handle a diverse range of tasks. This gap is addressed by presenting a system capable of (1) autonomous navigation and mapping, allowing the robot to autonomously explore and map areas affected by catastrophic events, (2) radiation mapping, enabling the system to triangulate a radiation map from discrete radiation measurements to aid in identifying hazardous areas, (3) semi-autonomous substance sampling, allowing the robot to collect samples of suspicious substances and analyze them onboard with immediate classification, and (4) valve manipulation, enabling teleoperated closing of valves that control hazardous material flow. This semi-autonomous approach balances human control over critical tasks like substance sampling with efficient robot navigation in low-risk areas. The system is evaluated during three trials that simulate possible disaster scenarios, two of which have been recorded during the European Robotics Hackathon (EnRicH). Furthermore, we provide recorded sensor data as well as the implemented software system as supplemental material through a GitHub repository: https://github.com/TW-Robotics/search-and-rescue-robot-IROS2024.
Improving 2D-3D Dense Correspondences with Diffusion Models for 6D Object Pose Estimation
Feb 09, 2024



Estimating 2D-3D correspondences between RGB images and 3D space is a fundamental problem in 6D object pose estimation. Recent pose estimators use dense correspondence maps and Point-to-Point algorithms to estimate object poses. The accuracy of pose estimation depends heavily on the quality of the dense correspondence maps and their ability to withstand occlusion, clutter, and challenging material properties. Currently, dense correspondence maps are estimated using image-to-image translation models based on GANs, Autoencoders, or direct regression models. However, recent advancements in image-to-image translation have led to diffusion models being the superior choice when evaluated on benchmarking datasets. In this study, we compare image-to-image translation networks based on GANs and diffusion models for the downstream task of 6D object pose estimation. Our results demonstrate that the diffusion-based image-to-image translation model outperforms the GAN, revealing potential for further improvements in 6D object pose estimation models.
STAR: Shape-focused Texture Agnostic Representations for Improved Object Detection and 6D Pose Estimation
Feb 07, 2024



Recent advances in machine learning have greatly benefited object detection and 6D pose estimation for robotic grasping. However, textureless and metallic objects still pose a significant challenge due to fewer visual cues and the texture bias of CNNs. To address this issue, we propose a texture-agnostic approach that focuses on learning from CAD models and emphasizes object shape features. To achieve a focus on learning shape features, the textures are randomized during the rendering of the training data. By treating the texture as noise, the need for real-world object instances or their final appearance during training data generation is eliminated. The TLESS and ITODD datasets, specifically created for industrial settings in robotics and featuring textureless and metallic objects, were used for evaluation. Texture agnosticity also increases the robustness against image perturbations such as imaging noise, motion blur, and brightness changes, which are common in robotics applications. Code and datasets are publicly available at github.com/hoenigpeter/randomized_texturing.
ZS6D: Zero-shot 6D Object Pose Estimation using Vision Transformers
Sep 21, 2023



As robotic systems increasingly encounter complex and unconstrained real-world scenarios, there is a demand to recognize diverse objects. The state-of-the-art 6D object pose estimation methods rely on object-specific training and therefore do not generalize to unseen objects. Recent novel object pose estimation methods are solving this issue using task-specific fine-tuned CNNs for deep template matching. This adaptation for pose estimation still requires expensive data rendering and training procedures. MegaPose for example is trained on a dataset consisting of two million images showing 20,000 different objects to reach such generalization capabilities. To overcome this shortcoming we introduce ZS6D, for zero-shot novel object 6D pose estimation. Visual descriptors, extracted using pre-trained Vision Transformers (ViT), are used for matching rendered templates against query images of objects and for establishing local correspondences. These local correspondences enable deriving geometric correspondences and are used for estimating the object's 6D pose with RANSAC-based PnP. This approach showcases that the image descriptors extracted by pre-trained ViTs are well-suited to achieve a notable improvement over two state-of-the-art novel object 6D pose estimation methods, without the need for task-specific fine-tuning. Experiments are performed on LMO, YCBV, and TLESS. In comparison to one of the two methods we improve the Average Recall on all three datasets and compared to the second method we improve on two datasets.
Challenges for Monocular 6D Object Pose Estimation in Robotics
Jul 22, 2023



Object pose estimation is a core perception task that enables, for example, object grasping and scene understanding. The widely available, inexpensive and high-resolution RGB sensors and CNNs that allow for fast inference based on this modality make monocular approaches especially well suited for robotics applications. We observe that previous surveys on object pose estimation establish the state of the art for varying modalities, single- and multi-view settings, and datasets and metrics that consider a multitude of applications. We argue, however, that those works' broad scope hinders the identification of open challenges that are specific to monocular approaches and the derivation of promising future challenges for their application in robotics. By providing a unified view on recent publications from both robotics and computer vision, we find that occlusion handling, novel pose representations, and formalizing and improving category-level pose estimation are still fundamental challenges that are highly relevant for robotics. Moreover, to further improve robotic performance, large object sets, novel objects, refractive materials, and uncertainty estimates are central, largely unsolved open challenges. In order to address them, ontological reasoning, deformability handling, scene-level reasoning, realistic datasets, and the ecological footprint of algorithms need to be improved.