 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Demo is Worth a Thousand Trajectories: Action-View Augmentation for Visuomotor Policies
Jun 17, 2026Visuomotor policies for manipulation have demonstrated remarkable potential in modeling complex robotic behaviors, yet minor alterations in the robot's initial configuration and unseen obstacles easily lead to out-of-distribution observations. Without extensive data collection effort, these result in catastrophic execution failures. In this work, we introduce an effective data augmentation framework that generates visually realistic fisheye image sequences and corresponding physically feasible action trajectories from real-world eye-in-hand demonstrations, captured with a portable parallel gripper with a single fisheye camera. We introduce a novel Gaussian Splatting formulation, adapted to wide FoV fisheye cameras, to reconstruct and edit the 3D scene with unseen objects. We utilize trajectory optimization to generate smooth, collision-free, view-rendering-friendly action trajectories and render visual observations from corresponding novel views. Comprehensive experiments in simulation and the real world show that our augmentation framework improves the success rate for various manipulation tasks in both the same scene and the augmented scene with obstacles requiring collision avoidance.
* Project website: https://chuerpan.com/1001-demos.github.io/. Published at CoRL 2025
Vision-guided Autonomous Dual-arm Extraction Robot for Bell Pepper Harvesting
Mar 14, 2026Agricultural robotics has emerged as a critical solution to the labor shortages and rising costs associated with manual crop harvesting. Bell pepper harvesting, in particular, is a labor-intensive task, accounting for up to 50% of total production costs. While automated solutions have shown promise in controlled greenhouse environments, harvesting in unstructured outdoor farms remains an open challenge due to environmental variability and occlusion. This paper presents VADER (Vision-guided Autonomous Dual-arm Extraction Robot), a dual-arm mobile manipulation system designed specifically for the autonomous harvesting of bell peppers in outdoor environments. The system integrates a robust perception pipeline coupled with a dual-arm planning framework that coordinates a gripping arm and a cutting arm for extraction. We validate the system through trials in various realistic conditions, demonstrating a harvest success rate exceeding 60% with a cycle time of under 100 seconds per fruit, while also featuring a teleoperation fail-safe based on the GELLO teleoperation framework to ensure robustness. To support robust perception, we contribute a hierarchically structured dataset of over 3,200 images spanning indoor and outdoor domains, pairing wide-field scene images with close-up pepper images to enable a coarse-to-fine training strategy from fruit detection to high-precision pose estimation. The code and dataset will be made publicly available upon acceptance.
RoboPanoptes: The All-seeing Robot with Whole-body Dexterity
Jan 09, 2025We present RoboPanoptes, a capable yet practical robot system that achieves whole-body dexterity through whole-body vision. Its whole-body dexterity allows the robot to utilize its entire body surface for manipulation, such as leveraging multiple contact points or navigating constrained spaces. Meanwhile, whole-body vision uses a camera system distributed over the robot's surface to provide comprehensive, multi-perspective visual feedback of its own and the environment's state. At its core, RoboPanoptes uses a whole-body visuomotor policy that learns complex manipulation skills directly from human demonstrations, efficiently aggregating information from the distributed cameras while maintaining resilience to sensor failures. Together, these design aspects unlock new capabilities and tasks, allowing RoboPanoptes to unbox in narrow spaces, sweep multiple or oversized objects, and succeed in multi-step stowing in cluttered environments, outperforming baselines in adaptability and efficiency. Results are best viewed on https://robopanoptes.github.io.
Real2Code: Reconstruct Articulated Objects via Code Generation
Jun 12, 2024



We present Real2Code, a novel approach to reconstructing articulated objects via code generation. Given visual observations of an object, we first reconstruct its part geometry using an image segmentation model and a shape completion model. We then represent the object parts with oriented bounding boxes, which are input to a fine-tuned large language model (LLM) to predict joint articulation as code. By leveraging pre-trained vision and language models, our approach scales elegantly with the number of articulated parts, and generalizes from synthetic training data to real world objects in unstructured environments. Experimental results demonstrate that Real2Code significantly outperforms previous state-of-the-art in reconstruction accuracy, and is the first approach to extrapolate beyond objects' structural complexity in the training set, and reconstructs objects with up to 10 articulated parts. When incorporated with a stereo reconstruction model, Real2Code also generalizes to real world objects from a handful of multi-view RGB images, without the need for depth or camera information.
DoughNet: A Visual Predictive Model for Topological Manipulation of Deformable Objects
Apr 18, 2024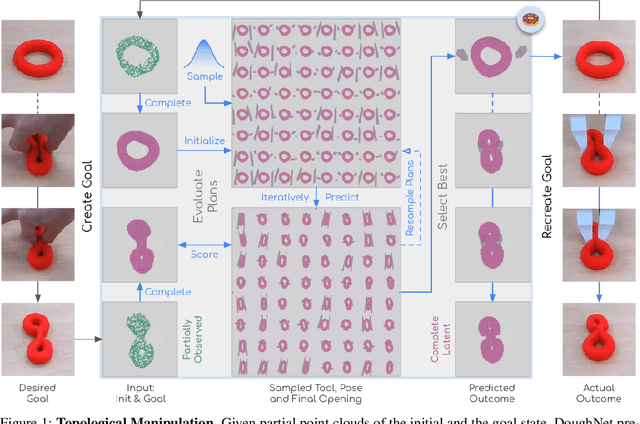
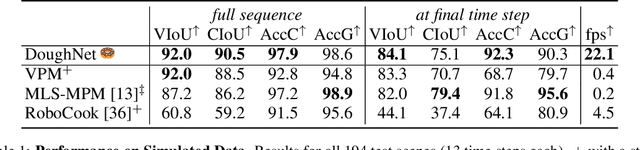
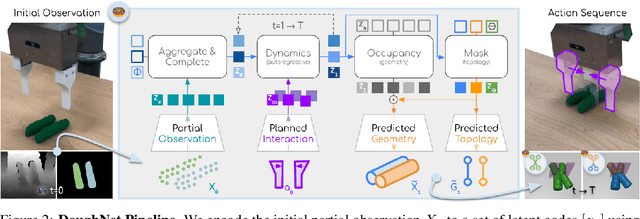
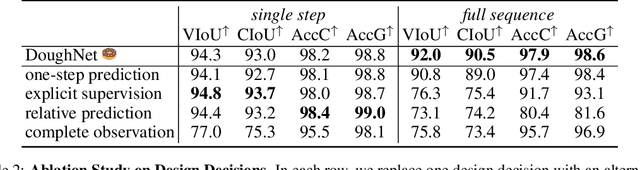
Manipulation of elastoplastic objects like dough often involves topological changes such as splitting and merging. The ability to accurately predict these topological changes that a specific action might incur is critical for planning interactions with elastoplastic objects. We present DoughNet, a Transformer-based architecture for handling these challenges, consisting of two components. First, a denoising autoencoder represents deformable objects of varying topology as sets of latent codes. Second, a visual predictive model performs autoregressive set prediction to determine long-horizon geometrical deformation and topological changes purely in latent space. Given a partial initial state and desired manipulation trajectories, it infers all resulting object geometries and topologies at each step. DoughNet thereby allows to plan robotic manipulation; selecting a suited tool, its pose and opening width to recreate robot- or human-made goals. Our experiments in simulated and real environments show that DoughNet is able to significantly outperform related approaches that consider deformation only as geometrical change.
TrackAgent: 6D Object Tracking via Reinforcement Learning
Jul 28, 2023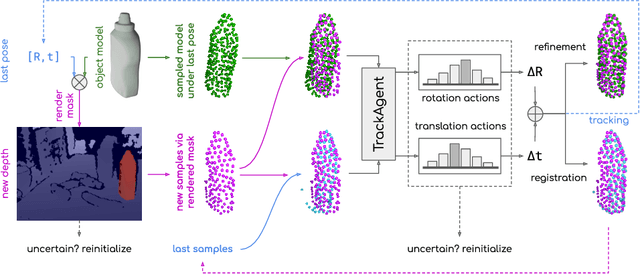


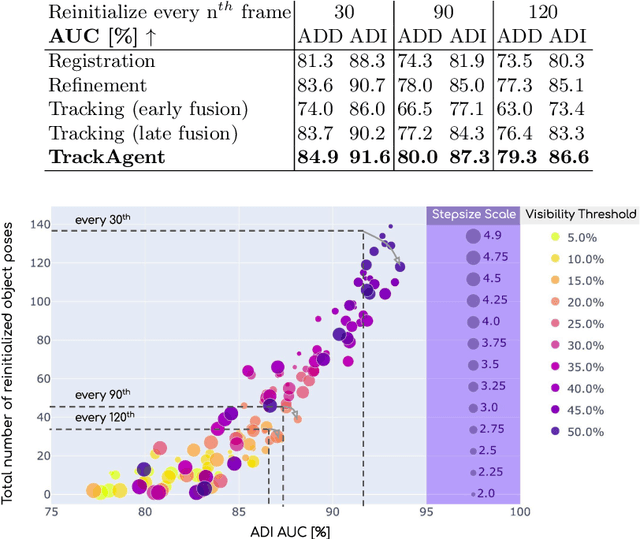
Tracking an object's 6D pose, while either the object itself or the observing camera is moving, is important for many robotics and augmented reality applications. While exploiting temporal priors eases this problem, object-specific knowledge is required to recover when tracking is lost. Under the tight time constraints of the tracking task, RGB(D)-based methods are often conceptionally complex or rely on heuristic motion models. In comparison, we propose to simplify object tracking to a reinforced point cloud (depth only) alignment task. This allows us to train a streamlined approach from scratch with limited amounts of sparse 3D point clouds, compared to the large datasets of diverse RGBD sequences required in previous works. We incorporate temporal frame-to-frame registration with object-based recovery by frame-to-model refinement using a reinforcement learning (RL) agent that jointly solves for both objectives. We also show that the RL agent's uncertainty and a rendering-based mask propagation are effective reinitialization triggers.
Challenges for Monocular 6D Object Pose Estimation in Robotics
Jul 22, 2023



Object pose estimation is a core perception task that enables, for example, object grasping and scene understanding. The widely available, inexpensive and high-resolution RGB sensors and CNNs that allow for fast inference based on this modality make monocular approaches especially well suited for robotics applications. We observe that previous surveys on object pose estimation establish the state of the art for varying modalities, single- and multi-view settings, and datasets and metrics that consider a multitude of applications. We argue, however, that those works' broad scope hinders the identification of open challenges that are specific to monocular approaches and the derivation of promising future challenges for their application in robotics. By providing a unified view on recent publications from both robotics and computer vision, we find that occlusion handling, novel pose representations, and formalizing and improving category-level pose estimation are still fundamental challenges that are highly relevant for robotics. Moreover, to further improve robotic performance, large object sets, novel objects, refractive materials, and uncertainty estimates are central, largely unsolved open challenges. In order to address them, ontological reasoning, deformability handling, scene-level reasoning, realistic datasets, and the ecological footprint of algorithms need to be improved.
A Framework for Designing Anthropomorphic Soft Hands through Interaction
Jun 07, 2023
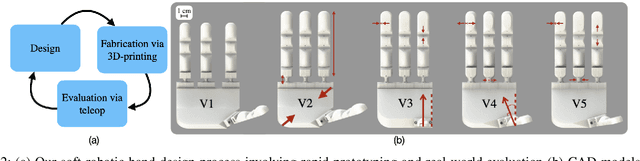
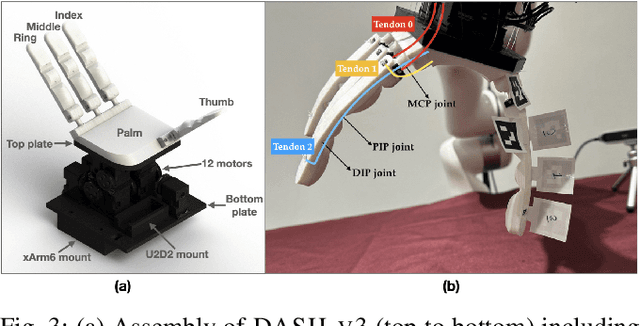

Modeling and simulating soft robot hands can aid in design iteration for complex and high degree-of-freedom (DoF) morphologies. This can be further supplemented by iterating on the design based on its performance in real world manipulation tasks. However, this requires a framework that allows us to iterate quickly at low costs. In this paper, we present a framework that leverages rapid prototyping of the hand using 3D-printing, and utilizes teleoperation to evaluate the hand in real world manipulation tasks. Using this framework, we design a 3D-printed 16-DoF dexterous anthropomorphic soft hand (DASH) and iteratively improve its design over three iterations. Rapid prototyping techniques such as 3D-printing allow us to directly evaluate the fabricated hand without modeling it in simulation. We show that the design is improved at each iteration through the hand's performance in 30 real-world teleoperated manipulation tasks. Testing over 600 demonstrations shows that our final version of DASH can solve 16 of the 30 tasks compared to Allegro, a popular rigid hand in the market, which can only solve 7 tasks. We open-source our CAD models as well as the teleoperated dataset for further study and are available on our website (https://dash-through-interaction.github.io.)
SporeAgent: Reinforced Scene-level Plausibility for Object Pose Refinement
Jan 01, 2022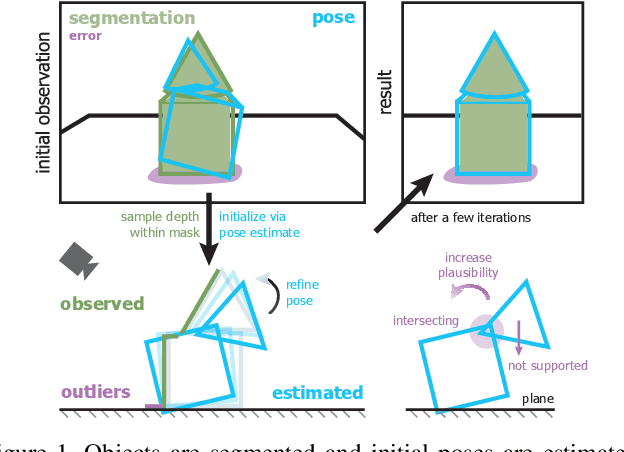

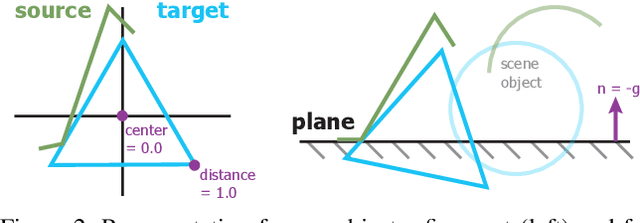
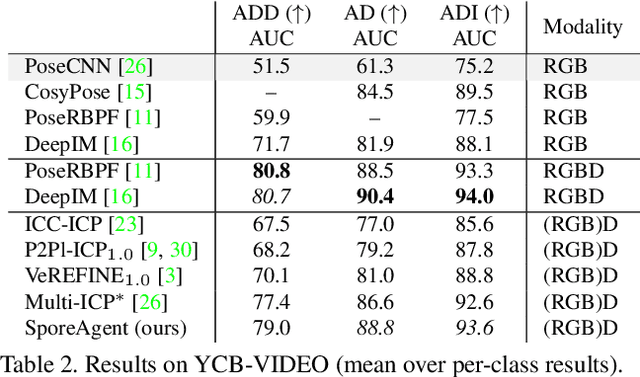
Observational noise, inaccurate segmentation and ambiguity due to symmetry and occlusion lead to inaccurate object pose estimates. While depth- and RGB-based pose refinement approaches increase the accuracy of the resulting pose estimates, they are susceptible to ambiguity in the observation as they consider visual alignment. We propose to leverage the fact that we often observe static, rigid scenes. Thus, the objects therein need to be under physically plausible poses. We show that considering plausibility reduces ambiguity and, in consequence, allows poses to be more accurately predicted in cluttered environments. To this end, we extend a recent RL-based registration approach towards iterative refinement of object poses. Experiments on the LINEMOD and YCB-VIDEO datasets demonstrate the state-of-the-art performance of our depth-based refinement approach.
Towards Very Low-Cost Iterative Prototyping for Fully Printable Dexterous Soft Robotic Hands
Nov 02, 2021


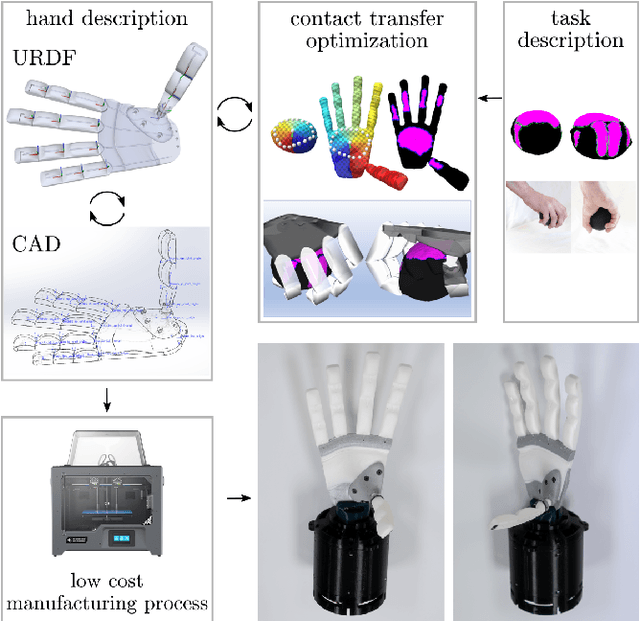
The design and fabrication of soft robot hands is still a time-consuming and difficult process. Advances in rapid prototyping have accelerated the fabrication process significantly while introducing new complexities into the design process. In this work, we present an approach that utilizes novel low-cost fabrication techniques in conjunction with design tools helping soft hand designers to systematically take advantage of multi-material 3D printing to create dexterous soft robotic hands. While very low cost and lightweight, we show that generated designs are highly durable, surprisingly strong, and capable of dexterous grasping.