 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models
Dec 22, 2025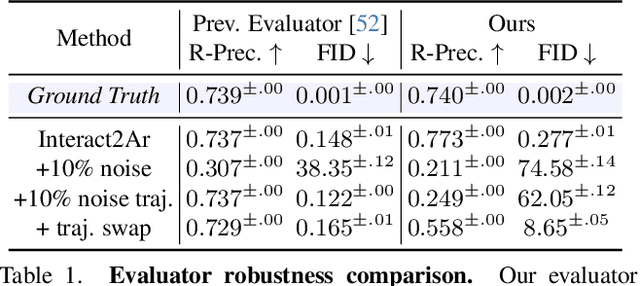
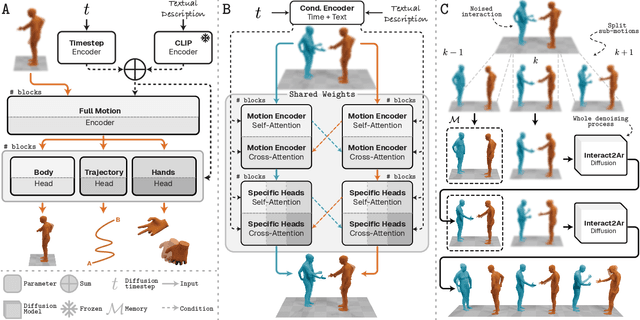
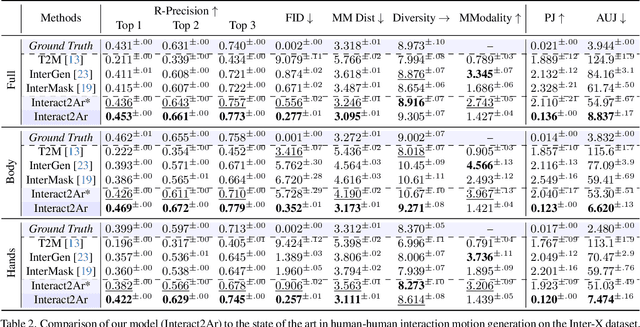
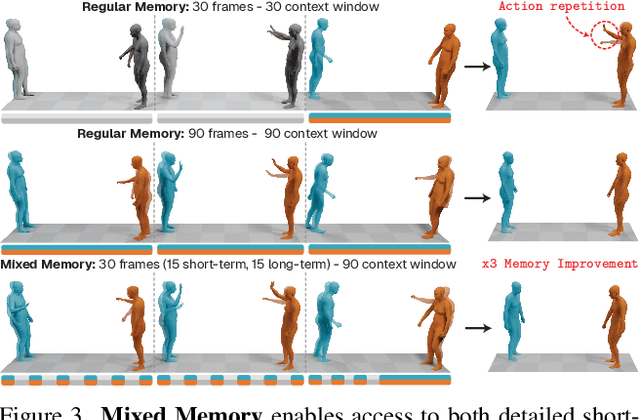
Generating realistic human-human interactions is a challenging task that requires not only high-quality individual body and hand motions, but also coherent coordination among all interactants. Due to limitations in available data and increased learning complexity, previous methods tend to ignore hand motions, limiting the realism and expressivity of the interactions. Additionally, current diffusion-based approaches generate entire motion sequences simultaneously, limiting their ability to capture the reactive and adaptive nature of human interactions. To address these limitations, we introduce Interact2Ar, the first end-to-end text-conditioned autoregressive diffusion model for generating full-body, human-human interactions. Interact2Ar incorporates detailed hand kinematics through dedicated parallel branches, enabling high-fidelity full-body generation. Furthermore, we introduce an autoregressive pipeline coupled with a novel memory technique that facilitates adaptation to the inherent variability of human interactions using efficient large context windows. The adaptability of our model enables a series of downstream applications, including temporal motion composition, real-time adaptation to disturbances, and extension beyond dyadic to multi-person scenarios. To validate the generated motions, we introduce a set of robust evaluators and extended metrics designed specifically for assessing full-body interactions. Through quantitative and qualitative experiments, we demonstrate the state-of-the-art performance of Interact2Ar.
MixerMDM: Learnable Composition of Human Motion Diffusion Models
Apr 01, 2025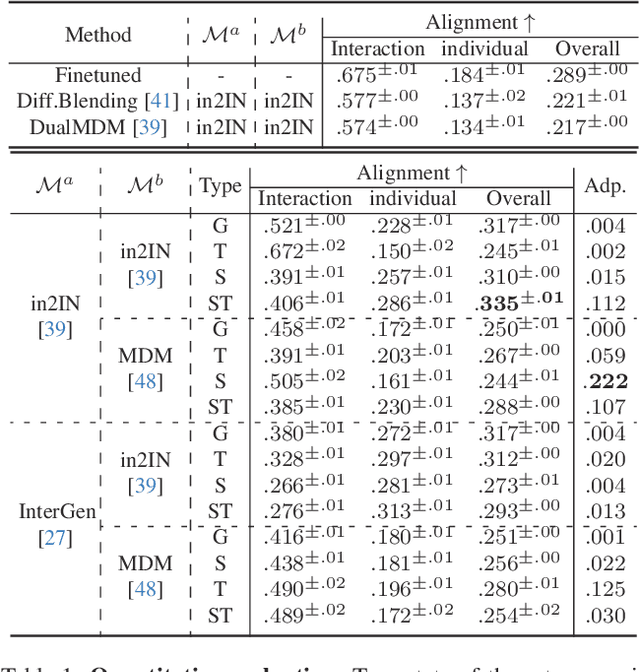
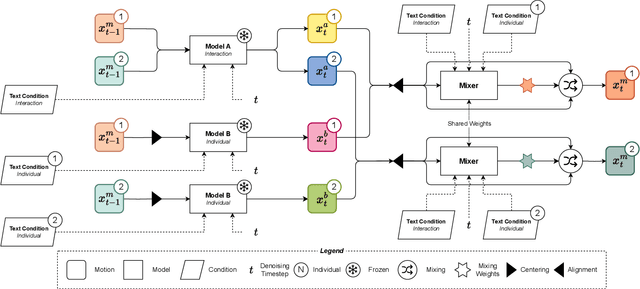
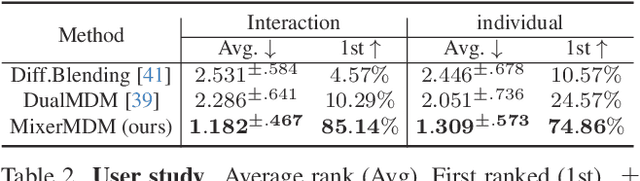
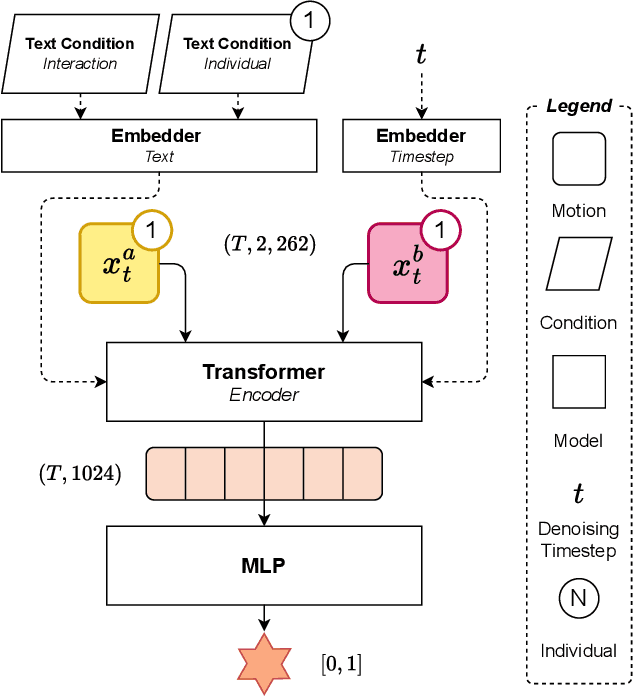
Generating human motion guided by conditions such as textual descriptions is challenging due to the need for datasets with pairs of high-quality motion and their corresponding conditions. The difficulty increases when aiming for finer control in the generation. To that end, prior works have proposed to combine several motion diffusion models pre-trained on datasets with different types of conditions, thus allowing control with multiple conditions. However, the proposed merging strategies overlook that the optimal way to combine the generation processes might depend on the particularities of each pre-trained generative model and also the specific textual descriptions. In this context, we introduce MixerMDM, the first learnable model composition technique for combining pre-trained text-conditioned human motion diffusion models. Unlike previous approaches, MixerMDM provides a dynamic mixing strategy that is trained in an adversarial fashion to learn to combine the denoising process of each model depending on the set of conditions driving the generation. By using MixerMDM to combine single- and multi-person motion diffusion models, we achieve fine-grained control on the dynamics of every person individually, and also on the overall interaction. Furthermore, we propose a new evaluation technique that, for the first time in this task, measures the interaction and individual quality by computing the alignment between the mixed generated motions and their conditions as well as the capabilities of MixerMDM to adapt the mixing throughout the denoising process depending on the motions to mix.
Challenges for Monocular 6D Object Pose Estimation in Robotics
Jul 22, 2023



Object pose estimation is a core perception task that enables, for example, object grasping and scene understanding. The widely available, inexpensive and high-resolution RGB sensors and CNNs that allow for fast inference based on this modality make monocular approaches especially well suited for robotics applications. We observe that previous surveys on object pose estimation establish the state of the art for varying modalities, single- and multi-view settings, and datasets and metrics that consider a multitude of applications. We argue, however, that those works' broad scope hinders the identification of open challenges that are specific to monocular approaches and the derivation of promising future challenges for their application in robotics. By providing a unified view on recent publications from both robotics and computer vision, we find that occlusion handling, novel pose representations, and formalizing and improving category-level pose estimation are still fundamental challenges that are highly relevant for robotics. Moreover, to further improve robotic performance, large object sets, novel objects, refractive materials, and uncertainty estimates are central, largely unsolved open challenges. In order to address them, ontological reasoning, deformability handling, scene-level reasoning, realistic datasets, and the ecological footprint of algorithms need to be improved.