 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual WetlandBirds Dataset: Bird Species Identification and Behavior Recognition in Videos
Jan 15, 2025



The current biodiversity loss crisis makes animal monitoring a relevant field of study. In light of this, data collected through monitoring can provide essential insights, and information for decision-making aimed at preserving global biodiversity. Despite the importance of such data, there is a notable scarcity of datasets featuring videos of birds, and none of the existing datasets offer detailed annotations of bird behaviors in video format. In response to this gap, our study introduces the first fine-grained video dataset specifically designed for bird behavior detection and species classification. This dataset addresses the need for comprehensive bird video datasets and provides detailed data on bird actions, facilitating the development of deep learning models to recognize these, similar to the advancements made in human action recognition. The proposed dataset comprises 178 videos recorded in Spanish wetlands, capturing 13 different bird species performing 7 distinct behavior classes. In addition, we also present baseline results using state of the art models on two tasks: bird behavior recognition and species classification.
Detecting Facial Image Manipulations with Multi-Layer CNN Models
Dec 09, 2024



The rapid evolution of digital image manipulation techniques poses significant challenges for content verification, with models such as stable diffusion and mid-journey producing highly realistic, yet synthetic, images that can deceive human perception. This research develops and evaluates convolutional neural networks (CNNs) specifically tailored for the detection of these manipulated images. The study implements a comparative analysis of three progressively complex CNN architectures, assessing their ability to classify and localize manipulations across various facial image modifications. Regularization and optimization techniques were systematically incorporated to improve feature extraction and performance. The results indicate that the proposed models achieve an accuracy of up to 76\% in distinguishing manipulated images from genuine ones, surpassing traditional approaches. This research not only highlights the potential of CNNs in enhancing the robustness of digital media verification tools, but also provides insights into effective architectural adaptations and training strategies for low-computation environments. Future work will build on these findings by extending the architectures to handle more diverse manipulation techniques and integrating multi-modal data for improved detection capabilities.
Enhancing Action Recognition by Leveraging the Hierarchical Structure of Actions and Textual Context
Oct 28, 2024



The sequential execution of actions and their hierarchical structure consisting of different levels of abstraction, provide features that remain unexplored in the task of action recognition. In this study, we present a novel approach to improve action recognition by exploiting the hierarchical organization of actions and by incorporating contextualized textual information, including location and prior actions to reflect the sequential context. To achieve this goal, we introduce a novel transformer architecture tailored for action recognition that utilizes both visual and textual features. Visual features are obtained from RGB and optical flow data, while text embeddings represent contextual information. Furthermore, we define a joint loss function to simultaneously train the model for both coarse and fine-grained action recognition, thereby exploiting the hierarchical nature of actions. To demonstrate the effectiveness of our method, we extend the Toyota Smarthome Untrimmed (TSU) dataset to introduce action hierarchies, introducing the Hierarchical TSU dataset. We also conduct an ablation study to assess the impact of different methods for integrating contextual and hierarchical data on action recognition performance. Results show that the proposed approach outperforms pre-trained SOTA methods when trained with the same hyperparameters. Moreover, they also show a 17.12% improvement in top-1 accuracy over the equivalent fine-grained RGB version when using ground-truth contextual information, and a 5.33% improvement when contextual information is obtained from actual predictions.
Deep Insights into Cognitive Decline: A Survey of Leveraging Non-Intrusive Modalities with Deep Learning Techniques
Oct 24, 2024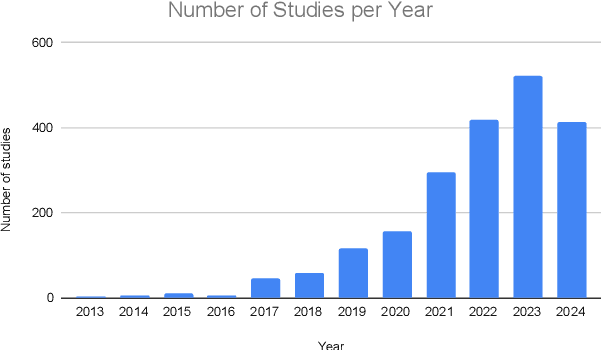
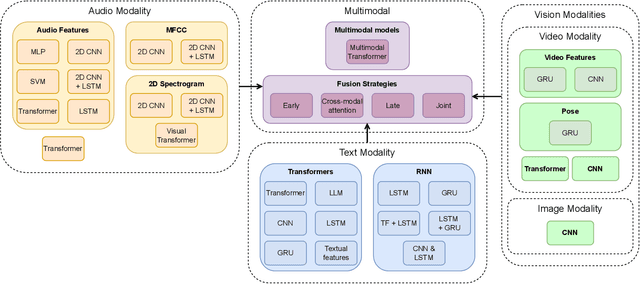
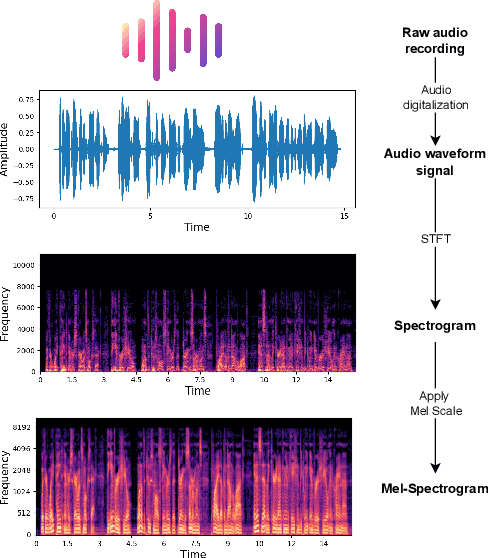
Cognitive decline is a natural part of aging, often resulting in reduced cognitive abilities. In some cases, however, this decline is more pronounced, typically due to disorders such as Alzheimer's disease. Early detection of anomalous cognitive decline is crucial, as it can facilitate timely professional intervention. While medical data can help in this detection, it often involves invasive procedures. An alternative approach is to employ non-intrusive techniques such as speech or handwriting analysis, which do not necessarily affect daily activities. This survey reviews the most relevant methodologies that use deep learning techniques to automate the cognitive decline estimation task, including audio, text, and visual processing. We discuss the key features and advantages of each modality and methodology, including state-of-the-art approaches like Transformer architecture and foundation models. In addition, we present works that integrate different modalities to develop multimodal models. We also highlight the most significant datasets and the quantitative results from studies using these resources. From this review, several conclusions emerge. In most cases, the textual modality achieves the best results and is the most relevant for detecting cognitive decline. Moreover, combining various approaches from individual modalities into a multimodal model consistently enhances performance across nearly all scenarios.
Cognitive Insights Across Languages: Enhancing Multimodal Interview Analysis
Jun 11, 2024Cognitive decline is a natural process that occurs as individuals age. Early diagnosis of anomalous decline is crucial for initiating professional treatment that can enhance the quality of life of those affected. To address this issue, we propose a multimodal model capable of predicting Mild Cognitive Impairment and cognitive scores. The TAUKADIAL dataset is used to conduct the evaluation, which comprises audio recordings of clinical interviews. The proposed model demonstrates the ability to transcribe and differentiate between languages used in the interviews. Subsequently, the model extracts audio and text features, combining them into a multimodal architecture to achieve robust and generalized results. Our approach involves in-depth research to implement various features obtained from the proposed modalities.