 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models
Dec 22, 2025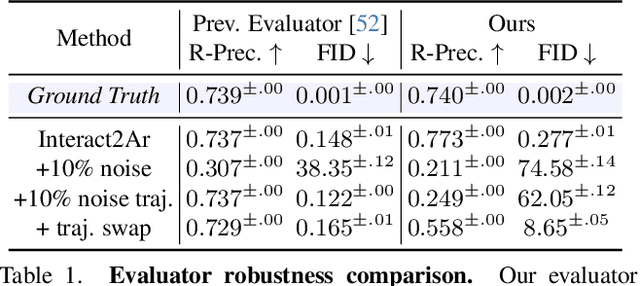
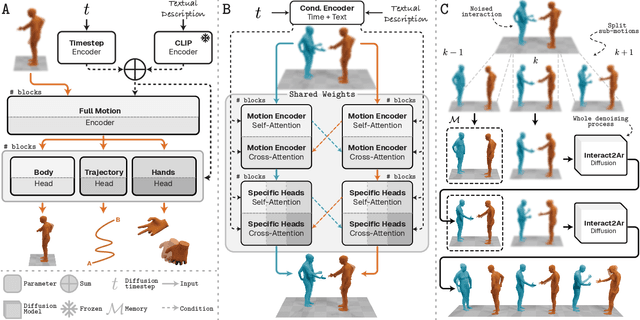
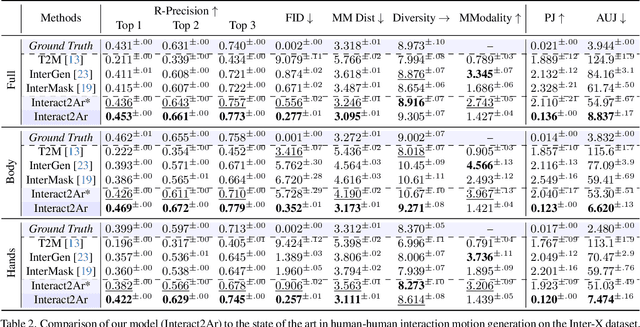
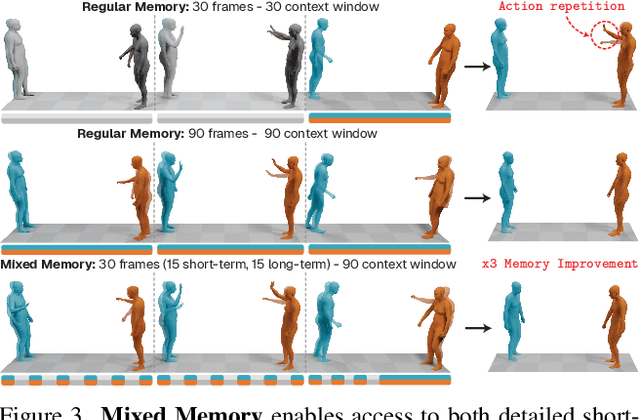
Generating realistic human-human interactions is a challenging task that requires not only high-quality individual body and hand motions, but also coherent coordination among all interactants. Due to limitations in available data and increased learning complexity, previous methods tend to ignore hand motions, limiting the realism and expressivity of the interactions. Additionally, current diffusion-based approaches generate entire motion sequences simultaneously, limiting their ability to capture the reactive and adaptive nature of human interactions. To address these limitations, we introduce Interact2Ar, the first end-to-end text-conditioned autoregressive diffusion model for generating full-body, human-human interactions. Interact2Ar incorporates detailed hand kinematics through dedicated parallel branches, enabling high-fidelity full-body generation. Furthermore, we introduce an autoregressive pipeline coupled with a novel memory technique that facilitates adaptation to the inherent variability of human interactions using efficient large context windows. The adaptability of our model enables a series of downstream applications, including temporal motion composition, real-time adaptation to disturbances, and extension beyond dyadic to multi-person scenarios. To validate the generated motions, we introduce a set of robust evaluators and extended metrics designed specifically for assessing full-body interactions. Through quantitative and qualitative experiments, we demonstrate the state-of-the-art performance of Interact2Ar.
MixerMDM: Learnable Composition of Human Motion Diffusion Models
Apr 01, 2025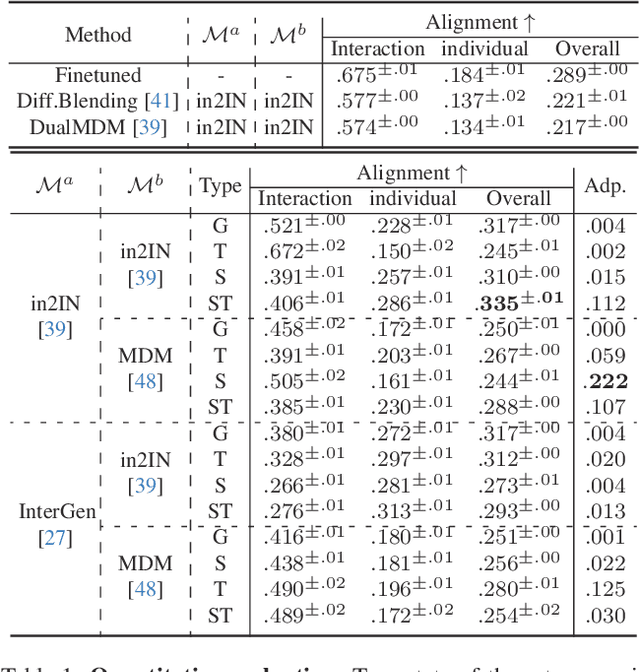
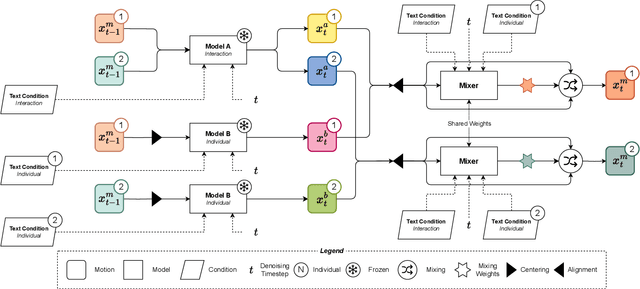
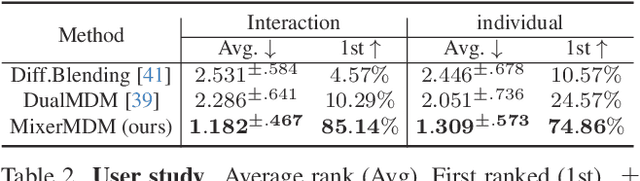
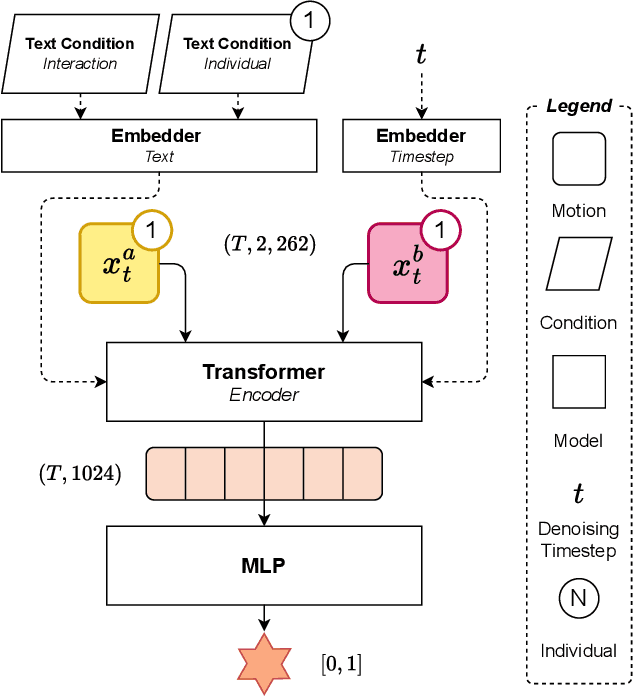
Generating human motion guided by conditions such as textual descriptions is challenging due to the need for datasets with pairs of high-quality motion and their corresponding conditions. The difficulty increases when aiming for finer control in the generation. To that end, prior works have proposed to combine several motion diffusion models pre-trained on datasets with different types of conditions, thus allowing control with multiple conditions. However, the proposed merging strategies overlook that the optimal way to combine the generation processes might depend on the particularities of each pre-trained generative model and also the specific textual descriptions. In this context, we introduce MixerMDM, the first learnable model composition technique for combining pre-trained text-conditioned human motion diffusion models. Unlike previous approaches, MixerMDM provides a dynamic mixing strategy that is trained in an adversarial fashion to learn to combine the denoising process of each model depending on the set of conditions driving the generation. By using MixerMDM to combine single- and multi-person motion diffusion models, we achieve fine-grained control on the dynamics of every person individually, and also on the overall interaction. Furthermore, we propose a new evaluation technique that, for the first time in this task, measures the interaction and individual quality by computing the alignment between the mixed generated motions and their conditions as well as the capabilities of MixerMDM to adapt the mixing throughout the denoising process depending on the motions to mix.
Visual WetlandBirds Dataset: Bird Species Identification and Behavior Recognition in Videos
Jan 15, 2025



The current biodiversity loss crisis makes animal monitoring a relevant field of study. In light of this, data collected through monitoring can provide essential insights, and information for decision-making aimed at preserving global biodiversity. Despite the importance of such data, there is a notable scarcity of datasets featuring videos of birds, and none of the existing datasets offer detailed annotations of bird behaviors in video format. In response to this gap, our study introduces the first fine-grained video dataset specifically designed for bird behavior detection and species classification. This dataset addresses the need for comprehensive bird video datasets and provides detailed data on bird actions, facilitating the development of deep learning models to recognize these, similar to the advancements made in human action recognition. The proposed dataset comprises 178 videos recorded in Spanish wetlands, capturing 13 different bird species performing 7 distinct behavior classes. In addition, we also present baseline results using state of the art models on two tasks: bird behavior recognition and species classification.